 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Two-Stream CNN for Multi-Modal Age-related Macular Degeneration Categorization
Dec 03, 2020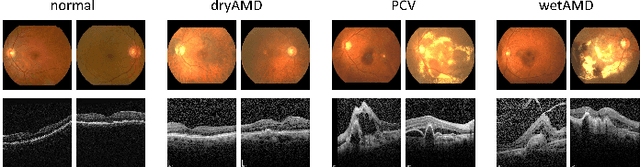
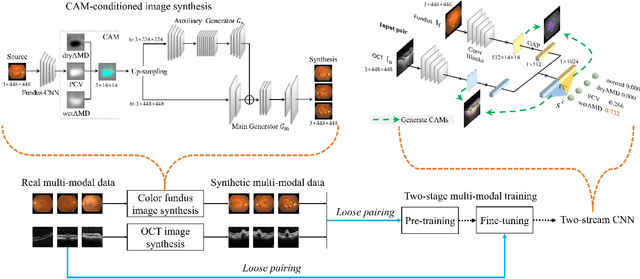
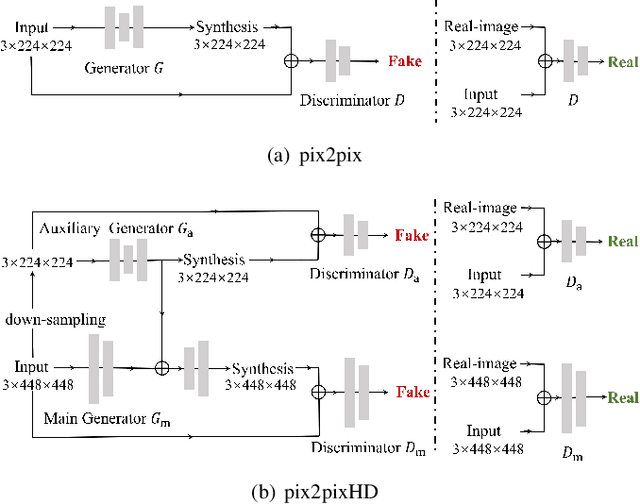
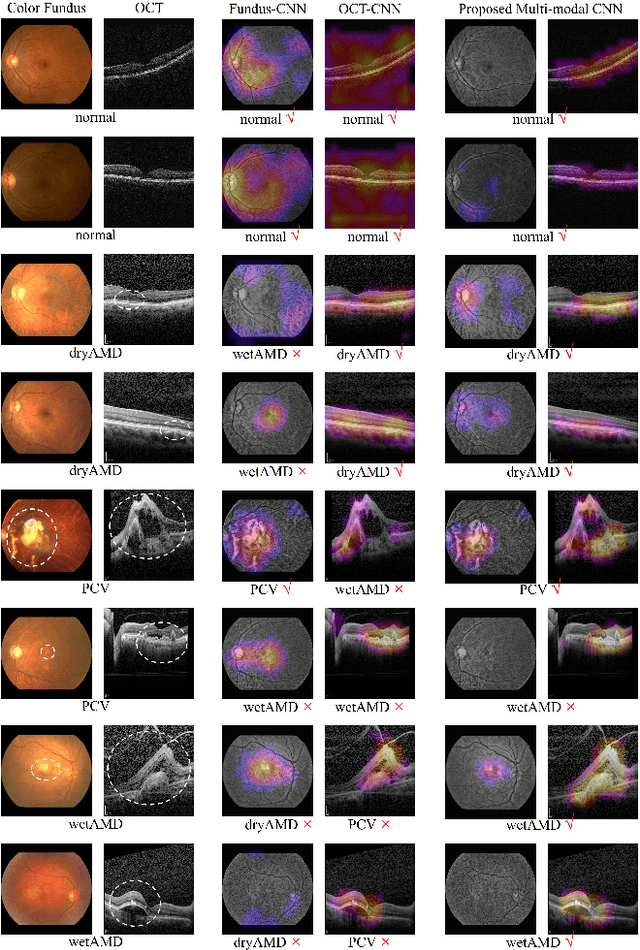
This paper tackles automated categorization of Age-related Macular Degeneration (AMD), a common macular disease among people over 50. Previous research efforts mainly focus on AMD categorization with a single-modal input, let it be a color fundus image or an OCT image. By contrast, we consider AMD categorization given a multi-modal input, a direction that is clinically meaningful yet mostly unexplored. Contrary to the prior art that takes a traditional approach of feature extraction plus classifier training that cannot be jointly optimized, we opt for end-to-end multi-modal Convolutional Neural Networks (MM-CNN). Our MM-CNN is instantiated by a two-stream CNN, with spatially-invariant fusion to combine information from the fundus and OCT streams. In order to visually interpret the contribution of the individual modalities to the final prediction, we extend the class activation mapping (CAM) technique to the multi-modal scenario. For effective training of MM-CNN, we develop two data augmentation methods. One is GAN-based fundus / OCT image synthesis, with our novel use of CAMs as conditional input of a high-resolution image-to-image translation GAN. The other method is Loose Pairing, which pairs a fundus image and an OCT image on the basis of their classes instead of eye identities. Experiments on a clinical dataset consisting of 1,099 color fundus images and 1,290 OCT images acquired from 1,099 distinct eyes verify the effectiveness of the proposed solution for multi-modal AMD categorization.
