 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Coarse-Grained Matching in Video-Text Retrieval
Oct 17, 2024
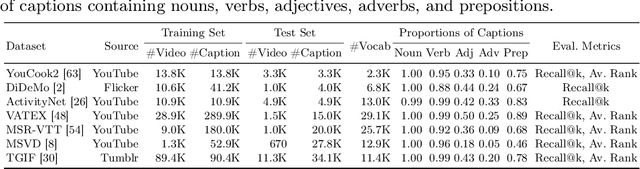


Video-text retrieval has seen significant advancements, yet the ability of models to discern subtle differences in captions still requires verification. In this paper, we introduce a new approach for fine-grained evaluation. Our approach can be applied to existing datasets by automatically generating hard negative test captions with subtle single-word variations across nouns, verbs, adjectives, adverbs, and prepositions. We perform comprehensive experiments using four state-of-the-art models across two standard benchmarks (MSR-VTT and VATEX) and two specially curated datasets enriched with detailed descriptions (VLN-UVO and VLN-OOPS), resulting in a number of novel insights: 1) our analyses show that the current evaluation benchmarks fall short in detecting a model's ability to perceive subtle single-word differences, 2) our fine-grained evaluation highlights the difficulty models face in distinguishing such subtle variations. To enhance fine-grained understanding, we propose a new baseline that can be easily combined with current methods. Experiments on our fine-grained evaluations demonstrate that this approach enhances a model's ability to understand fine-grained differences.
D&M: Enriching E-commerce Videos with Sound Effects by Key Moment Detection and SFX Matching
Aug 23, 2024Videos showcasing specific products are increasingly important for E-commerce. Key moments naturally exist as the first appearance of a specific product, presentation of its distinctive features, the presence of a buying link, etc. Adding proper sound effects (SFX) to these key moments, or video decoration with SFX (VDSFX), is crucial for enhancing the user engaging experience. Previous studies about adding SFX to videos perform video to SFX matching at a holistic level, lacking the ability of adding SFX to a specific moment. Meanwhile, previous studies on video highlight detection or video moment retrieval consider only moment localization, leaving moment to SFX matching untouched. By contrast, we propose in this paper D&M, a unified method that accomplishes key moment detection and moment to SFX matching simultaneously. Moreover, for the new VDSFX task we build a large-scale dataset SFX-Moment from an E-commerce platform. For a fair comparison, we build competitive baselines by extending a number of current video moment detection methods to the new task. Extensive experiments on SFX-Moment show the superior performance of the proposed method over the baselines. Code and data will be released.
Renmin University of China at TRECVID 2022: Improving Video Search by Feature Fusion and Negation Understanding
Nov 28, 2022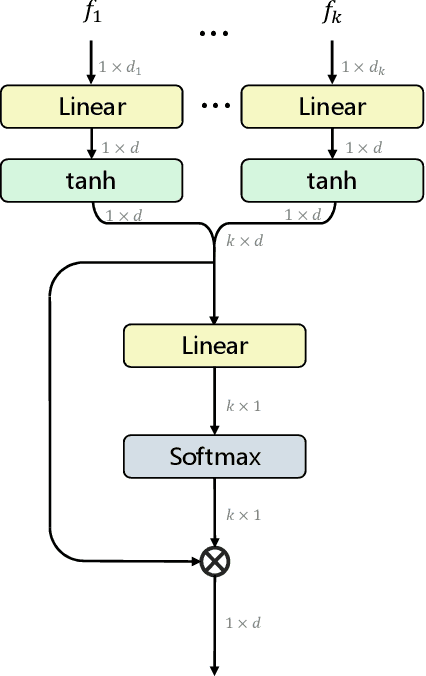

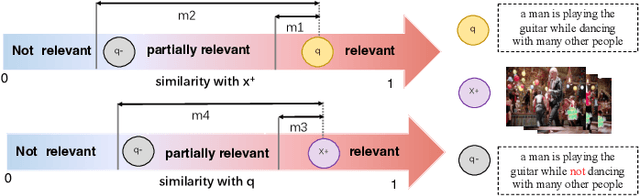

