 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning RoI Transformer for Detecting Oriented Objects in Aerial Images
Dec 01, 2018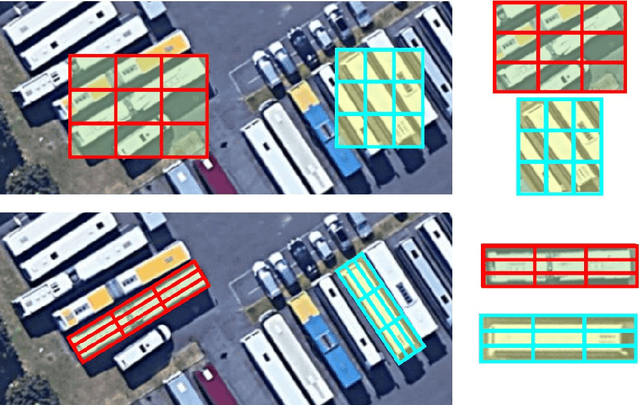

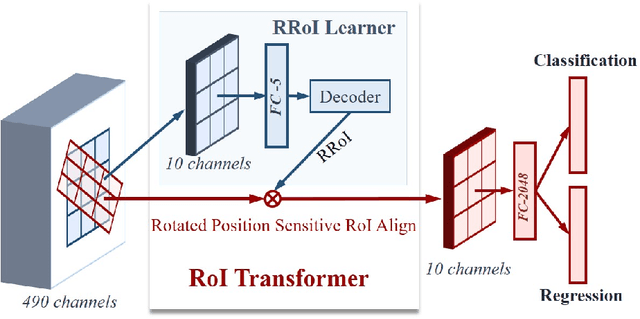
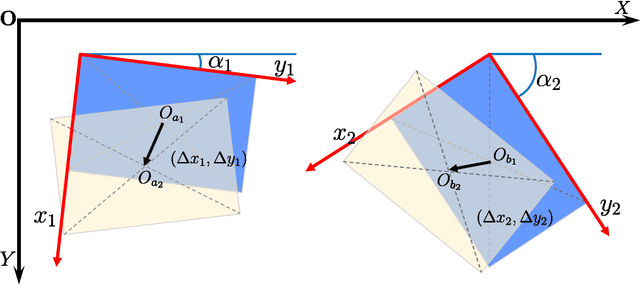
Object detection in aerial images is an active yet challenging task in computer vision because of the birdview perspective, the highly complex backgrounds, and the variant appearances of objects. Especially when detecting densely packed objects in aerial images, methods relying on horizontal proposals for common object detection often introduce mismatches between the Region of Interests (RoIs) and objects. This leads to the common misalignment between the final object classification confidence and localization accuracy. Although rotated anchors have been used to tackle this problem, the design of them always multiplies the number of anchors and dramatically increases the computational complexity. In this paper, we propose a RoI Transformer to address these problems. More precisely, to improve the quality of region proposals, we first designed a Rotated RoI (RRoI) learner to transform a Horizontal Region of Interest (HRoI) into a Rotated Region of Interest (RRoI). Based on the RRoIs, we then proposed a Rotated Position Sensitive RoI Align (RPS-RoI-Align) module to extract rotation-invariant features from them for boosting subsequent classification and regression. Our RoI Transformer is with light weight and can be easily embedded into detectors for oriented object detection. A simple implementation of the RoI Transformer has achieved state-of-the-art performances on two common and challenging aerial datasets, i.e., DOTA and HRSC2016, with a neglectable reduction to detection speed. Our RoI Transformer exceeds the deformable Position Sensitive RoI pooling when oriented bounding-box annotations are available. Extensive experiments have also validated the flexibility and effectiveness of our RoI Transformer. The results demonstrate that it can be easily integrated with other detector architectures and significantly improve the performances.
GeoSay: A Geometric Saliency for Extracting Buildings in Remote Sensing Images
Nov 07, 2018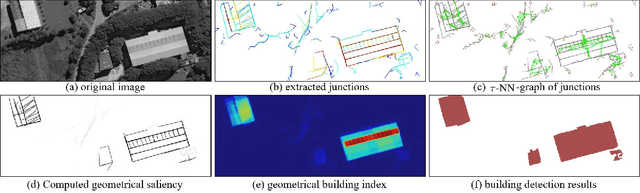


