 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Coarse-Grained Matching in Video-Text Retrieval
Paper and Code
Oct 17, 2024
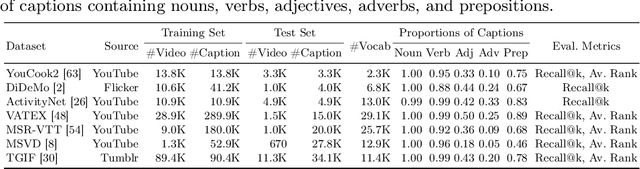


Video-text retrieval has seen significant advancements, yet the ability of models to discern subtle differences in captions still requires verification. In this paper, we introduce a new approach for fine-grained evaluation. Our approach can be applied to existing datasets by automatically generating hard negative test captions with subtle single-word variations across nouns, verbs, adjectives, adverbs, and prepositions. We perform comprehensive experiments using four state-of-the-art models across two standard benchmarks (MSR-VTT and VATEX) and two specially curated datasets enriched with detailed descriptions (VLN-UVO and VLN-OOPS), resulting in a number of novel insights: 1) our analyses show that the current evaluation benchmarks fall short in detecting a model's ability to perceive subtle single-word differences, 2) our fine-grained evaluation highlights the difficulty models face in distinguishing such subtle variations. To enhance fine-grained understanding, we propose a new baseline that can be easily combined with current methods. Experiments on our fine-grained evaluations demonstrate that this approach enhances a model's ability to understand fine-grained differences.