 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDF-Net: Structure-Aware Disentangled Feature Learning for Opticall-SAR Ship Re-identification
Mar 13, 2026Cross-modal ship re-identification (ReID) between optical and synthetic aperture radar (SAR) imagery is fundamentally challenged by the severe radiometric discrepancy between passive optical imaging and coherent active radar sensing. While existing approaches primarily rely on statistical distribution alignment or semantic matching, they often overlook a critical physical prior: ships are rigid objects whose geometric structures remain stable across sensing modalities, whereas texture appearance is highly modality-dependent. In this work, we propose SDF-Net, a Structure-Aware Disentangled Feature Learning Network that systematically incorporates geometric consistency into optical--SAR ship ReID. Built upon a ViT backbone, SDF-Net introduces a structure consistency constraint that extracts scale-invariant gradient energy statistics from intermediate layers to robustly anchor representations against radiometric variations. At the terminal stage, SDF-Net disentangles the learned representations into modality-invariant identity features and modality-specific characteristics. These decoupled cues are then integrated through a parameter-free additive residual fusion, effectively enhancing discriminative power. Extensive experiments on the HOSS-ReID dataset demonstrate that SDF-Net consistently outperforms existing state-of-the-art methods. The code and trained models are publicly available at https://github.com/cfrfree/SDF-Net.
Fluxamba: Topology-Aware Anisotropic State Space Models for Geological Lineament Segmentation in Multi-Source Remote Sensing
Jan 24, 2026The precise segmentation of geological linear features, spanning from planetary lineaments to terrestrial fractures, demands capturing long-range dependencies across complex anisotropic topologies. Although State Space Models (SSMs) offer near-linear computational complexity, their dependence on rigid, axis-aligned scanning trajectories induces a fundamental topological mismatch with curvilinear targets, resulting in fragmented context and feature erosion. To bridge this gap, we propose Fluxamba, a lightweight architecture that introduces a topology-aware feature rectification framework. Central to our design is the Structural Flux Block (SFB), which orchestrates an anisotropic information flux by integrating an Anisotropic Structural Gate (ASG) with a Prior-Modulated Flow (PMF). This mechanism decouples feature orientation from spatial location, dynamically gating context aggregation along the target's intrinsic geometry rather than rigid paths. Furthermore, to mitigate serialization-induced noise in low-contrast environments, we incorporate a Hierarchical Spatial Regulator (HSR) for multi-scale semantic alignment and a High-Fidelity Focus Unit (HFFU) to explicitly maximize the signal-to-noise ratio of faint features. Extensive experiments on diverse geological benchmarks (LROC-Lineament, LineaMapper, and GeoCrack) demonstrate that Fluxamba establishes a new state-of-the-art. Notably, on the challenging LROC-Lineament dataset, it achieves an F1-score of 89.22% and mIoU of 89.87%. Achieving a real-time inference speed of over 24 FPS with only 3.4M parameters and 6.3G FLOPs, Fluxamba reduces computational costs by up to two orders of magnitude compared to heavy-weight baselines, thereby establishing a new Pareto frontier between segmentation fidelity and onboard deployment feasibility.
ABFL: Angular Boundary Discontinuity Free Loss for Arbitrary Oriented Object Detection in Aerial Images
Nov 21, 2023



Arbitrary oriented object detection (AOOD) in aerial images is a widely concerned and highly challenging task, and plays an important role in many scenarios. The core of AOOD involves the representation, encoding, and feature augmentation of oriented bounding-boxes (Bboxes). Existing methods lack intuitive modeling of angle difference measurement in oriented Bbox representations. Oriented Bboxes under different representations exhibit rotational symmetry with varying periods due to angle periodicity. The angular boundary discontinuity (ABD) problem at periodic boundary positions is caused by rotational symmetry in measuring angular differences. In addition, existing methods also use additional encoding-decoding structures for oriented Bboxes. In this paper, we design an angular boundary free loss (ABFL) based on the von Mises distribution. The ABFL aims to solve the ABD problem when detecting oriented objects. Specifically, ABFL proposes to treat angles as circular data rather than linear data when measuring angle differences, aiming to introduce angle periodicity to alleviate the ABD problem and improve the accuracy of angle difference measurement. In addition, ABFL provides a simple and effective solution for various periodic boundary discontinuities caused by rotational symmetry in AOOD tasks, as it does not require additional encoding-decoding structures for oriented Bboxes. Extensive experiments on the DOTA and HRSC2016 datasets show that the proposed ABFL loss outperforms some state-of-the-art methods focused on addressing the ABD problem.
