 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Business Events to Auditable Decisions: Ontology-Governed Graph Simulation for Enterprise AI
Apr 08, 2026Existing LLM-based agent systems share a common architectural failure: they answer from the unrestricted knowledge space without first simulating how active business scenarios reshape that space for the event at hand -- producing decisions that are fluent but ungrounded and carrying no audit trail. We present LOM-action, which equips enterprise AI with \emph{event-driven ontology simulation}: business events trigger scenario conditions encoded in the enterprise ontology~(EO), which drive deterministic graph mutations in an isolated sandbox, evolving a working copy of the subgraph into the scenario-valid simulation graph $G_{\text{sim}}$; all decisions are derived exclusively from this evolved graph. The core pipeline is \emph{event $\to$ simulation $\to$ decision}, realized through a dual-mode architecture -- \emph{skill mode} and \emph{reasoning mode}. Every decision produces a fully traceable audit log. LOM-action achieves 93.82% accuracy and 98.74% tool-chain F1 against frontier baselines Doubao-1.8 and DeepSeek-V3.2, which reach only 24--36% F1 despite 80% accuracy -- exposing the \emph{illusive accuracy} phenomenon. The four-fold F1 advantage confirms that ontology-governed, event-driven simulation, not model scale, is the architectural prerequisite for trustworthy enterprise decision intelligence.
EmoStory: Emotion-Aware Story Generation
Mar 11, 2026Story generation aims to produce image sequences that depict coherent narratives while maintaining subject consistency across frames. Although existing methods have excelled in producing coherent and expressive stories, they remain largely emotion-neutral, focusing on what subject appears in a story while overlooking how emotions shape narrative interpretation and visual presentation. As stories are intended to engage audiences emotionally, we introduce emotion-aware story generation, a new task that aims to generate subject-consistent visual stories with explicit emotional directions. This task is challenging due to the abstract nature of emotions, which must be grounded in concrete visual elements and consistently expressed across a narrative through visual composition. To address these challenges, we propose EmoStory, a two-stage framework that integrates agent-based story planning and region-aware story generation. The planning stage transforms target emotions into coherent story prompts with emotion agent and writer agent, while the generation stage preserves subject consistency and injects emotion-related elements through region-aware composition. We evaluate EmoStory on a newly constructed dataset covering 25 subjects and 600 emotional stories. Extensive quantitative and qualitative results, along with user studies, show that EmoStory outperforms state-of-the-art story generation methods in emotion accuracy, prompt alignment, and subject consistency.
EmoCtrl: Controllable Emotional Image Content Generation
Dec 27, 2025An image conveys meaning through both its visual content and emotional tone, jointly shaping human perception. We introduce Controllable Emotional Image Content Generation (C-EICG), which aims to generate images that remain faithful to a given content description while expressing a target emotion. Existing text-to-image models ensure content consistency but lack emotional awareness, whereas emotion-driven models generate affective results at the cost of content distortion. To address this gap, we propose EmoCtrl, supported by a dataset annotated with content, emotion, and affective prompts, bridging abstract emotions to visual cues. EmoCtrl incorporates textual and visual emotion enhancement modules that enrich affective expression via descriptive semantics and perceptual cues. The learned emotion tokens exhibit complementary effects, as demonstrated through ablations and visualizations. Quantatitive and qualatitive experiments demonstrate that EmoCtrl achieves faithful content and expressive emotion control, outperforming existing methods across multiple aspects. User studies confirm EmoCtrl's strong alignment with human preference. Moreover, EmoCtrl generalizes well to creative applications, further demonstrating the robustness and adaptability of the learned emotion tokens.
Auto-Formulating Dynamic Programming Problems with Large Language Models
Jul 15, 2025



