 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINS: Efficient and Robust Multisensor-aided Inertial Navigation System
Sep 27, 2023Robust multisensor fusion of multi-modal measurements such as IMUs, wheel encoders, cameras, LiDARs, and GPS holds great potential due to its innate ability to improve resilience to sensor failures and measurement outliers, thereby enabling robust autonomy. To the best of our knowledge, this work is among the first to develop a consistent tightly-coupled Multisensor-aided Inertial Navigation System (MINS) that is capable of fusing the most common navigation sensors in an efficient filtering framework, by addressing the particular challenges of computational complexity, sensor asynchronicity, and intra-sensor calibration. In particular, we propose a consistent high-order on-manifold interpolation scheme to enable efficient asynchronous sensor fusion and state management strategy (i.e. dynamic cloning). The proposed dynamic cloning leverages motion-induced information to adaptively select interpolation orders to control computational complexity while minimizing trajectory representation errors. We perform online intrinsic and extrinsic (spatiotemporal) calibration of all onboard sensors to compensate for poor prior calibration and/or degraded calibration varying over time. Additionally, we develop an initialization method with only proprioceptive measurements of IMU and wheel encoders, instead of exteroceptive sensors, which is shown to be less affected by the environment and more robust in highly dynamic scenarios. We extensively validate the proposed MINS in simulations and large-scale challenging real-world datasets, outperforming the existing state-of-the-art methods, in terms of localization accuracy, consistency, and computation efficiency. We have also open-sourced our algorithm, simulator, and evaluation toolbox for the benefit of the community: https://github.com/rpng/mins.
NeRF-VINS: A Real-time Neural Radiance Field Map-based Visual-Inertial Navigation System
Sep 17, 2023



Achieving accurate, efficient, and consistent localization within an a priori environment map remains a fundamental challenge in robotics and computer vision. Conventional map-based keyframe localization often suffers from sub-optimal viewpoints due to limited field of view (FOV), thus degrading its performance. To address this issue, in this paper, we design a real-time tightly-coupled Neural Radiance Fields (NeRF)-aided visual-inertial navigation system (VINS), termed NeRF-VINS. By effectively leveraging NeRF's potential to synthesize novel views, essential for addressing limited viewpoints, the proposed NeRF-VINS optimally fuses IMU and monocular image measurements along with synthetically rendered images within an efficient filter-based framework. This tightly coupled integration enables 3D motion tracking with bounded error. We extensively compare the proposed NeRF-VINS against the state-of-the-art methods that use prior map information, which is shown to achieve superior performance. We also demonstrate the proposed method is able to perform real-time estimation at 15 Hz, on a resource-constrained Jetson AGX Orin embedded platform with impressive accuracy.
Multi-Visual-Inertial System: Analysis, Calibration and Estimation
Aug 18, 2023In this paper, we study state estimation of multi-visual-inertial systems (MVIS) and develop sensor fusion algorithms to optimally fuse an arbitrary number of asynchronous inertial measurement units (IMUs) or gyroscopes and global and(or) rolling shutter cameras. We are especially interested in the full calibration of the associated visual-inertial sensors, including the IMU or camera intrinsics and the IMU-IMU(or camera) spatiotemporal extrinsics as well as the image readout time of rolling-shutter cameras (if used). To this end, we develop a new analytic combined IMU integration with intrinsics-termed ACI3-to preintegrate IMU measurements, which is leveraged to fuse auxiliary IMUs and(or) gyroscopes alongside a base IMU. We model the multi-inertial measurements to include all the necessary inertial intrinsic and IMU-IMU spatiotemporal extrinsic parameters, while leveraging IMU-IMU rigid-body constraints to eliminate the necessity of auxiliary inertial poses and thus reducing computational complexity. By performing observability analysis of MVIS, we prove that the standard four unobservable directions remain - no matter how many inertial sensors are used, and also identify, for the first time, degenerate motions for IMU-IMU spatiotemporal extrinsics and auxiliary inertial intrinsics. In addition to the extensive simulations that validate our analysis and algorithms, we have built our own MVIS sensor rig and collected over 25 real-world datasets to experimentally verify the proposed calibration against the state-of-the-art calibration method such as Kalibr. We show that the proposed MVIS calibration is able to achieve competing accuracy with improved convergence and repeatability, which is open sourced to better benefit the community.
