 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Fundus Image Registration under Large FoV Disparity
Dec 14, 2025Previous work on cross-modal fundus image registration (CMFIR) assumes small cross-modal Field-of-View (FoV) disparity. By contrast, this paper is targeted at a more challenging scenario with large FoV disparity, to which directly applying current methods fails. We propose Crop and Alignment for cross-modal fundus image Registration(CARe), a very simple yet effective method. Specifically, given an OCTA with smaller FoV as a source image and a wide-field color fundus photograph (wfCFP) as a target image, our Crop operation exploits the physiological structure of the retina to crop from the target image a sub-image with its FoV roughly aligned with that of the source. This operation allows us to re-purpose the previous small-FoV-disparity oriented methods for subsequent image registration. Moreover, we improve spatial transformation by a double-fitting based Alignment module that utilizes the classical RANSAC algorithm and polynomial-based coordinate fitting in a sequential manner. Extensive experiments on a newly developed test set of 60 OCTA-wfCFP pairs verify the viability of CARe for CMFIR.
Convolutional Prompting for Broad-Domain Retinal Vessel Segmentation
Dec 24, 2024Previous research on retinal vessel segmentation is targeted at a specific image domain, mostly color fundus photography (CFP). In this paper we make a brave attempt to attack a more challenging task of broad-domain retinal vessel segmentation (BD-RVS), which is to develop a unified model applicable to varied domains including CFP, SLO, UWF, OCTA and FFA. To that end, we propose Dual Convoltuional Prompting (DCP) that learns to extract domain-specific features by localized prompting along both position and channel dimensions. DCP is designed as a plug-in module that can effectively turn a R2AU-Net based vessel segmentation network to a unified model, yet without the need of modifying its network structure. For evaluation we build a broad-domain set using five public domain-specific datasets including ROSSA, FIVES, IOSTAR, PRIME-FP20 and VAMPIRE. In order to benchmark BD-RVS on the broad-domain dataset, we re-purpose a number of existing methods originally developed in other contexts, producing eight baseline methods in total. Extensive experiments show the the proposed method compares favorably against the baselines for BD-RVS.
Lesion Localization in OCT by Semi-Supervised Object Detection
Apr 24, 2022
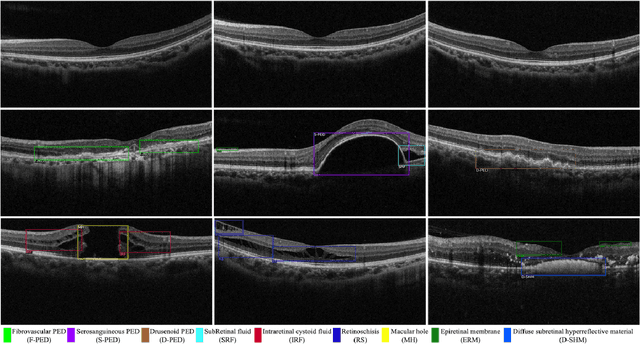

Over 300 million people worldwide are affected by various retinal diseases. By noninvasive Optical Coherence Tomography (OCT) scans, a number of abnormal structural changes in the retina, namely retinal lesions, can be identified. Automated lesion localization in OCT is thus important for detecting retinal diseases at their early stage. To conquer the lack of manual annotation for deep supervised learning, this paper presents a first study on utilizing semi-supervised object detection (SSOD) for lesion localization in OCT images. To that end, we develop a taxonomy to provide a unified and structured viewpoint of the current SSOD methods, and consequently identify key modules in these methods. To evaluate the influence of these modules in the new task, we build OCT-SS, a new dataset consisting of over 1k expert-labeled OCT B-scan images and over 13k unlabeled B-scans. Extensive experiments on OCT-SS identify Unbiased Teacher (UnT) as the best current SSOD method for lesion localization. Moreover, we improve over this strong baseline, with mAP increased from 49.34 to 50.86.
