 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
EasySize: Elastic Analog Circuit Sizing via LLM-Guided Heuristic Search
Aug 07, 2025Analog circuit design is a time-consuming, experience-driven task in chip development. Despite advances in AI, developing universal, fast, and stable gate sizing methods for analog circuits remains a significant challenge. Recent approaches combine Large Language Models (LLMs) with heuristic search techniques to enhance generalizability, but they often depend on large model sizes and lack portability across different technology nodes. To overcome these limitations, we propose EasySize, the first lightweight gate sizing framework based on a finetuned Qwen3-8B model, designed for universal applicability across process nodes, design specifications, and circuit topologies. EasySize exploits the varying Ease of Attainability (EOA) of performance metrics to dynamically construct task-specific loss functions, enabling efficient heuristic search through global Differential Evolution (DE) and local Particle Swarm Optimization (PSO) within a feedback-enhanced flow. Although finetuned solely on 350nm node data, EasySize achieves strong performance on 5 operational amplifier (Op-Amp) netlists across 180nm, 45nm, and 22nm technology nodes without additional targeted training, and outperforms AutoCkt, a widely-used Reinforcement Learning based sizing framework, on 86.67\% of tasks with more than 96.67\% of simulation resources reduction. We argue that EasySize can significantly reduce the reliance on human expertise and computational resources in gate sizing, thereby accelerating and simplifying the analog circuit design process. EasySize will be open-sourced at a later date.
Renmin University of China at TRECVID 2022: Improving Video Search by Feature Fusion and Negation Understanding
Nov 28, 2022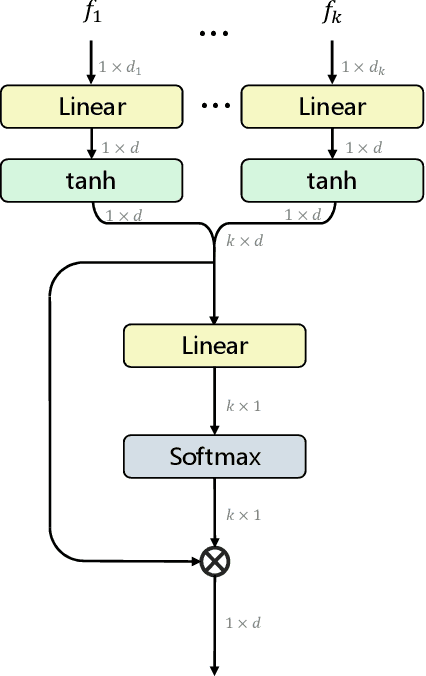


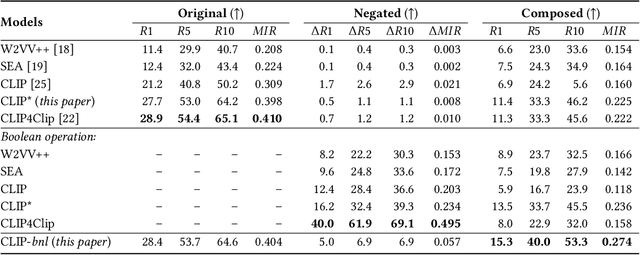
We summarize our TRECVID 2022 Ad-hoc Video Search (AVS) experiments. Our solution is built with two new techniques, namely Lightweight Attentional Feature Fusion (LAFF) for combining diverse visual / textual features and Bidirectional Negation Learning (BNL) for addressing queries that contain negation cues. In particular, LAFF performs feature fusion at both early and late stages and at both text and video ends to exploit diverse (off-the-shelf) features. Compared to multi-head self attention, LAFF is much more compact yet more effective. Its attentional weights can also be used for selecting fewer features, with the retrieval performance mostly preserved. BNL trains a negation-aware video retrieval model by minimizing a bidirectionally constrained loss per triplet, where a triplet consists of a given training video, its original description and a partially negated description. For video feature extraction, we use pre-trained CLIP, BLIP, BEiT, ResNeXt-101 and irCSN. As for text features, we adopt bag-of-words, word2vec, CLIP and BLIP. Our training data consists of MSR-VTT, TGIF and VATEX that were used in our previous participation. In addition, we automatically caption the V3C1 collection for pre-training. The 2022 edition of the TRECVID benchmark has again been a fruitful participation for the RUCMM team. Our best run, with an infAP of 0.262, is ranked at the second place teamwise.