Online Self-Calibration for Visual-Inertial Navigation Systems: Models, Analysis and Degeneracy
Jan 29, 2022


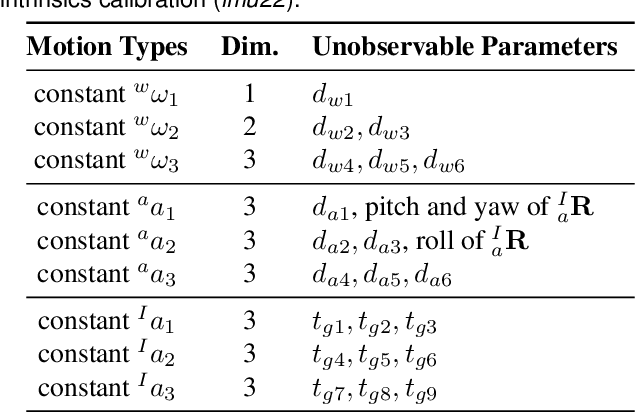
In this paper, we study in-depth the problem of online self-calibration for robust and accurate visual-inertial state estimation. In particular, we first perform a complete observability analysis for visual-inertial navigation systems (VINS) with full calibration of sensing parameters, including IMU and camera intrinsics and IMU-camera spatial-temporal extrinsic calibration, along with readout time of rolling shutter (RS) cameras (if used). We investigate different inertial model variants containing IMU intrinsic parameters that encompass most commonly used models for low-cost inertial sensors. The observability analysis results prove that VINS with full sensor calibration has four unobservable directions, corresponding to the system's global yaw and translation, while all sensor calibration parameters are observable given fully-excited 6-axis motion. Moreover, we, for the first time, identify primitive degenerate motions for IMU and camera intrinsic calibration. Each degenerate motion profile will cause a set of calibration parameters to be unobservable and any combination of these degenerate motions are still degenerate. Extensive Monte-Carlo simulations and real-world experiments are performed to validate both the observability analysis and identified degenerate motions, showing that online self-calibration improves system accuracy and robustness to calibration inaccuracies. We compare the proposed online self-calibration on commonly-used IMUs against the state-of-art offline calibration toolbox Kalibr, and show that the proposed system achieves better consistency and repeatability. Based on our analysis and experimental evaluations, we also provide practical guidelines for how to perform online IMU-camera sensor self-calibration.
Distributed Visual-Inertial Cooperative Localization
Mar 23, 2021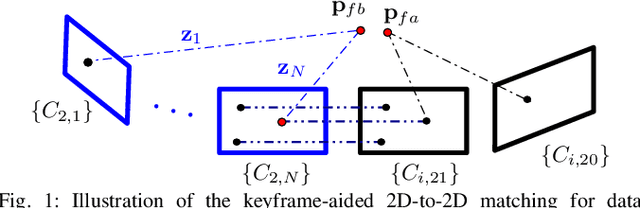
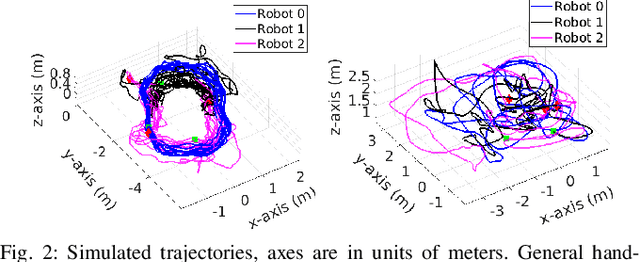
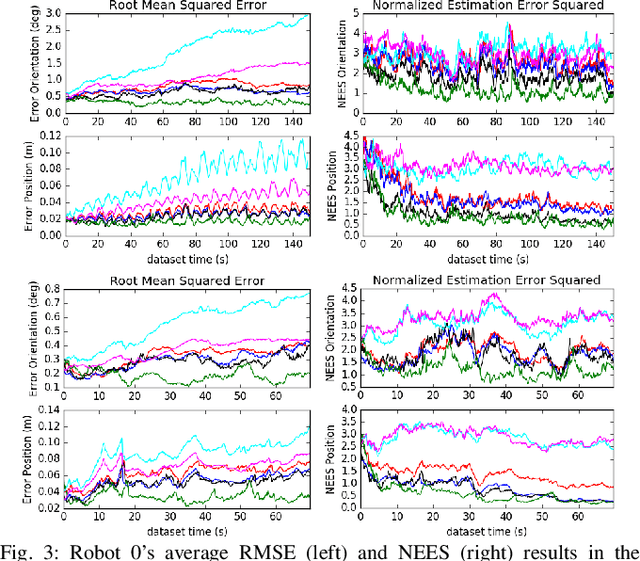
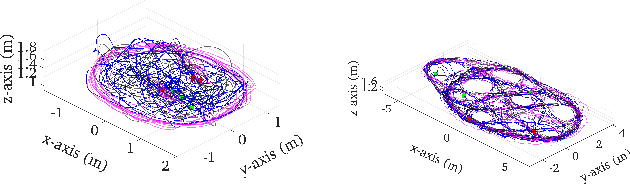