Two-Stream CNN with Loose Pair Training for Multi-modal AMD Categorization
Jul 28, 2019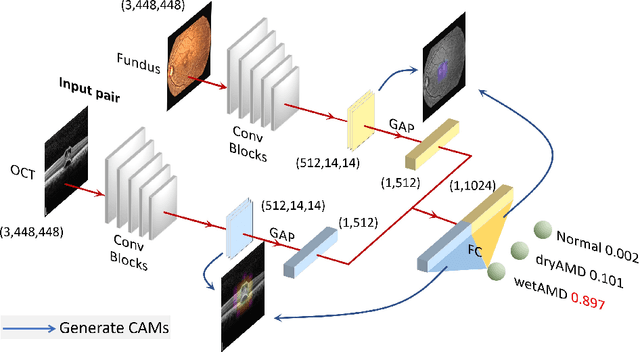

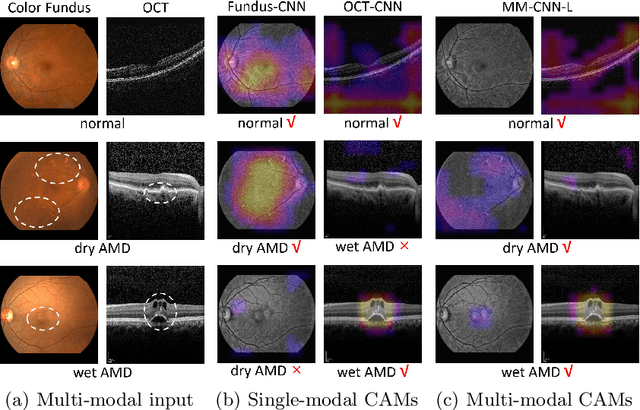
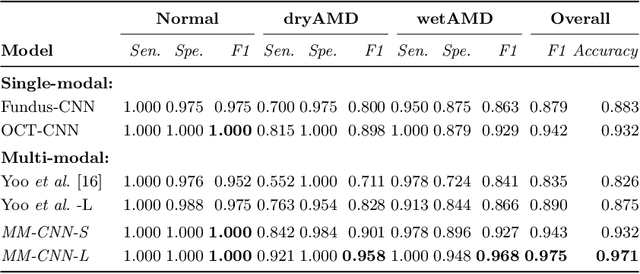
This paper studies automated categorization of age-related macular degeneration (AMD) given a multi-modal input, which consists of a color fundus image and an optical coherence tomography (OCT) image from a specific eye. Previous work uses a traditional method, comprised of feature extraction and classifier training that cannot be optimized jointly. By contrast, we propose a two-stream convolutional neural network (CNN) that is end-to-end. The CNN's fusion layer is tailored to the need of fusing information from the fundus and OCT streams. For generating more multi-modal training instances, we introduce Loose Pair training, where a fundus image and an OCT image are paired based on class labels rather than eyes. Moreover, for a visual interpretation of how the individual modalities make contributions, we extend the class activation mapping technique to the multi-modal scenario. Experiments on a real-world dataset collected from an outpatient clinic justify the viability of our proposal for multi-modal AMD categorization.