UniASM: Binary Code Similarity Detection without Fine-tuning
Nov 07, 2022Binary code similarity detection (BCSD) is widely used in various binary analysis tasks such as vulnerability search, malware detection, clone detection, and patch analysis. Recent studies have shown that the learning-based binary code embedding models perform better than the traditional feature-based approaches. In this paper, we proposed a novel transformer-based binary code embedding model, named UniASM, to learn representations of the binary functions. We designed two new training tasks to make the spatial distribution of the generated vectors more uniform, which can be used directly in BCSD without any fine-tuning. In addition, we proposed a new tokenization approach for binary functions, increasing the token's semantic information while mitigating the out-of-vocabulary (OOV) problem. The experimental results show that UniASM outperforms state-of-the-art (SOTA) approaches on the evaluation dataset. We achieved the average scores of recall@1 on cross-compilers, cross-optimization-levels and cross-obfuscations are 0.72, 0.63, and 0.77, which is higher than existing SOTA baselines. In a real-world task of known vulnerability searching, UniASM outperforms all the current baselines.
Bridging the gap between target-based and cell-based drug discovery with a graph generative multi-task model
Aug 09, 2022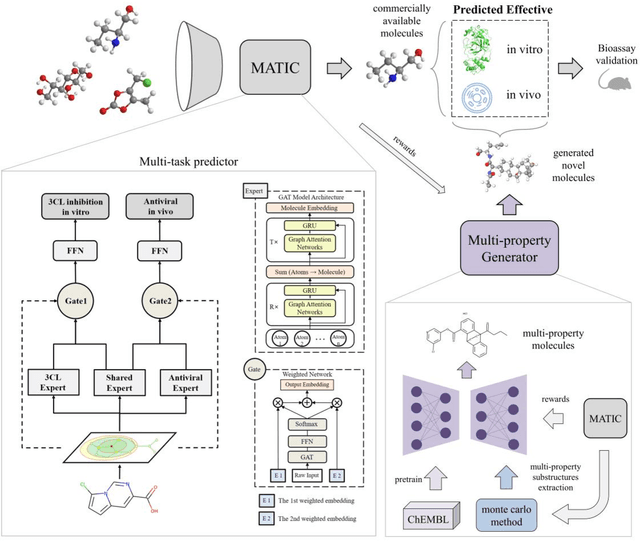
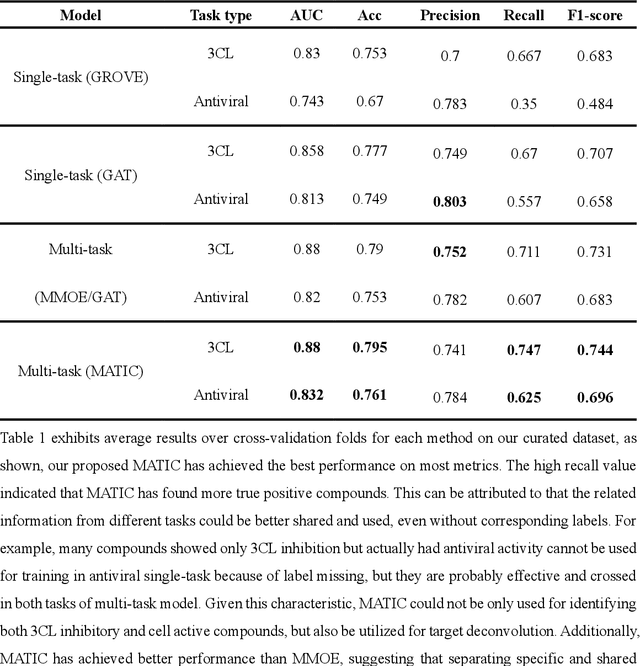
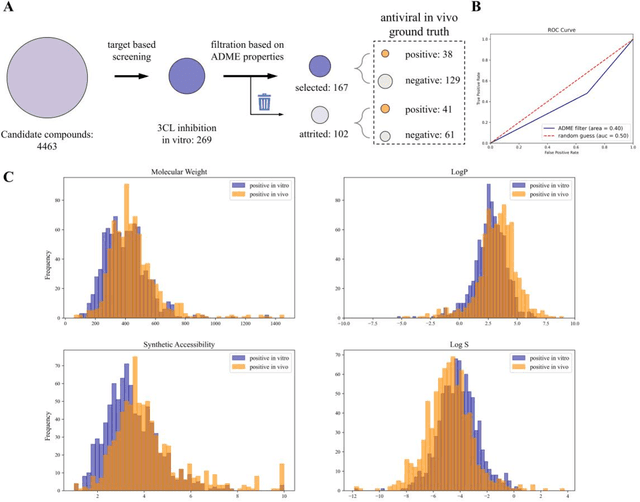
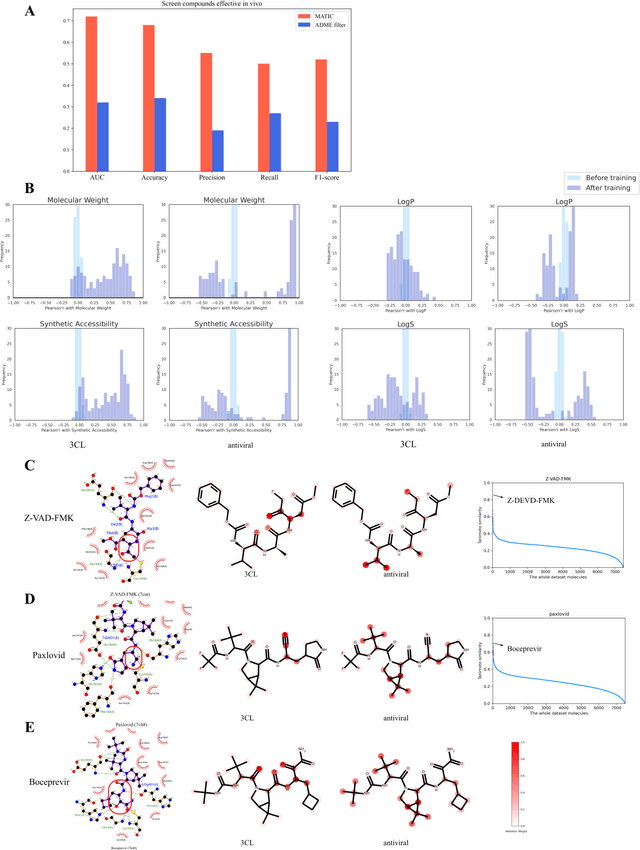
Drug discovery is vitally important for protecting human against disease. Target-based screening is one of the most popular methods to develop new drugs in the past several decades. This method efficiently screens candidate drugs inhibiting target protein in vitro, but it often fails due to inadequate activity of the selected drugs in vivo. Accurate computational methods are needed to bridge this gap. Here, we propose a novel graph multi task deep learning model to identify compounds carrying both target inhibitory and cell active (MATIC) properties. On a carefully curated SARS-CoV-2 dataset, the proposed MATIC model shows advantages comparing with traditional method in screening effective compounds in vivo. Next, we explored the model interpretability and found that the learned features for target inhibition (in vitro) or cell active (in vivo) tasks are different with molecular property correlations and atom functional attentions. Based on these findings, we utilized a monte carlo based reinforcement learning generative model to generate novel multi-property compounds with both in vitro and in vivo efficacy, thus bridging the gap between target-based and cell-based drug discovery.
