 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEI: Early Intervention for Multimodal Imaging based Disease Recognition
Mar 18, 2026Current methods for multimodal medical imaging based disease recognition face two major challenges. First, the prevailing "fusion after unimodal image embedding" paradigm cannot fully leverage the complementary and correlated information in the multimodal data. Second, the scarcity of labeled multimodal medical images, coupled with their significant domain shift from natural images, hinders the use of cutting-edge Vision Foundation Models (VFMs) for medical image embedding. To jointly address the challenges, we propose a novel Early Intervention (EI) framework. Treating one modality as target and the rest as reference, EI harnesses high-level semantic tokens from the reference as intervention tokens to steer the target modality's embedding process at an early stage. Furthermore, we introduce Mixture of Low-varied-Ranks Adaptation (MoR), a parameter-efficient fine-tuning method that employs a set of low-rank adapters with varied ranks and a weight-relaxed router for VFM adaptation. Extensive experiments on three public datasets for retinal disease, skin lesion, and keen anomaly classification verify the effectiveness of the proposed method against a number of competitive baselines.
Multi-Modal Multi-Instance Learning for Retinal Disease Recognition
Sep 25, 2021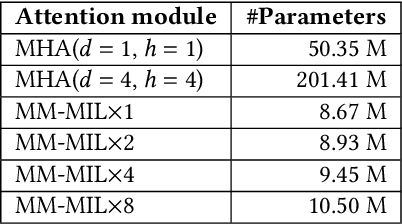
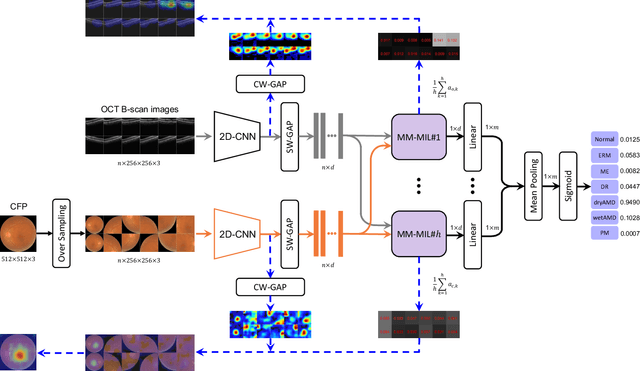
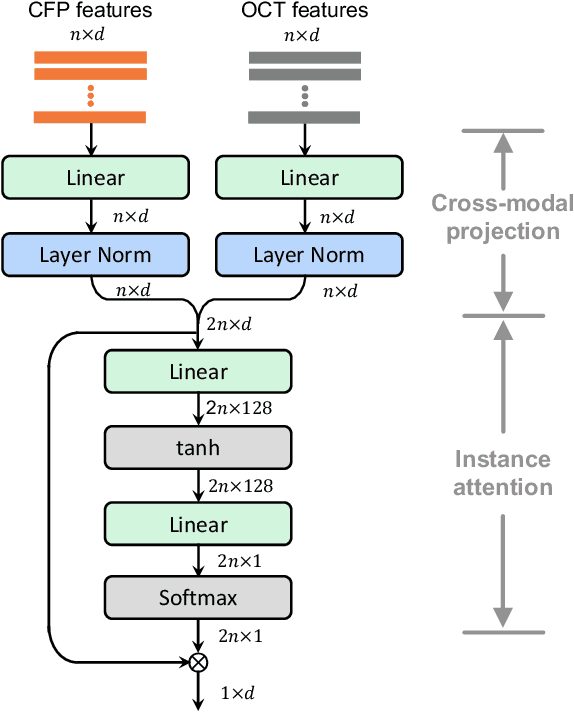
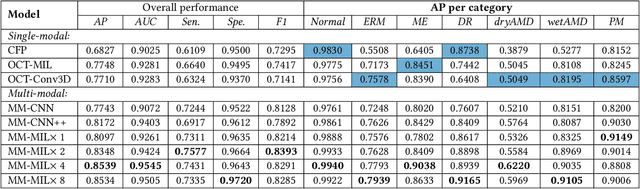
This paper attacks an emerging challenge of multi-modal retinal disease recognition. Given a multi-modal case consisting of a color fundus photo (CFP) and an array of OCT B-scan images acquired during an eye examination, we aim to build a deep neural network that recognizes multiple vision-threatening diseases for the given case. As the diagnostic efficacy of CFP and OCT is disease-dependent, the network's ability of being both selective and interpretable is important. Moreover, as both data acquisition and manual labeling are extremely expensive in the medical domain, the network has to be relatively lightweight for learning from a limited set of labeled multi-modal samples. Prior art on retinal disease recognition focuses either on a single disease or on a single modality, leaving multi-modal fusion largely underexplored. We propose in this paper Multi-Modal Multi-Instance Learning (MM-MIL) for selectively fusing CFP and OCT modalities. Its lightweight architecture (as compared to current multi-head attention modules) makes it suited for learning from relatively small-sized datasets. For an effective use of MM-MIL, we propose to generate a pseudo sequence of CFPs by over sampling a given CFP. The benefits of this tactic include well balancing instances across modalities, increasing the resolution of the CFP input, and finding out regions of the CFP most relevant with respect to the final diagnosis. Extensive experiments on a real-world dataset consisting of 1,206 multi-modal cases from 1,193 eyes of 836 subjects demonstrate the viability of the proposed model.
