 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Augmented Inverse Reinforcement Learning with Graph Convolutions for Multi-Agent Task Allocation
Apr 08, 2025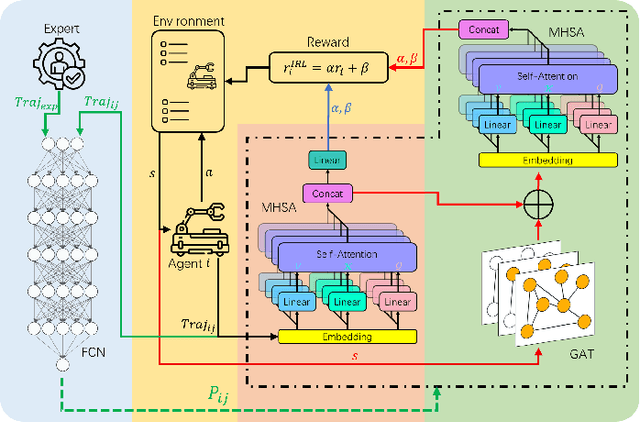
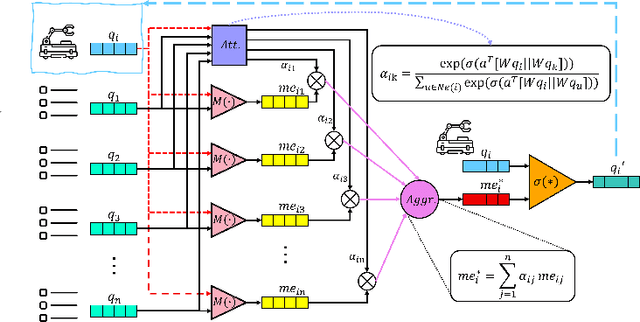
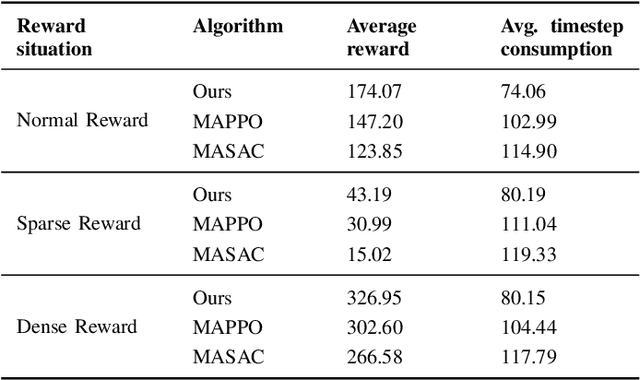
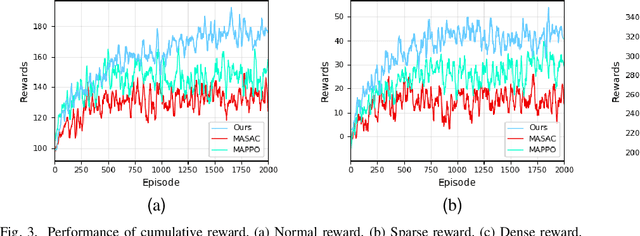
Multi-agent task allocation (MATA) plays a vital role in cooperative multi-agent systems, with significant implications for applications such as logistics, search and rescue, and robotic coordination. Although traditional deep reinforcement learning (DRL) methods have been shown to be promising, their effectiveness is hindered by a reliance on manually designed reward functions and inefficiencies in dynamic environments. In this paper, an inverse reinforcement learning (IRL)-based framework is proposed, in which multi-head self-attention (MHSA) and graph attention mechanisms are incorporated to enhance reward function learning and task execution efficiency. Expert demonstrations are utilized to infer optimal reward densities, allowing dependence on handcrafted designs to be reduced and adaptability to be improved. Extensive experiments validate the superiority of the proposed method over widely used multi-agent reinforcement learning (MARL) algorithms in terms of both cumulative rewards and task execution efficiency.
Two-Stream CNN with Loose Pair Training for Multi-modal AMD Categorization
Jul 28, 2019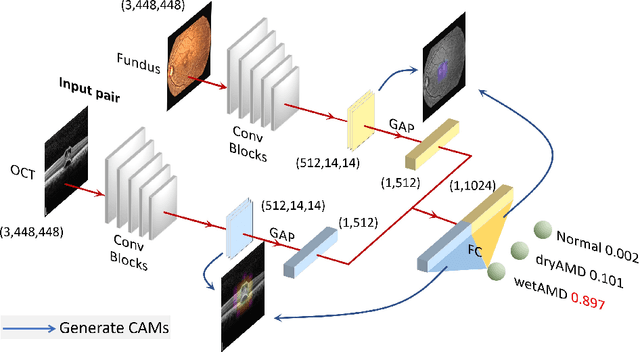

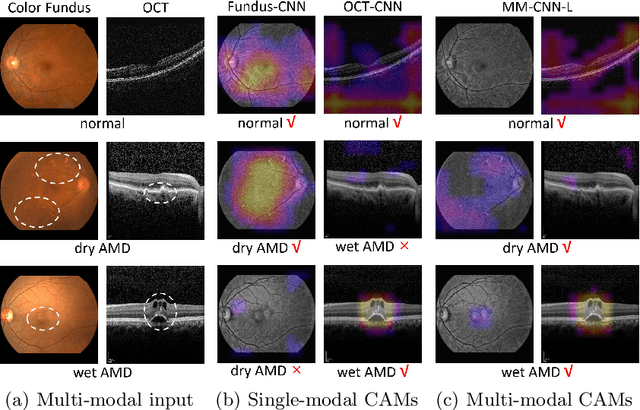
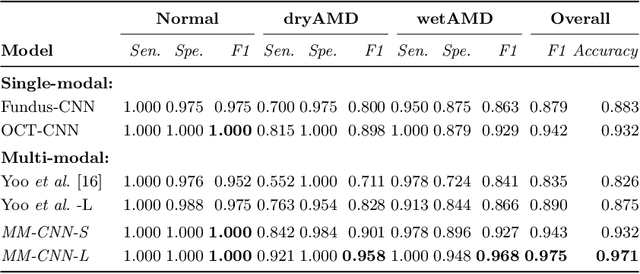
This paper studies automated categorization of age-related macular degeneration (AMD) given a multi-modal input, which consists of a color fundus image and an optical coherence tomography (OCT) image from a specific eye. Previous work uses a traditional method, comprised of feature extraction and classifier training that cannot be optimized jointly. By contrast, we propose a two-stream convolutional neural network (CNN) that is end-to-end. The CNN's fusion layer is tailored to the need of fusing information from the fundus and OCT streams. For generating more multi-modal training instances, we introduce Loose Pair training, where a fundus image and an OCT image are paired based on class labels rather than eyes. Moreover, for a visual interpretation of how the individual modalities make contributions, we extend the class activation mapping technique to the multi-modal scenario. Experiments on a real-world dataset collected from an outpatient clinic justify the viability of our proposal for multi-modal AMD categorization.