LUAI Challenge 2021 on Learning to Understand Aerial Images
Aug 30, 2021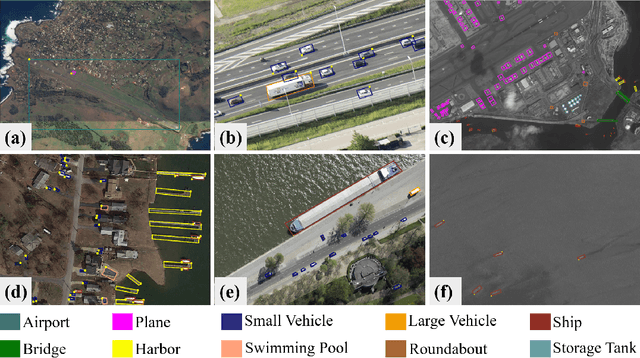

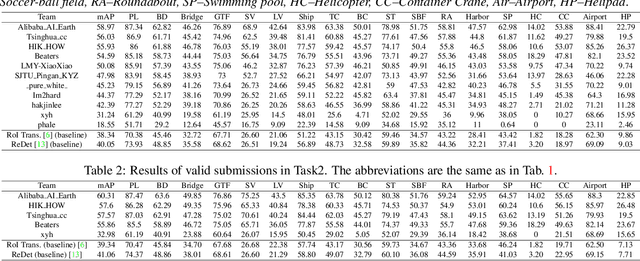
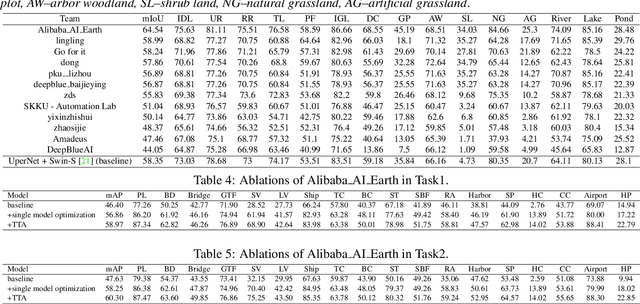
This report summarizes the results of Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV 2021, which focuses on object detection and semantic segmentation in aerial images. Using DOTA-v2.0 and GID-15 datasets, this challenge proposes three tasks for oriented object detection, horizontal object detection, and semantic segmentation of common categories in aerial images. This challenge received a total of 146 registrations on the three tasks. Through the challenge, we hope to draw attention from a wide range of communities and call for more efforts on the problems of learning to understand aerial images.
Planetary UAV localization based on Multi-modal Registration with Pre-existing Digital Terrain Model
Jun 24, 2021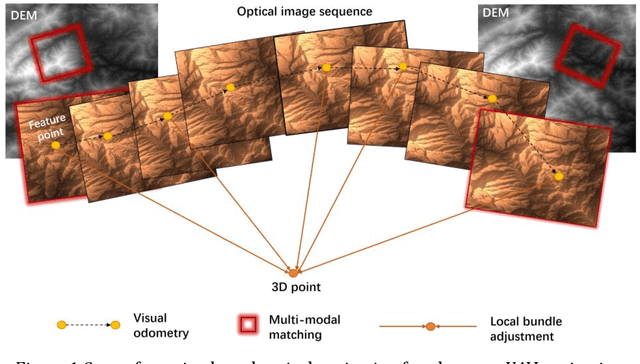



The autonomous real-time optical navigation of planetary UAV is of the key technologies to ensure the success of the exploration. In such a GPS denied environment, vision-based localization is an optimal approach. In this paper, we proposed a multi-modal registration based SLAM algorithm, which estimates the location of a planet UAV using a nadir view camera on the UAV compared with pre-existing digital terrain model. To overcome the scale and appearance difference between on-board UAV images and pre-installed digital terrain model, a theoretical model is proposed to prove that topographic features of UAV image and DEM can be correlated in frequency domain via cross power spectrum. To provide the six-DOF of the UAV, we also developed an optimization approach which fuses the geo-referencing result into a SLAM system via LBA (Local Bundle Adjustment) to achieve robust and accurate vision-based navigation even in featureless planetary areas. To test the robustness and effectiveness of the proposed localization algorithm, a new cross-source drone-based localization dataset for planetary exploration is proposed. The proposed dataset includes 40200 synthetic drone images taken from nine planetary scenes with related DEM query images. Comparison experiments carried out demonstrate that over the flight distance of 33.8km, the proposed method achieved average localization error of 0.45 meters, compared to 1.31 meters by ORB-SLAM, with the processing speed of 12hz which will ensure a real-time performance. We will make our datasets available to encourage further work on this promising topic.