Automatic extraction of buildings in remote sensing images is an important but challenging task and finds many applications in different fields such as urban planning, navigation and so on. This paper addresses the problem of buildings extraction in very high-spatial-resolution (VHSR) remote sensing (RS) images, whose spatial resolution is often up to half meters and provides rich information about buildings. Based on the observation that buildings in VHSR-RS images are always more distinguishable in geometry than in texture or spectral domain, this paper proposes a geometric building index (GBI) for accurate building extraction, by computing the geometric saliency from VHSR-RS images. More precisely, given an image, the geometric saliency is derived from a mid-level geometric representations based on meaningful junctions that can locally describe geometrical structures of images. The resulting GBI is finally measured by integrating the derived geometric saliency of buildings. Experiments on three public and commonly used datasets demonstrate that the proposed GBI achieves the state-of-the-art performance and shows impressive generalization capability. Additionally, GBI preserves both the exact position and accurate shape of single buildings compared to existing methods.
Learning Transferable Deep Models for Land-Use Classification with High-Resolution Remote Sensing Images
Jul 16, 2018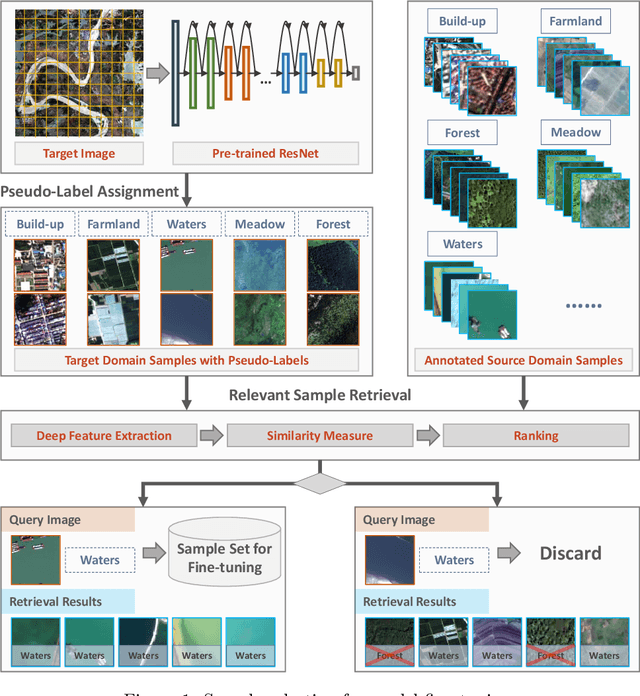
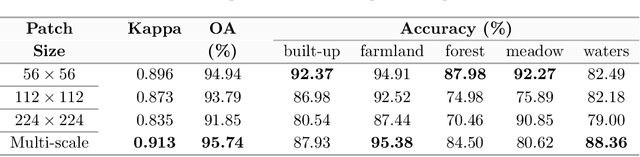
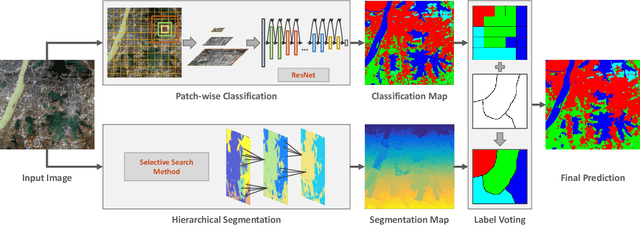
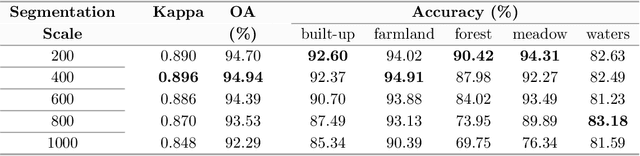
In recent years, large amount of high spatial-resolution remote sensing (HRRS) images are available for land-use mapping. However, due to the complex information brought by the increased spatial resolution and the data disturbances caused by different conditions of image acquisition, it is often difficult to find an efficient method for achieving accurate land-use classification with heterogeneous and high-resolution remote sensing images. In this paper, we propose a scheme to learn transferable deep models for land-use classification with HRRS images. The main idea is to rely on deep neural networks for presenting the semantic information contained in different types of land-uses and propose a pseudo-labeling and sample selection scheme for improving the transferability of deep models. More precisely, a deep Convolutional Neural Networks (CNNs) is first pre-trained with a well-annotated land-use dataset, referred to as the source data. Then, given a target image with no labels, the pre-trained CNN model is utilized to classify the image in a patch-wise manner. The patches with high classification probability are assigned with pseudo-labels and employed as the queries to retrieve related samples from the source data. The pseudo-labels confirmed with the retrieved results are regarded as supervised information for fine-tuning the pre-trained deep model. In order to obtain a pixel-wise land-use classification with the target image, we rely on the fine-tuned CNN and develop a hybrid classification by combining patch-wise classification and hierarchical segmentation. In addition, we create a large-scale land-use dataset containing $150$ Gaofen-2 satellite images for CNN pre-training. Experiments on multi-source HRRS images, including Gaofen-2, Gaofen-1, Jilin-1, Ziyuan-3, and Google Earth images, show encouraging results and demonstrate the efficiency of the proposed scheme.
Large-scale Land Cover Classification in GaoFen-2 Satellite Imagery
Jun 04, 2018