In this paper we present a consistent and distributed state estimator for multi-robot cooperative localization (CL) which efficiently fuses environmental features and loop-closure constraints across time and robots. In particular, we leverage covariance intersection (CI) to allow each robot to only track its own state and autocovariance and compensate for the unknown correlations between robots. Two novel different methods for utilizing common environmental temporal SLAM features are introduced and evaluated in terms of accuracy and efficiency. Moreover, we adapt CI to enable drift-free estimation through the use of loop-closure measurement constraints to other robots' historical poses without a significant increase in computational cost. The proposed distributed CL estimator is validated against its naive non-realtime centralized counterpart extensively in both simulations and real-world experiments.
LIC-Fusion 2.0: LiDAR-Inertial-Camera Odometry with Sliding-Window Plane-Feature Tracking
Aug 17, 2020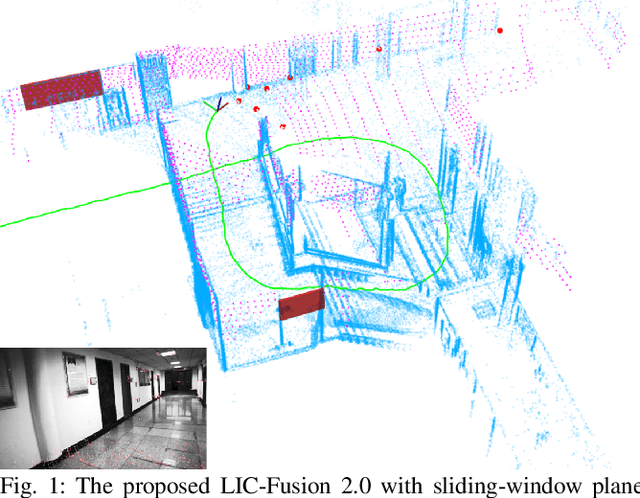
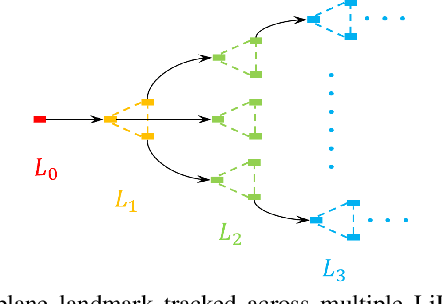


Multi-sensor fusion of multi-modal measurements from commodity inertial, visual and LiDAR sensors to provide robust and accurate 6DOF pose estimation holds great potential in robotics and beyond. In this paper, building upon our prior work (i.e., LIC-Fusion), we develop a sliding-window filter based LiDAR-Inertial-Camera odometry with online spatiotemporal calibration (i.e., LIC-Fusion 2.0), which introduces a novel sliding-window plane-feature tracking for efficiently processing 3D LiDAR point clouds. In particular, after motion compensation for LiDAR points by leveraging IMU data, low-curvature planar points are extracted and tracked across the sliding window. A novel outlier rejection criterion is proposed in the plane-feature tracking for high-quality data association. Only the tracked planar points belonging to the same plane will be used for plane initialization, which makes the plane extraction efficient and robust. Moreover, we perform the observability analysis for the LiDAR-IMU subsystem and report the degenerate cases for spatiotemporal calibration using plane features. While the estimation consistency and identified degenerate motions are validated in Monte-Carlo simulations, different real-world experiments are also conducted to show that the proposed LIC-Fusion 2.0 outperforms its predecessor and other state-of-the-art methods.