DiRS: On Creating Benchmark Datasets for Remote Sensing Image Interpretation
Jun 22, 2020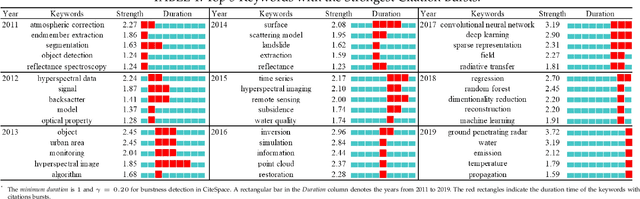

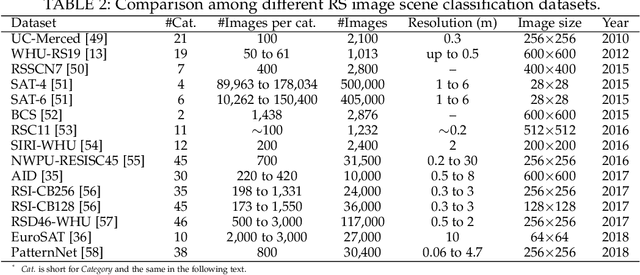
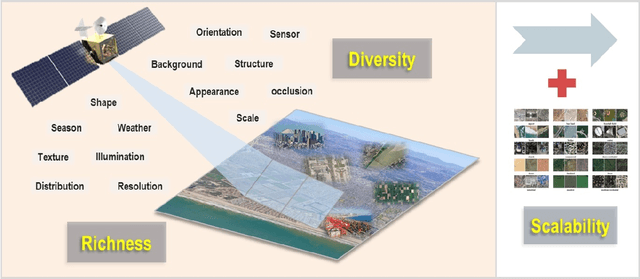
The past decade has witnessed great progress on remote sensing (RS) image interpretation and its wide applications. With RS images becoming more accessible than ever before, there is an increasing demand for the automatic interpretation of these images, where benchmark datasets are essential prerequisites for developing and testing intelligent interpretation algorithms. After reviewing existing benchmark datasets in the research community of RS image interpretation, this article discusses the problem of how to efficiently prepare a suitable benchmark dataset for RS image analysis. Specifically, we first analyze the current challenges of developing intelligent algorithms for RS image interpretation with bibliometric investigations. We then present some principles, i.e., diversity, richness, and scalability (called DiRS), on constructing benchmark datasets in efficient manners. Following the DiRS principles, we also provide an example on building datasets for RS image classification, i.e., Million-AID, a new large-scale benchmark dataset containing million instances for RS scene classification. Several challenges and perspectives in RS image annotation are finally discussed to facilitate the research in benchmark dataset construction. We do hope this paper will provide RS community an overall perspective on constructing large-scale and practical image datasets for further research, especially data-driven ones.