Learn to Understand Negation in Video Retrieval
Apr 30, 2022

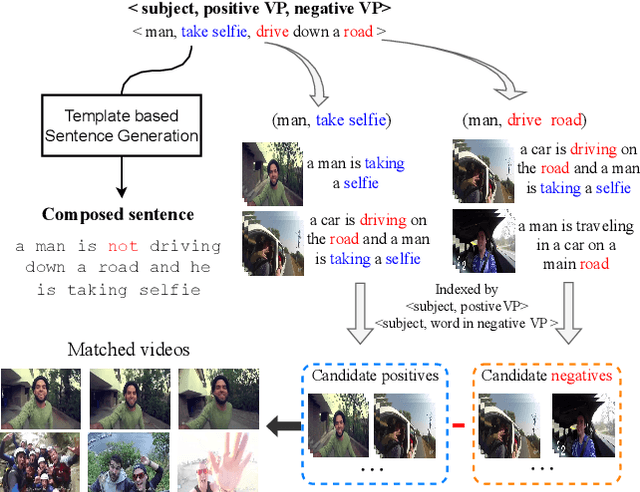
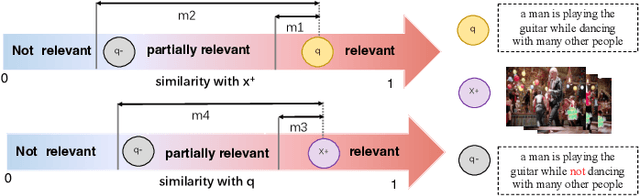
Negation is a common linguistic skill that allows human to express what we do NOT want. Naturally, one might expect video retrieval to support natural-language queries with negation, e.g., finding shots of kids sitting on the floor and not playing with the dog. However, the state-of-the-art deep learning based video retrieval models lack such ability, as they are typically trained on video description datasets such as MSR-VTT and VATEX that lack negated descriptions. Their retrieved results basically ignore the negator in the sample query, incorrectly returning videos showing kids playing with the dog. In this paper, we present the first study on learning to understand negation in video retrieval and make contributions as follows. First, by re-purposing two existing datasets, i.e. MSR-VTT and VATEX, we propose a new evaluation protocol for testing video retrieval with negation. Second, we propose a learning based method for training a negation-aware video retrieval model. The key idea is to first construct a soft negative caption for a specific training video by partially negating its original caption, and then compute a bidirectionally constrained loss on the triplet. This auxiliary loss is then weightedly added to a standard retrieval loss. Experiments on the re-purposed benchmarks show that re-training the CLIP (Contrastive Language-Image Pre-Training) model by the proposed method clearly improves its ability to handle queries with negation. In addition, its performance on the original benchmarks is also improved. Data and source code will be released.