Towards Annotation-Free Evaluation of Cross-Lingual Image Captioning
Dec 09, 2020
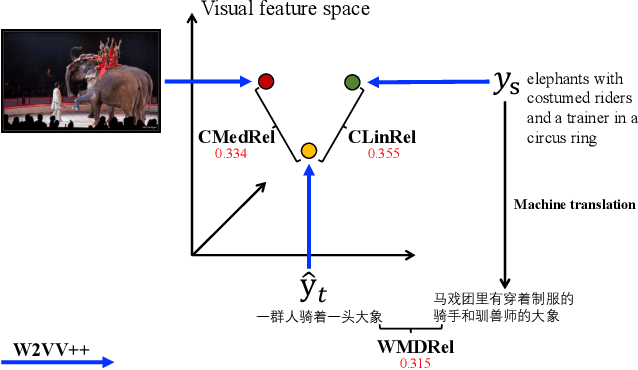
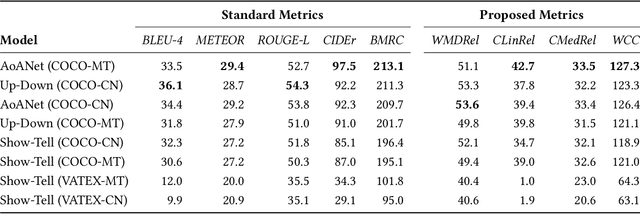
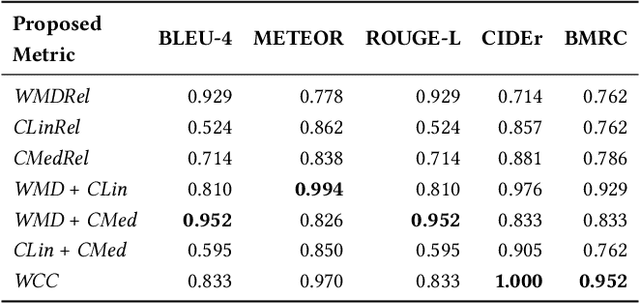
Cross-lingual image captioning, with its ability to caption an unlabeled image in a target language other than English, is an emerging topic in the multimedia field. In order to save the precious human resource from re-writing reference sentences per target language, in this paper we make a brave attempt towards annotation-free evaluation of cross-lingual image captioning. Depending on whether we assume the availability of English references, two scenarios are investigated. For the first scenario with the references available, we propose two metrics, i.e., WMDRel and CLinRel. WMDRel measures the semantic relevance between a model-generated caption and machine translation of an English reference using their Word Mover's Distance. By projecting both captions into a deep visual feature space, CLinRel is a visual-oriented cross-lingual relevance measure. As for the second scenario, which has zero reference and is thus more challenging, we propose CMedRel to compute a cross-media relevance between the generated caption and the image content, in the same visual feature space as used by CLinRel. The promising results show high potential of the new metrics for evaluation with no need of references in the target language.