CNNTOP: a CNN-based Trajectory Owner Prediction Method
Jan 05, 2020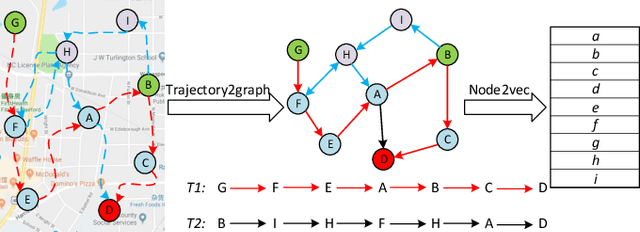
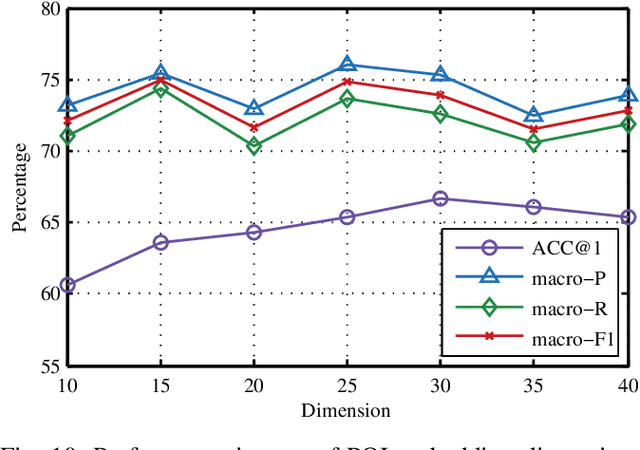
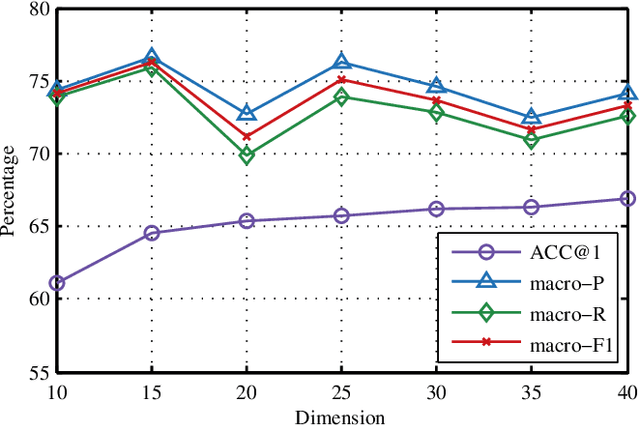
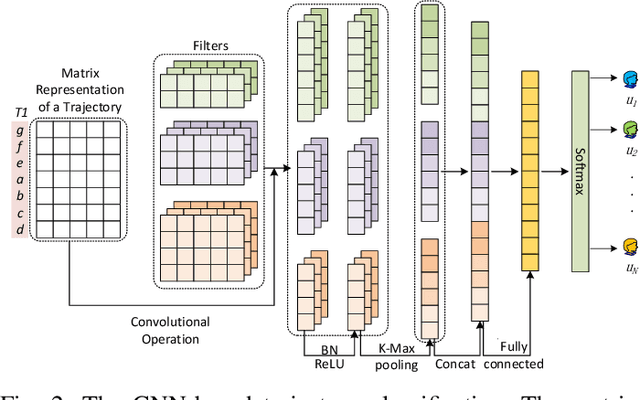
Trajectory owner prediction is the basis for many applications such as personalized recommendation, urban planning. Although much effort has been put on this topic, the results archived are still not good enough. Existing methods mainly employ RNNs to model trajectories semantically due to the inherent sequential attribute of trajectories. However, these approaches are weak at Point of Interest (POI) representation learning and trajectory feature detection. Thus, the performance of existing solutions is far from the requirements of practical applications. In this paper, we propose a novel CNN-based Trajectory Owner Prediction (CNNTOP) method. Firstly, we connect all POI according to trajectories from all users. The result is a connected graph that can be used to generate more informative POI sequences than other approaches. Secondly, we employ the Node2Vec algorithm to encode each POI into a low-dimensional real value vector. Then, we transform each trajectory into a fixed-dimensional matrix, which is similar to an image. Finally, a CNN is designed to detect features and predict the owner of a given trajectory. The CNN can extract informative features from the matrix representations of trajectories by convolutional operations, Batch normalization, and $K$-max pooling operations. Extensive experiments on real datasets demonstrate that CNNTOP substantially outperforms existing solutions in terms of macro-Precision, macro-Recall, macro-F1, and accuracy.