Multi-Modal Multi-Instance Learning for Retinal Disease Recognition
Sep 25, 2021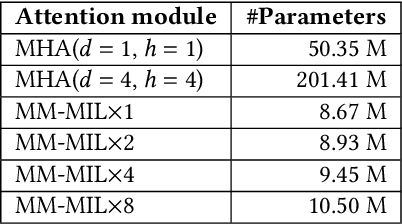
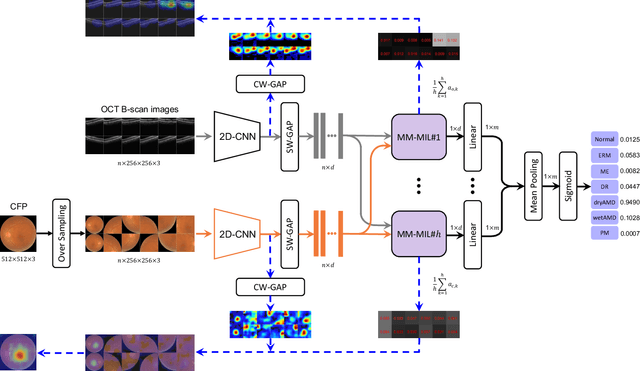
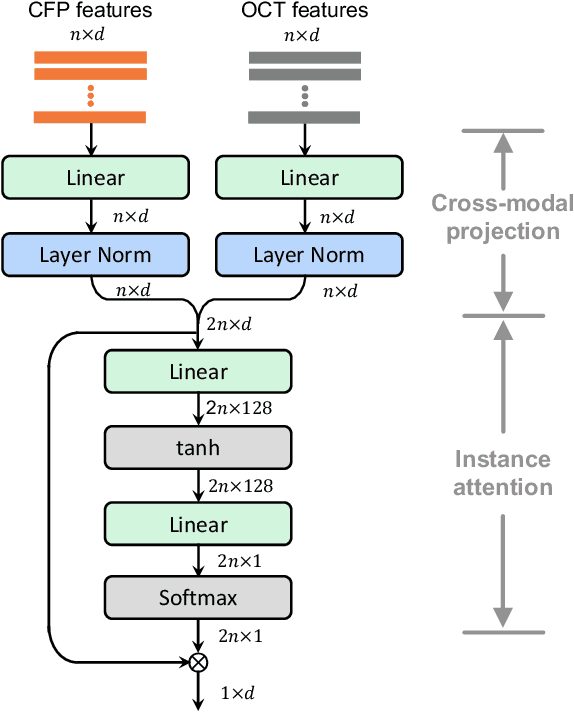
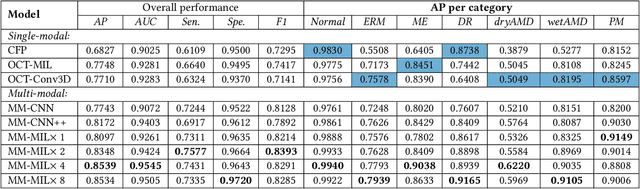
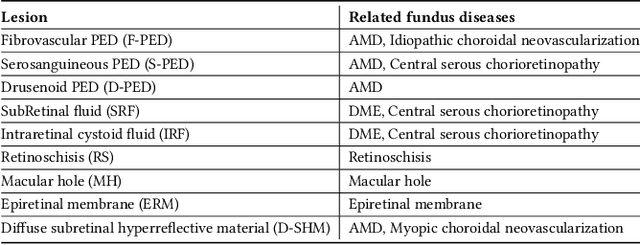
This paper attacks an emerging challenge of multi-modal retinal disease recognition. Given a multi-modal case consisting of a color fundus photo (CFP) and an array of OCT B-scan images acquired during an eye examination, we aim to build a deep neural network that recognizes multiple vision-threatening diseases for the given case. As the diagnostic efficacy of CFP and OCT is disease-dependent, the network's ability of being both selective and interpretable is important. Moreover, as both data acquisition and manual labeling are extremely expensive in the medical domain, the network has to be relatively lightweight for learning from a limited set of labeled multi-modal samples. Prior art on retinal disease recognition focuses either on a single disease or on a single modality, leaving multi-modal fusion largely underexplored. We propose in this paper Multi-Modal Multi-Instance Learning (MM-MIL) for selectively fusing CFP and OCT modalities. Its lightweight architecture (as compared to current multi-head attention modules) makes it suited for learning from relatively small-sized datasets. For an effective use of MM-MIL, we propose to generate a pseudo sequence of CFPs by over sampling a given CFP. The benefits of this tactic include well balancing instances across modalities, increasing the resolution of the CFP input, and finding out regions of the CFP most relevant with respect to the final diagnosis. Extensive experiments on a real-world dataset consisting of 1,206 multi-modal cases from 1,193 eyes of 836 subjects demonstrate the viability of the proposed model.