MIMC-VINS: A Versatile and Resilient Multi-IMU Multi-Camera Visual-Inertial Navigation System
Jun 28, 2020
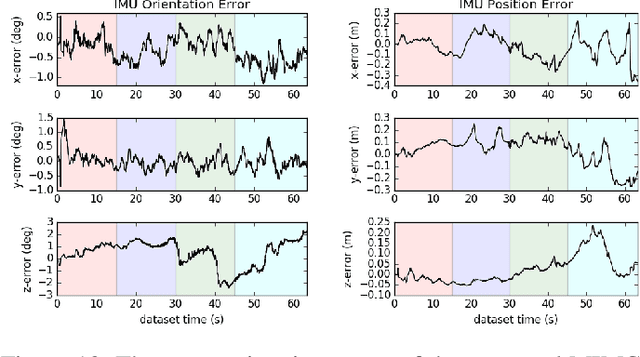
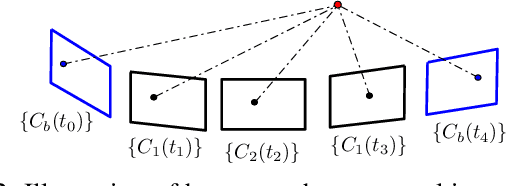
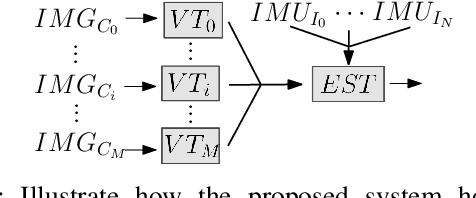
As cameras and inertial sensors are becoming ubiquitous in mobile devices and robots, it holds great potential to design visual-inertial navigation systems (VINS) for efficient versatile 3D motion tracking which utilize any (multiple) available cameras and inertial measurement units (IMUs) and are resilient to sensor failures or measurement depletion. To this end, rather than the standard VINS paradigm using a minimal sensing suite of a single camera and IMU, in this paper we design a real-time consistent multi-IMU multi-camera (MIMC)-VINS estimator that is able to seamlessly fuse multi-modal information from an arbitrary number of uncalibrated cameras and IMUs. Within an efficient multi-state constraint Kalman filter (MSCKF) framework, the proposed MIMC-VINS algorithm optimally fuses asynchronous measurements from all sensors, while providing smooth, uninterrupted, and accurate 3D motion tracking even if some sensors fail. The key idea of the proposed MIMC-VINS is to perform high-order on-manifold state interpolation to efficiently process all available visual measurements without increasing the computational burden due to estimating additional sensors' poses at asynchronous imaging times. In order to fuse the information from multiple IMUs, we propagate a joint system consisting of all IMU states while enforcing rigid-body constraints between the IMUs during the filter update stage. Lastly, we estimate online both spatiotemporal extrinsic and visual intrinsic parameters to make our system robust to errors in prior sensor calibration. The proposed system is extensively validated in both Monte-Carlo simulations and real-world experiments.
