 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Understand Negation in Video Retrieval
Paper and Code


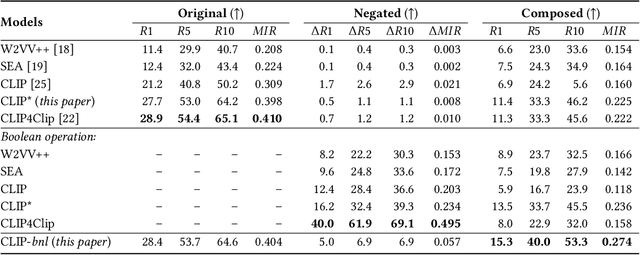
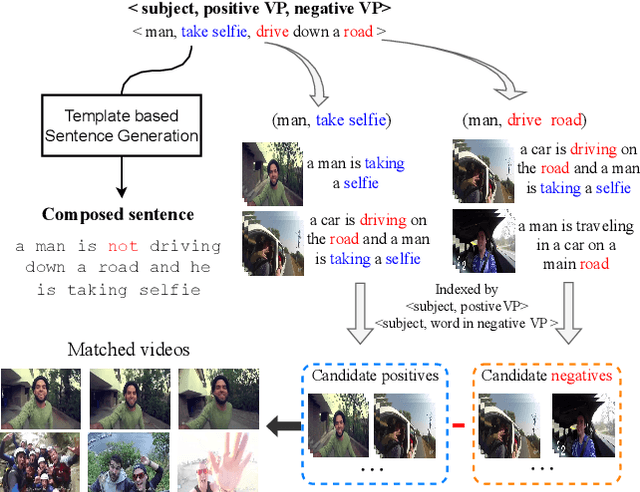
Negation is a common linguistic skill that allows human to express what we do NOT want. Naturally, one might expect video retrieval to support natural-language queries with negation, e.g., finding shots of kids sitting on the floor and not playing with the dog. However, the state-of-the-art deep learning based video retrieval models lack such ability, as they are typically trained on video description datasets such as MSR-VTT and VATEX that lack negated descriptions. Their retrieved results basically ignore the negator in the sample query, incorrectly returning videos showing kids playing with the dog. In this paper, we present the first study on learning to understand negation in video retrieval and make contributions as follows. First, by re-purposing two existing datasets, i.e. MSR-VTT and VATEX, we propose a new evaluation protocol for testing video retrieval with negation. Second, we propose a learning based method for training a negation-aware video retrieval model. The key idea is to first construct a soft negative caption for a specific training video by partially negating its original caption, and then compute a bidirectionally constrained loss on the triplet. This auxiliary loss is then weightedly added to a standard retrieval loss. Experiments on the re-purposed benchmarks show that re-training the CLIP (Contrastive Language-Image Pre-Training) model by the proposed method clearly improves its ability to handle queries with negation. In addition, its performance on the original benchmarks is also improved. Data and source code will be released.