Learning Two-Stream CNN for Multi-Modal Age-related Macular Degeneration Categorization
Dec 03, 2020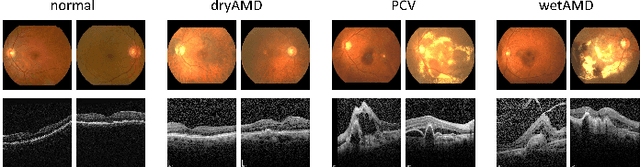
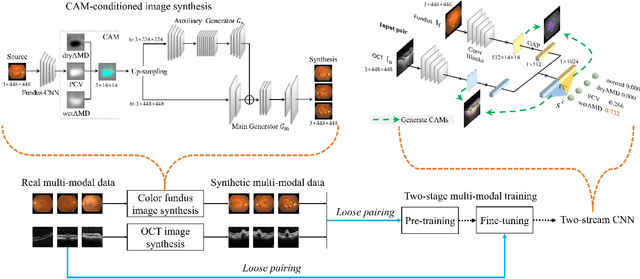
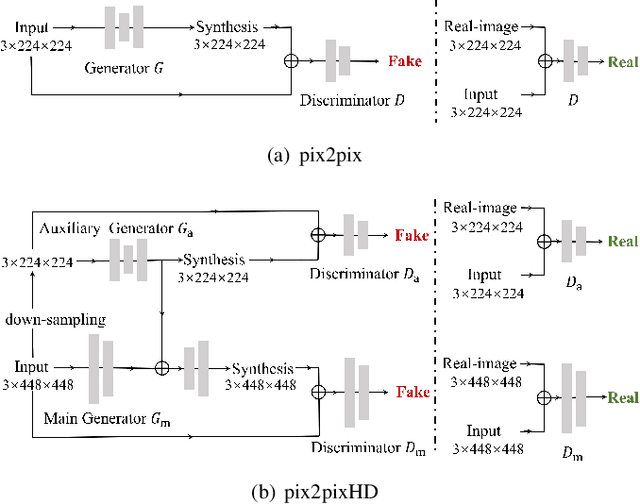
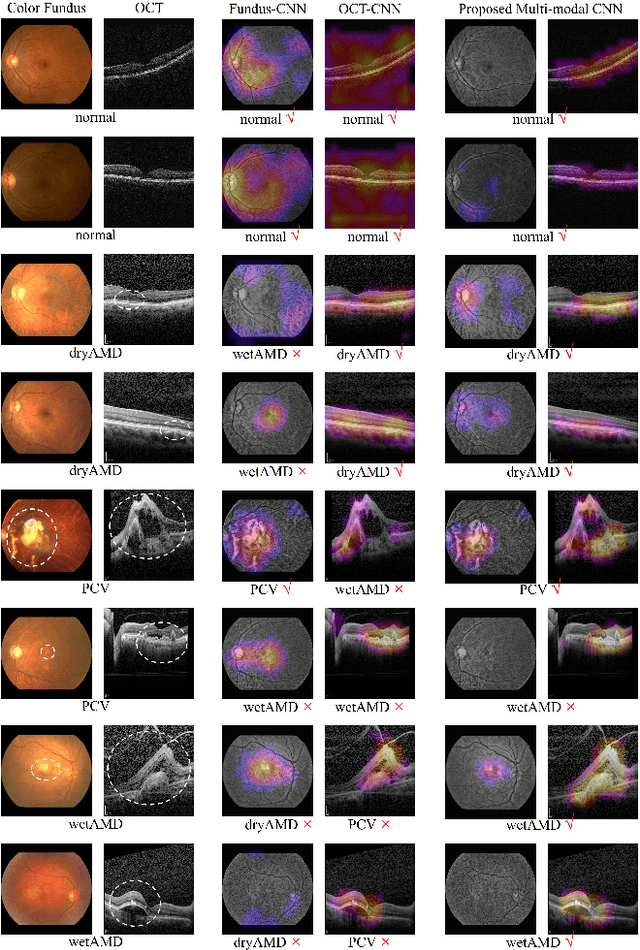
This paper tackles automated categorization of Age-related Macular Degeneration (AMD), a common macular disease among people over 50. Previous research efforts mainly focus on AMD categorization with a single-modal input, let it be a color fundus image or an OCT image. By contrast, we consider AMD categorization given a multi-modal input, a direction that is clinically meaningful yet mostly unexplored. Contrary to the prior art that takes a traditional approach of feature extraction plus classifier training that cannot be jointly optimized, we opt for end-to-end multi-modal Convolutional Neural Networks (MM-CNN). Our MM-CNN is instantiated by a two-stream CNN, with spatially-invariant fusion to combine information from the fundus and OCT streams. In order to visually interpret the contribution of the individual modalities to the final prediction, we extend the class activation mapping (CAM) technique to the multi-modal scenario. For effective training of MM-CNN, we develop two data augmentation methods. One is GAN-based fundus / OCT image synthesis, with our novel use of CAMs as conditional input of a high-resolution image-to-image translation GAN. The other method is Loose Pairing, which pairs a fundus image and an OCT image on the basis of their classes instead of eye identities. Experiments on a clinical dataset consisting of 1,099 color fundus images and 1,290 OCT images acquired from 1,099 distinct eyes verify the effectiveness of the proposed solution for multi-modal AMD categorization.