LIC-Fusion: LiDAR-Inertial-Camera Odometry
Sep 09, 2019

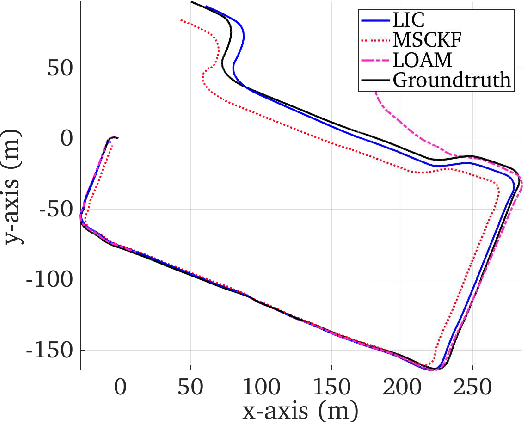

This paper presents a tightly-coupled multi-sensor fusion algorithm termed LiDAR-inertial-camera fusion (LIC-Fusion), which efficiently fuses IMU measurements, sparse visual features, and extracted LiDAR points. In particular, the proposed LIC-Fusion performs online spatial and temporal sensor calibration between all three asynchronous sensors, in order to compensate for possible calibration variations. The key contribution is the optimal (up to linearization errors) multi-modal sensor fusion of detected and tracked sparse edge/surf feature points from LiDAR scans within an efficient MSCKF-based framework, alongside sparse visual feature observations and IMU readings. We perform extensive experiments in both indoor and outdoor environments, showing that the proposed LIC-Fusion outperforms the state-of-the-art visual-inertial odometry (VIO) and LiDAR odometry methods in terms of estimation accuracy and robustness to aggressive motions.
An Efficient Schmidt-EKF for 3D Visual-Inertial SLAM
Mar 20, 2019



It holds great implications for practical applications to enable centimeter-accuracy positioning for mobile and wearable sensor systems. In this paper, we propose a novel, high-precision, efficient visual-inertial (VI)-SLAM algorithm, termed Schmidt-EKF VI-SLAM (SEVIS), which optimally fuses IMU measurements and monocular images in a tightly-coupled manner to provide 3D motion tracking with bounded error. In particular, we adapt the Schmidt Kalman filter formulation to selectively include informative features in the state vector while treating them as nuisance parameters (or Schmidt states) once they become matured. This change in modeling allows for significant computational savings by no longer needing to constantly update the Schmidt states (or their covariance), while still allowing the EKF to correctly account for their cross-correlations with the active states. As a result, we achieve linear computational complexity in terms of map size, instead of quadratic as in the standard SLAM systems. In order to fully exploit the map information to bound navigation drifts, we advocate efficient keyframe-aided 2D-to-2D feature matching to find reliable correspondences between current 2D visual measurements and 3D map features. The proposed SEVIS is extensively validated in both simulations and experiments.
* Accepted to the 2019 Conference on Computer Vision and Pattern Recognition (CVPR)
Closed-form Preintegration Methods for Graph-based Visual-Inertial Navigation
Mar 20, 2019

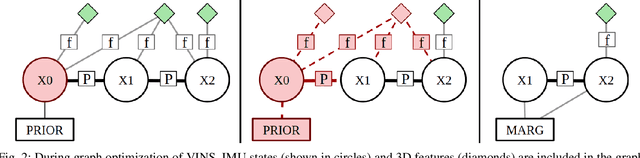

In this paper we propose a new analytical preintegration theory for graph-based sensor fusion with an inertial measurement unit (IMU) and a camera (or other aiding sensors).Rather than using discrete sampling of the measurement dynamics as in current methods,we derive the closed-form solutions to the preintegration equations, yielding improved accuracy in state estimation.We advocate two new different inertial models for preintegration: (i) the model that assumes piecewise constant measurements, and (ii) the model that assumes piecewise constant local true acceleration.We show through extensive Monte-Carlo simulations the effect that the choice of preintegration model has on estimation performance.To validate the proposed preintegration theory, we develop both direct and indirect visual-inertial navigation systems (VINS) that leverage our preintegration.In the first, within a tightly-coupled, sliding-window optimization framework, we jointly estimate the features in the window and the IMU states while performing marginalization to bound the computational cost.In the second, we loosely-couple the IMU preintegration with a direct image alignment that estimates relative camera motion by minimizing the photometric errors (i.e., image intensity difference), allowing for efficient and informative loop closures. Both systems are extensively validated in real-world experiments and are shown to offer competitive performance to state-of-the-art methods.