Lightweight Attentional Feature Fusion for Video Retrieval by Text
Dec 03, 2021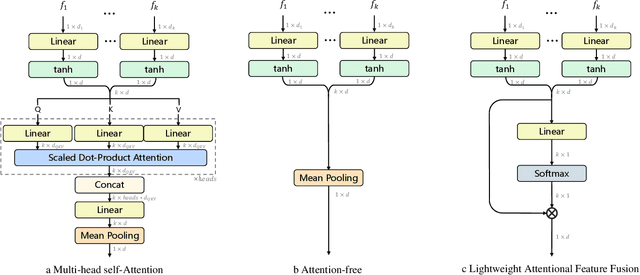

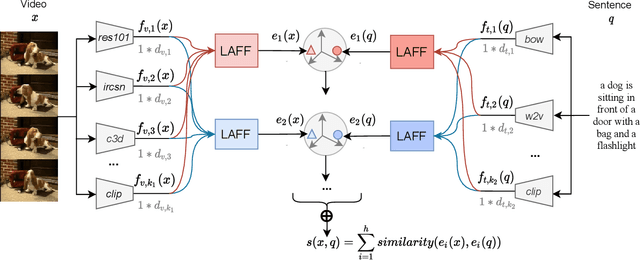
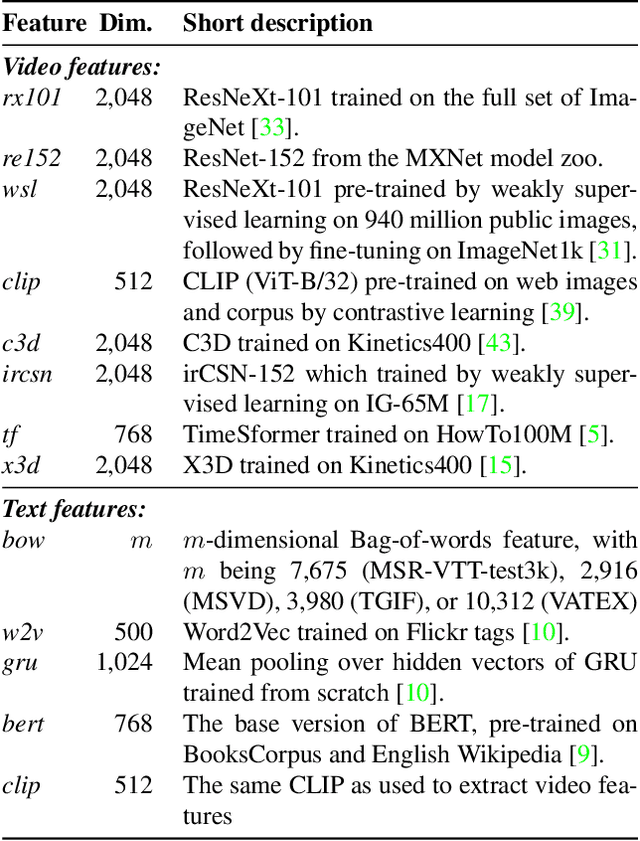
In this paper, we revisit \emph{feature fusion}, an old-fashioned topic, in the new context of video retrieval by text. Different from previous research that considers feature fusion only at one end, let it be video or text, we aim for feature fusion for both ends within a unified framework. We hypothesize that optimizing the convex combination of the features is preferred to modeling their correlations by computationally heavy multi-head self-attention. Accordingly, we propose Lightweight Attentional Feature Fusion (LAFF). LAFF performs feature fusion at both early and late stages and at both video and text ends, making it a powerful method for exploiting diverse (off-the-shelf) features. Extensive experiments on four public datasets, i.e. MSR-VTT, MSVD, TGIF, VATEX, and the large-scale TRECVID AVS benchmark evaluations (2016-2020) show the viability of LAFF. Moreover, LAFF is extremely simple to implement, making it appealing for real-world deployment.
A Novel Framework Integrating AI Model and Enzymological Experiments Promotes Identification of SARS-CoV-2 3CL Protease Inhibitors and Activity-based Probe