Learn to Segment Retinal Lesions and Beyond
Dec 25, 2019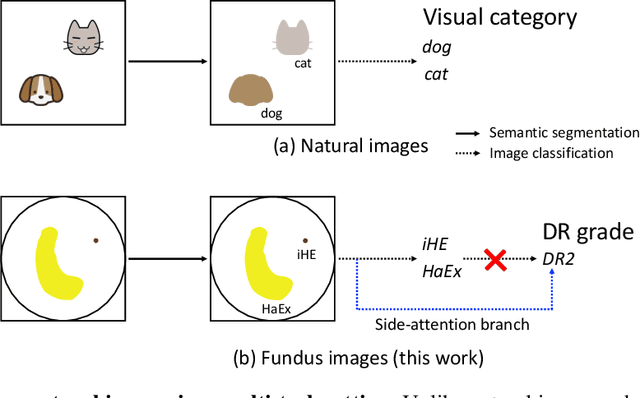

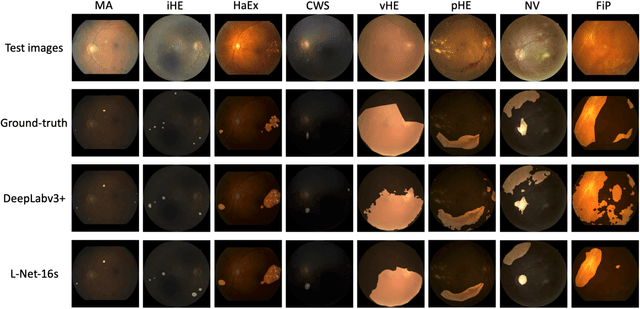

Towards automated retinal screening, this paper makes an endeavor to simultaneously achieve pixel-level retinal lesion segmentation and image-level disease classification. Such a multi-task approach is crucial for accurate and clinically interpretable disease diagnosis. Prior art is insufficient due to three challenges, that is, lesions lacking objective boundaries, clinical importance of lesions irrelevant to their size, and the lack of one-to-one correspondence between lesion and disease classes. This paper attacks the three challenges in the context of diabetic retinopathy (DR) grading. We propose L-Net, a new variant of fully convolutional networks, with its expansive path re-designed to tackle the first challenge. A dual loss that leverages both semantic segmentation and image classification losses is devised to resolve the second challenge. We propose Side-Attention Net (SiAN) as our multi-task framework. Harnessing L-Net as a side-attention branch, SiAN simultaneously improves DR grading and interprets the decision with lesion maps. A set of 12K fundus images is manually segmented by 45 ophthalmologists for 8 DR-related lesions, resulting in 290K manual segments in total. Extensive experiments on this large-scale dataset show that our proposed approach surpasses the prior art for multiple tasks including lesion segmentation, lesion classification and DR grading.