Learning Transferable Deep Models for Land-Use Classification with High-Resolution Remote Sensing Images
Jul 16, 2018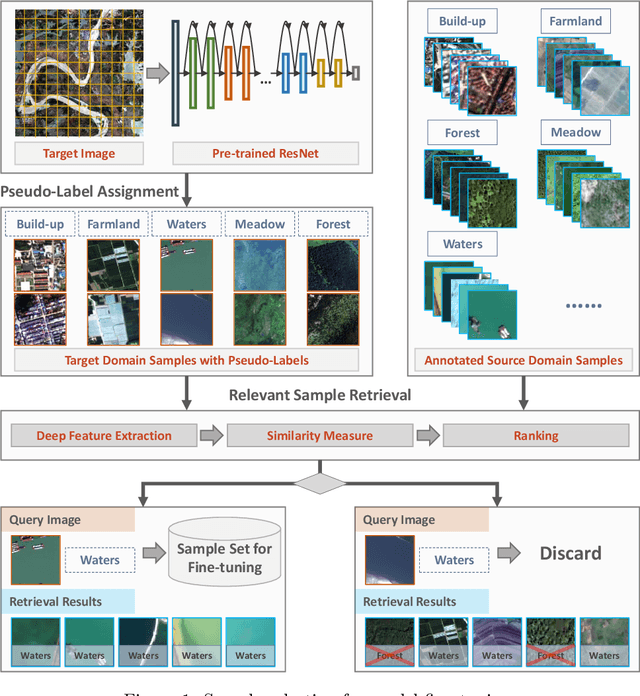
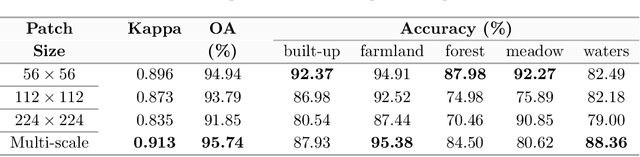
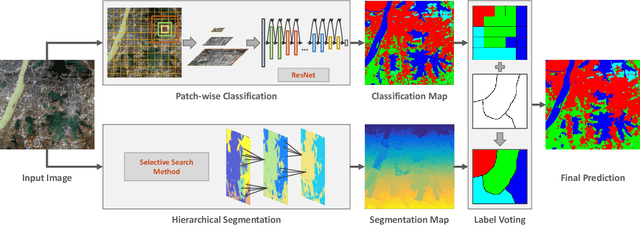
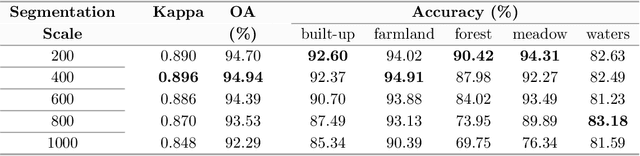
In recent years, large amount of high spatial-resolution remote sensing (HRRS) images are available for land-use mapping. However, due to the complex information brought by the increased spatial resolution and the data disturbances caused by different conditions of image acquisition, it is often difficult to find an efficient method for achieving accurate land-use classification with heterogeneous and high-resolution remote sensing images. In this paper, we propose a scheme to learn transferable deep models for land-use classification with HRRS images. The main idea is to rely on deep neural networks for presenting the semantic information contained in different types of land-uses and propose a pseudo-labeling and sample selection scheme for improving the transferability of deep models. More precisely, a deep Convolutional Neural Networks (CNNs) is first pre-trained with a well-annotated land-use dataset, referred to as the source data. Then, given a target image with no labels, the pre-trained CNN model is utilized to classify the image in a patch-wise manner. The patches with high classification probability are assigned with pseudo-labels and employed as the queries to retrieve related samples from the source data. The pseudo-labels confirmed with the retrieved results are regarded as supervised information for fine-tuning the pre-trained deep model. In order to obtain a pixel-wise land-use classification with the target image, we rely on the fine-tuned CNN and develop a hybrid classification by combining patch-wise classification and hierarchical segmentation. In addition, we create a large-scale land-use dataset containing $150$ Gaofen-2 satellite images for CNN pre-training. Experiments on multi-source HRRS images, including Gaofen-2, Gaofen-1, Jilin-1, Ziyuan-3, and Google Earth images, show encouraging results and demonstrate the efficiency of the proposed scheme.