May 29, 2021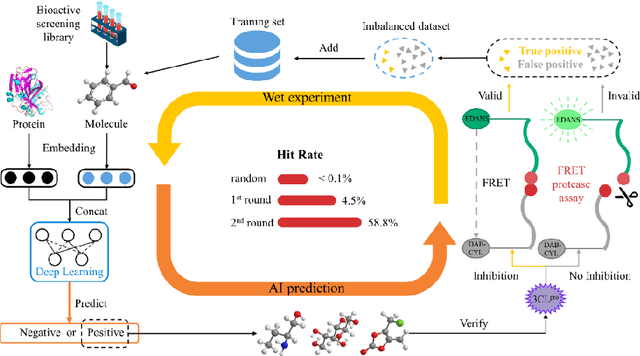
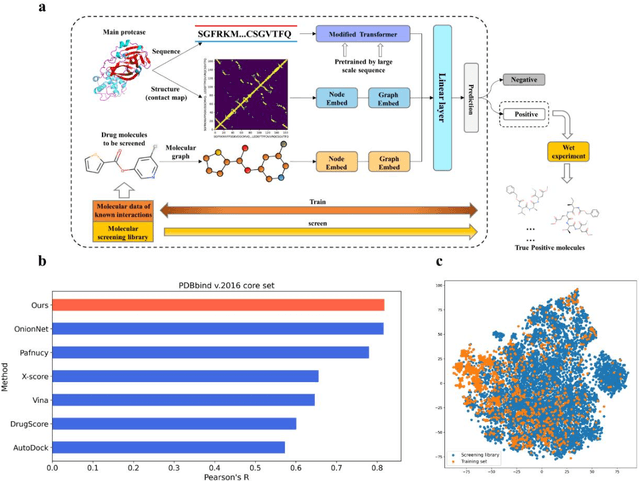
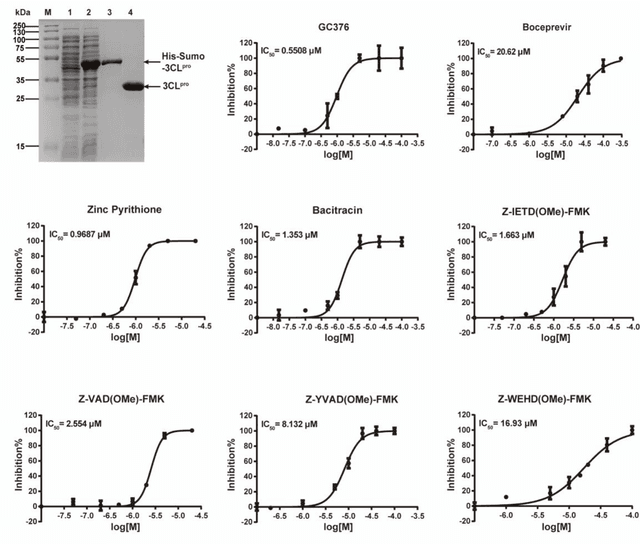
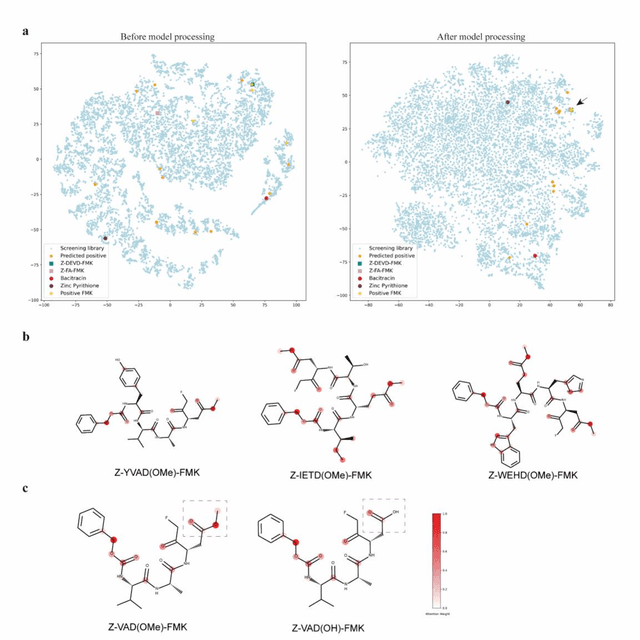
The identification of protein-ligand interaction plays a key role in biochemical research and drug discovery. Although deep learning has recently shown great promise in discovering new drugs, there remains a gap between deep learning-based and experimental approaches. Here we propose a novel framework, named AIMEE, integrating AI Model and Enzymology Experiments, to identify inhibitors against 3CL protease of SARS-CoV-2, which has taken a significant toll on people across the globe. From a bioactive chemical library, we have conducted two rounds of experiments and identified six novel inhibitors with a hit rate of 29.41%, and four of them showed an IC50 value less than 3 {\mu}M. Moreover, we explored the interpretability of the central model in AIMEE, mapping the deep learning extracted features to domain knowledge of chemical properties. Based on this knowledge, a commercially available compound was selected and proven to be an activity-based probe of 3CLpro. This work highlights the great potential of combining deep learning models and biochemical experiments for intelligent iteration and expanding the boundaries of drug discovery.