Two-Stream CNN with Loose Pair Training for Multi-modal AMD Categorization
Jul 28, 2019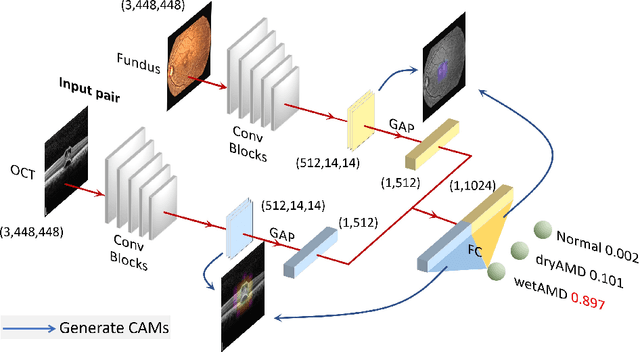

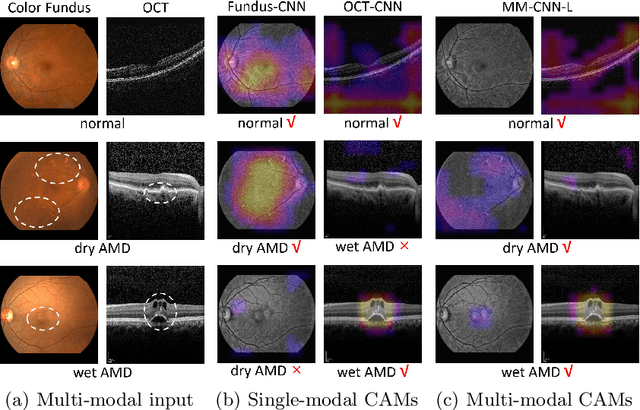
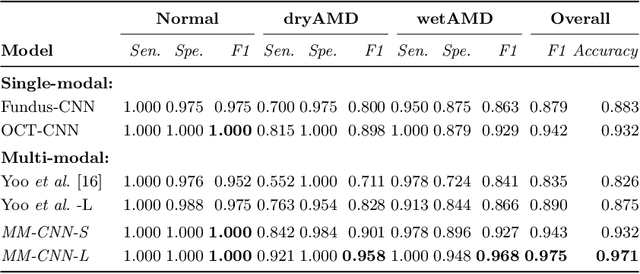
This paper studies automated categorization of age-related macular degeneration (AMD) given a multi-modal input, which consists of a color fundus image and an optical coherence tomography (OCT) image from a specific eye. Previous work uses a traditional method, comprised of feature extraction and classifier training that cannot be optimized jointly. By contrast, we propose a two-stream convolutional neural network (CNN) that is end-to-end. The CNN's fusion layer is tailored to the need of fusing information from the fundus and OCT streams. For generating more multi-modal training instances, we introduce Loose Pair training, where a fundus image and an OCT image are paired based on class labels rather than eyes. Moreover, for a visual interpretation of how the individual modalities make contributions, we extend the class activation mapping technique to the multi-modal scenario. Experiments on a real-world dataset collected from an outpatient clinic justify the viability of our proposal for multi-modal AMD categorization.