We summarize our TRECVID 2022 Ad-hoc Video Search (AVS) experiments. Our solution is built with two new techniques, namely Lightweight Attentional Feature Fusion (LAFF) for combining diverse visual / textual features and Bidirectional Negation Learning (BNL) for addressing queries that contain negation cues. In particular, LAFF performs feature fusion at both early and late stages and at both text and video ends to exploit diverse (off-the-shelf) features. Compared to multi-head self attention, LAFF is much more compact yet more effective. Its attentional weights can also be used for selecting fewer features, with the retrieval performance mostly preserved. BNL trains a negation-aware video retrieval model by minimizing a bidirectionally constrained loss per triplet, where a triplet consists of a given training video, its original description and a partially negated description. For video feature extraction, we use pre-trained CLIP, BLIP, BEiT, ResNeXt-101 and irCSN. As for text features, we adopt bag-of-words, word2vec, CLIP and BLIP. Our training data consists of MSR-VTT, TGIF and VATEX that were used in our previous participation. In addition, we automatically caption the V3C1 collection for pre-training. The 2022 edition of the TRECVID benchmark has again been a fruitful participation for the RUCMM team. Our best run, with an infAP of 0.262, is ranked at the second place teamwise.
Learn to Understand Negation in Video Retrieval
Apr 30, 2022

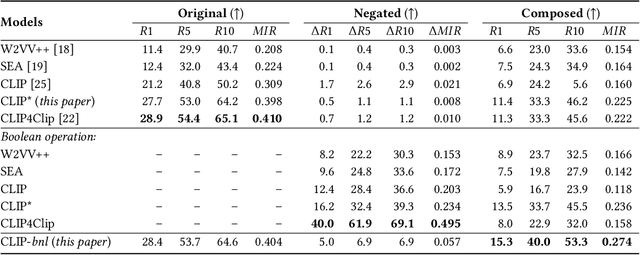
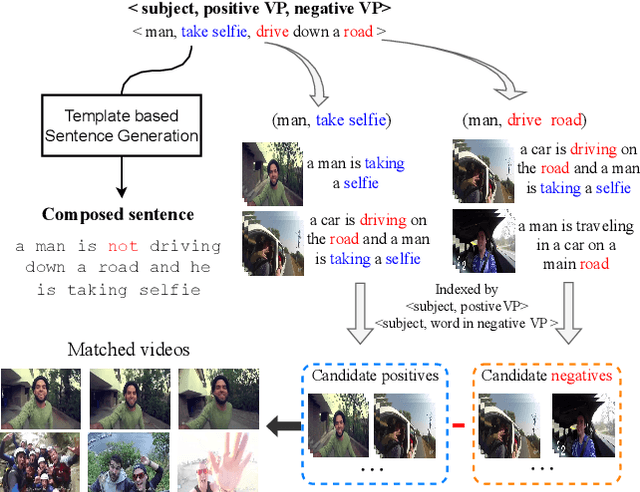
Negation is a common linguistic skill that allows human to express what we do NOT want. Naturally, one might expect video retrieval to support natural-language queries with negation, e.g., finding shots of kids sitting on the floor and not playing with the dog. However, the state-of-the-art deep learning based video retrieval models lack such ability, as they are typically trained on video description datasets such as MSR-VTT and VATEX that lack negated descriptions. Their retrieved results basically ignore the negator in the sample query, incorrectly returning videos showing kids playing with the dog. In this paper, we present the first study on learning to understand negation in video retrieval and make contributions as follows. First, by re-purposing two existing datasets, i.e. MSR-VTT and VATEX, we propose a new evaluation protocol for testing video retrieval with negation. Second, we propose a learning based method for training a negation-aware video retrieval model. The key idea is to first construct a soft negative caption for a specific training video by partially negating its original caption, and then compute a bidirectionally constrained loss on the triplet. This auxiliary loss is then weightedly added to a standard retrieval loss. Experiments on the re-purposed benchmarks show that re-training the CLIP (Contrastive Language-Image Pre-Training) model by the proposed method clearly improves its ability to handle queries with negation. In addition, its performance on the original benchmarks is also improved. Data and source code will be released.