Question Answering via Web Extracted Tables and Pipelined Models
Apr 16, 2019
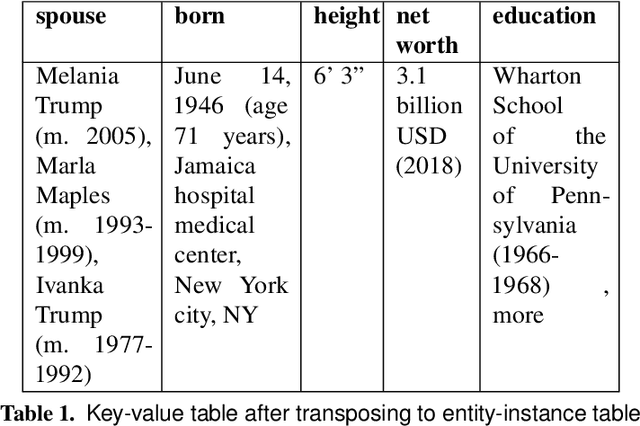
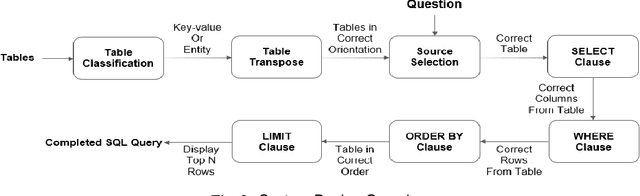
In this paper, we describe a dataset and baseline result for a question answering that utilizes web tables. It contains commonly asked questions on the web and their corresponding answers found in tables on websites. Our dataset is novel in that every question is paired with a table of a different signature. In particular, the dataset contains two classes of tables: entity-instance tables and the key-value tables. Each QA instance comprises a table of either kind, a natural language question, and a corresponding structured SQL query. We build our model by dividing question answering into several tasks, including table retrieval and question element classification, and conduct experiments to measure the performance of each task. We extract various features specific to each task and compose a full pipeline which constructs the SQL query from its parts. Our work provides qualitative results and error analysis for each task, and identifies in detail the reasoning required to generate SQL expressions from natural language questions. This analysis of reasoning informs future models based on neural machine learning.
Exploiting Deep Features for Remote Sensing Image Retrieval: A Systematic Investigation
Jul 15, 2018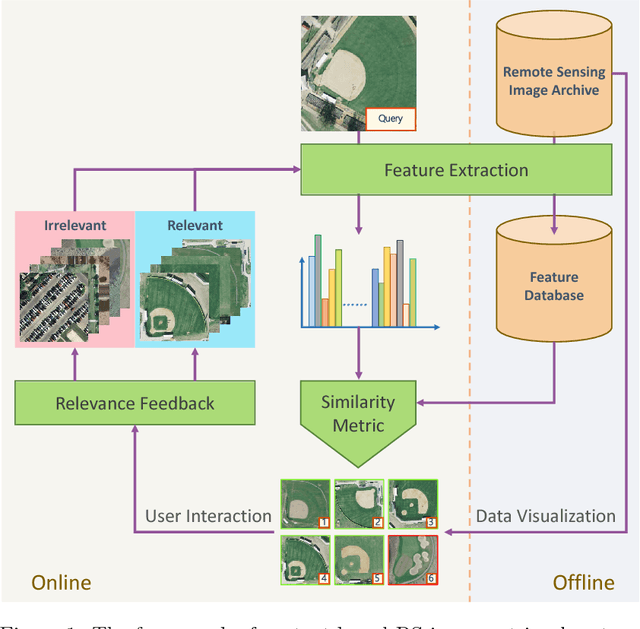
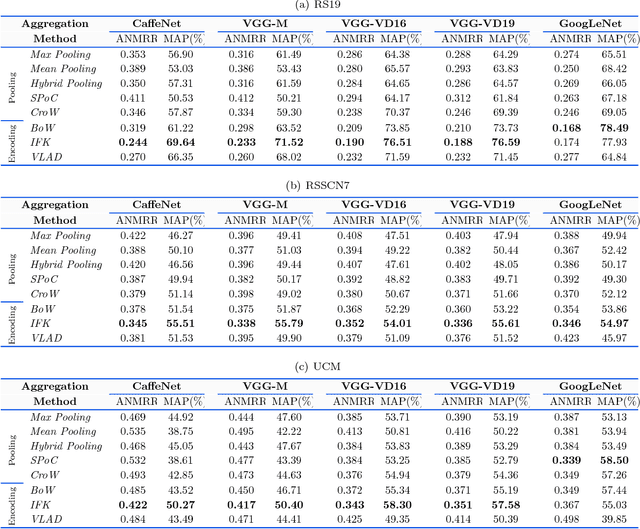