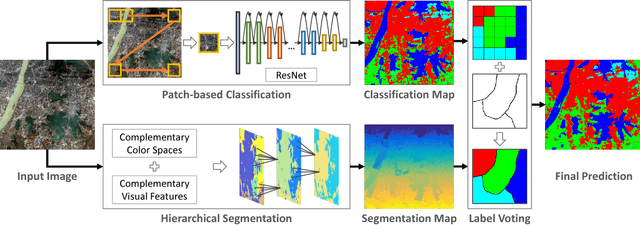

Many significant applications need land cover information of remote sensing images that are acquired from different areas and times, such as change detection and disaster monitoring. However, it is difficult to find a generic land cover classification scheme for different remote sensing images due to the spectral shift caused by diverse acquisition condition. In this paper, we develop a novel land cover classification method that can deal with large-scale data captured from widely distributed areas and different times. Additionally, we establish a large-scale land cover classification dataset consisting of 150 Gaofen-2 imageries as data support for model training and performance evaluation. Our experiments achieve outstanding classification accuracy compared with traditional methods.
AID++: An Updated Version of AID on Scene Classification
Jun 03, 2018
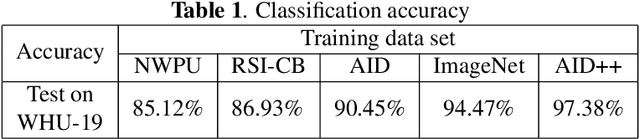
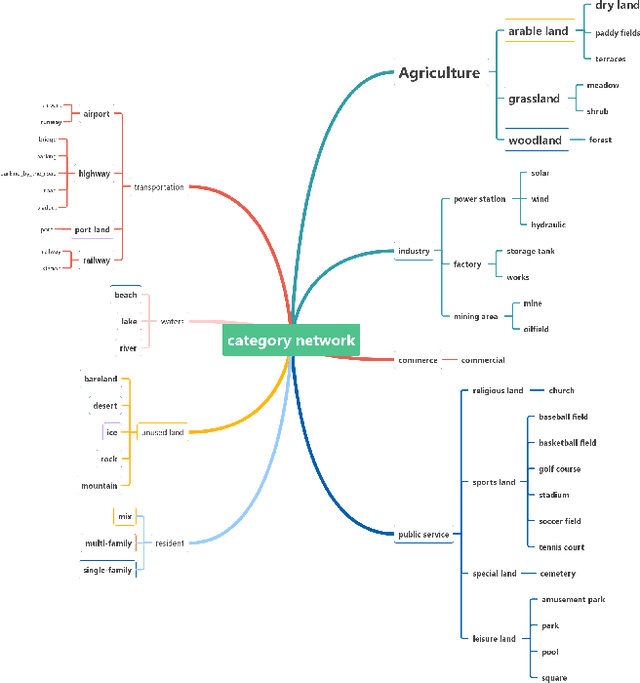

Aerial image scene classification is a fundamental problem for understanding high-resolution remote sensing images and has become an active research task in the field of remote sensing due to its important role in a wide range of applications. However, the limitations of existing datasets for scene classification, such as the small scale and low-diversity, severely hamper the potential usage of the new generation deep convolutional neural networks (CNNs). Although huge efforts have been made in building large-scale datasets very recently, e.g., the Aerial Image Dataset (AID) which contains 10,000 image samples, they are still far from sufficient to fully train a high-capacity deep CNN model. To this end, we present a larger-scale dataset in this paper, named as AID++, for aerial scene classification based on the AID dataset. The proposed AID++ consists of more than 400,000 image samples that are semi-automatically annotated by using the existing the geographical data. We evaluate several prevalent CNN models on the proposed dataset, and the results show that our dataset can be used as a promising benchmark for scene classification.