Lightweight Attentional Feature Fusion for Video Retrieval by Text
Dec 03, 2021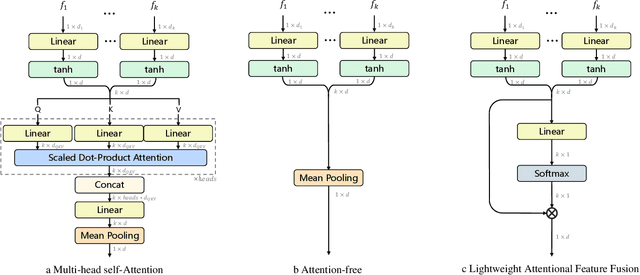

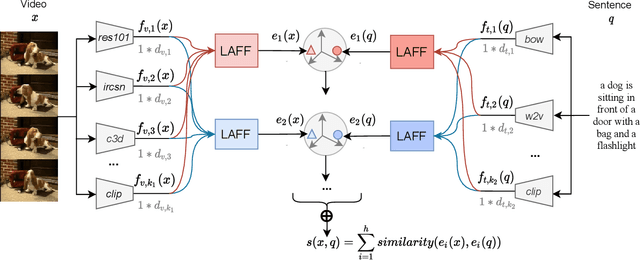
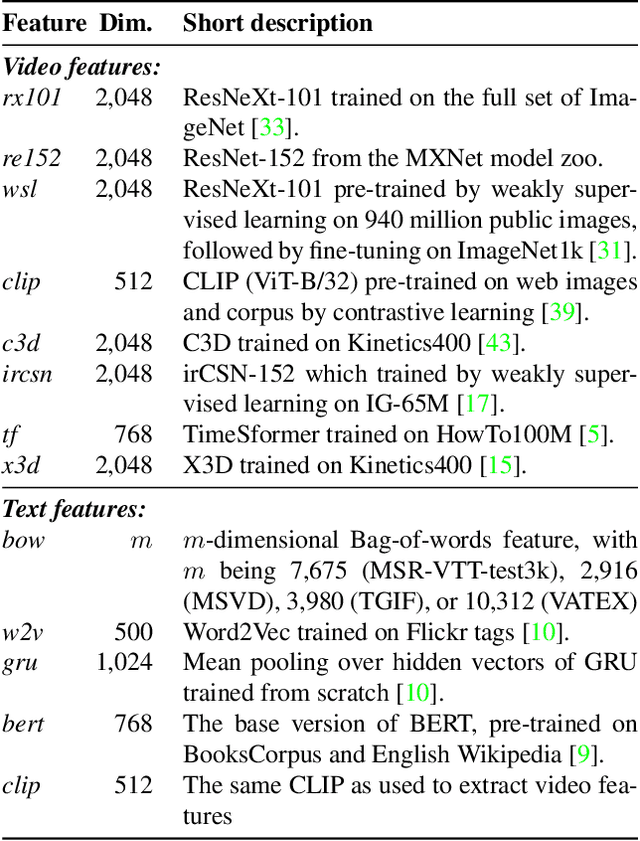
In this paper, we revisit \emph{feature fusion}, an old-fashioned topic, in the new context of video retrieval by text. Different from previous research that considers feature fusion only at one end, let it be video or text, we aim for feature fusion for both ends within a unified framework. We hypothesize that optimizing the convex combination of the features is preferred to modeling their correlations by computationally heavy multi-head self-attention. Accordingly, we propose Lightweight Attentional Feature Fusion (LAFF). LAFF performs feature fusion at both early and late stages and at both video and text ends, making it a powerful method for exploiting diverse (off-the-shelf) features. Extensive experiments on four public datasets, i.e. MSR-VTT, MSVD, TGIF, VATEX, and the large-scale TRECVID AVS benchmark evaluations (2016-2020) show the viability of LAFF. Moreover, LAFF is extremely simple to implement, making it appealing for real-world deployment.