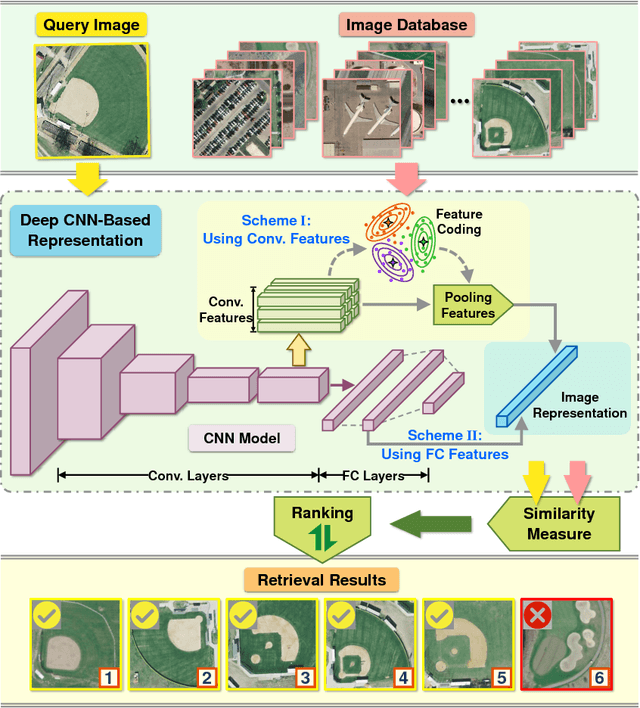
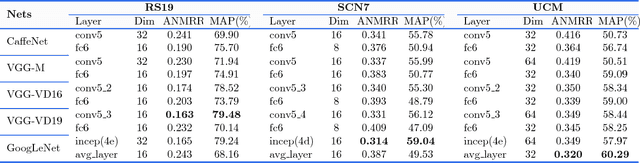
Remote sensing (RS) image retrieval based on visual content is of great significance for geological information mining. Over the past two decades, a large amount of research on this task has been carried out, which mainly focuses on the following three core issues of image retrieval: visual feature, similarity metric and relevance feedback. Along with the advance of these issues, the technology of RS image retrieval has been developed comparatively mature. However, due to the complexity and multiformity of high-resolution remote sensing (HRRS) images, there is still room for improvement in the current methods on HRRS data retrieval. In this paper, we analyze the three key aspects of retrieval and provide a comprehensive review on content-based RS image retrieval methods. Furthermore, for the goal to advance the state-of-the-art in HRRS image retrieval, we focus on the visual feature aspect and delve how to use powerful deep representations in this task. We conduct systematic investigation on evaluating factors that may affect the performance of deep features. By optimizing each factor, we acquire remarkable retrieval results on publicly available HRRS datasets. Finally, we explain the experimental phenomenon in detail and draw instructive conclusions according to our analysis. Our work can serve as a guiding role for the research of content-based RS image retrieval.