Towards Annotation-Free Evaluation of Cross-Lingual Image Captioning
Dec 09, 2020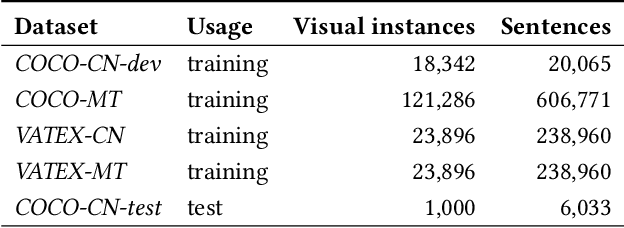
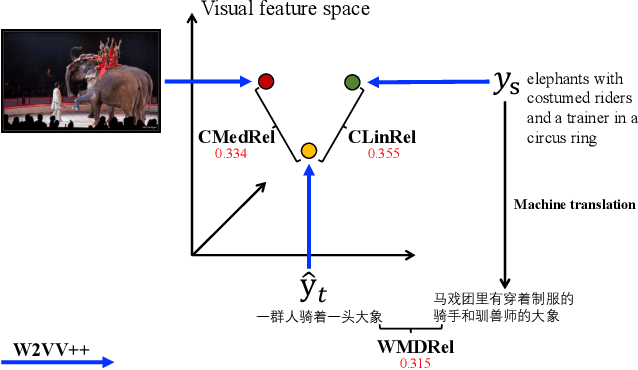
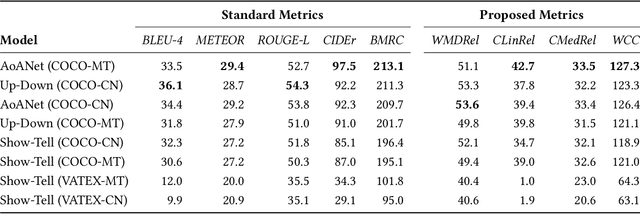
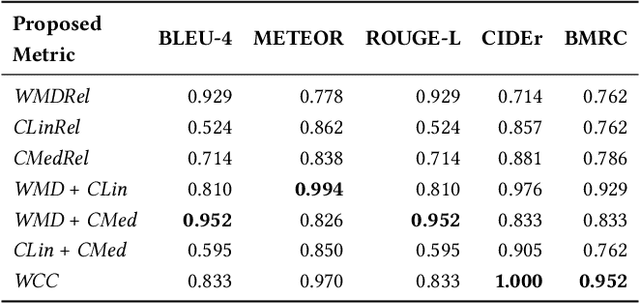
Cross-lingual image captioning, with its ability to caption an unlabeled image in a target language other than English, is an emerging topic in the multimedia field. In order to save the precious human resource from re-writing reference sentences per target language, in this paper we make a brave attempt towards annotation-free evaluation of cross-lingual image captioning. Depending on whether we assume the availability of English references, two scenarios are investigated. For the first scenario with the references available, we propose two metrics, i.e., WMDRel and CLinRel. WMDRel measures the semantic relevance between a model-generated caption and machine translation of an English reference using their Word Mover's Distance. By projecting both captions into a deep visual feature space, CLinRel is a visual-oriented cross-lingual relevance measure. As for the second scenario, which has zero reference and is thus more challenging, we propose CMedRel to compute a cross-media relevance between the generated caption and the image content, in the same visual feature space as used by CLinRel. The promising results show high potential of the new metrics for evaluation with no need of references in the target language.