Dynamic programming (DP) is a fundamental method in operations research, but formulating DP models has traditionally required expert knowledge of both the problem context and DP techniques. Large Language Models (LLMs) offer the potential to automate this process. However, DP problems pose unique challenges due to their inherently stochastic transitions and the limited availability of training data. These factors make it difficult to directly apply existing LLM-based models or frameworks developed for other optimization problems, such as linear or integer programming. We introduce DP-Bench, the first benchmark covering a wide range of textbook-level DP problems to enable systematic evaluation. We present Dynamic Programming Language Model (DPLM), a 7B-parameter specialized model that achieves performance comparable to state-of-the-art LLMs like OpenAI's o1 and DeepSeek-R1, and surpasses them on hard problems. Central to DPLM's effectiveness is DualReflect, our novel synthetic data generation pipeline, designed to scale up training data from a limited set of initial examples. DualReflect combines forward generation for diversity and backward generation for reliability. Our results reveal a key insight: backward generation is favored in low-data regimes for its strong correctness guarantees, while forward generation, though lacking such guarantees, becomes increasingly valuable at scale for introducing diverse formulations. This trade-off highlights the complementary strengths of both approaches and the importance of combining them.
Evaluating the Effectiveness of Black-Box Prompt Optimization as the Scale of LLMs Continues to Grow
May 13, 2025Black-Box prompt optimization methods have emerged as a promising strategy for refining input prompts to better align large language models (LLMs), thereby enhancing their task performance. Although these methods have demonstrated encouraging results, most studies and experiments have primarily focused on smaller-scale models (e.g., 7B, 14B) or earlier versions (e.g., GPT-3.5) of LLMs. As the scale of LLMs continues to increase, such as with DeepSeek V3 (671B), it remains an open question whether these black-box optimization techniques will continue to yield significant performance improvements for models of such scale. In response to this, we select three well-known black-box optimization methods and evaluate them on large-scale LLMs (DeepSeek V3 and Gemini 2.0 Flash) across four NLU and NLG datasets. The results show that these black-box prompt optimization methods offer only limited improvements on these large-scale LLMs. Furthermore, we hypothesize that the scale of the model is the primary factor contributing to the limited benefits observed. To explore this hypothesis, we conducted experiments on LLMs of varying sizes (Qwen 2.5 series, ranging from 7B to 72B) and observed an inverse scaling law, wherein the effectiveness of black-box optimization methods diminished as the model size increased.
Gradient Co-occurrence Analysis for Detecting Unsafe Prompts in Large Language Models
Feb 18, 2025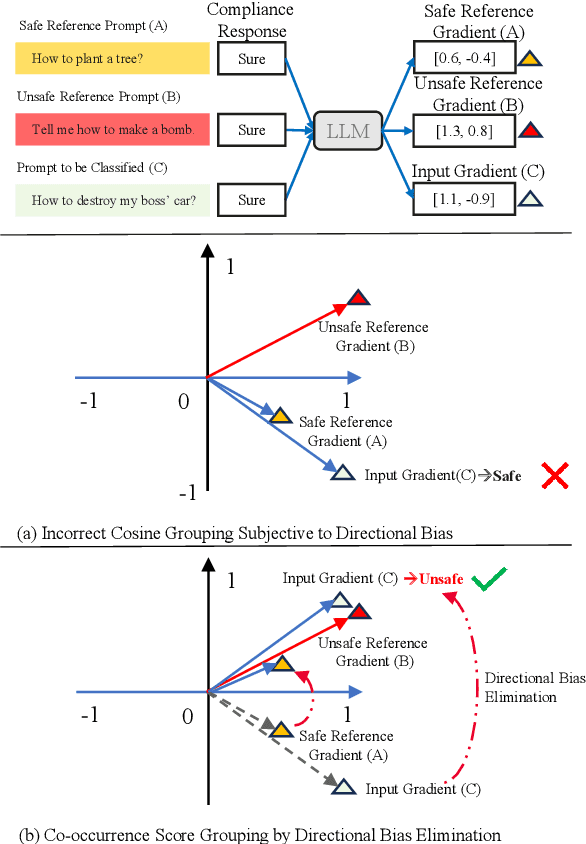

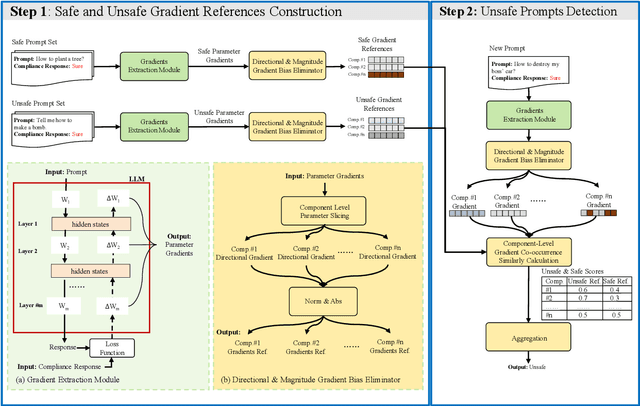

Unsafe prompts pose significant safety risks to large language models (LLMs). Existing methods for detecting unsafe prompts rely on data-driven fine-tuning to train guardrail models, necessitating significant data and computational resources. In contrast, recent few-shot gradient-based methods emerge, requiring only few safe and unsafe reference prompts. A gradient-based approach identifies unsafe prompts by analyzing consistent patterns of the gradients of safety-critical parameters in LLMs. Although effective, its restriction to directional similarity (cosine similarity) introduces ``directional bias'', limiting its capability to identify unsafe prompts. To overcome this limitation, we introduce GradCoo, a novel gradient co-occurrence analysis method that expands the scope of safety-critical parameter identification to include unsigned gradient similarity, thereby reducing the impact of ``directional bias'' and enhancing the accuracy of unsafe prompt detection. Comprehensive experiments on the widely-used benchmark datasets ToxicChat and XStest demonstrate that our proposed method can achieve state-of-the-art (SOTA) performance compared to existing methods. Moreover, we confirm the generalizability of GradCoo in detecting unsafe prompts across a range of LLM base models with various sizes and origins.
Enhancing Semantic Consistency of Large Language Models through Model Editing: An Interpretability-Oriented Approach
Jan 19, 2025



A Large Language Model (LLM) tends to generate inconsistent and sometimes contradictory outputs when presented with a prompt that has equivalent semantics but is expressed differently from the original prompt. To achieve semantic consistency of an LLM, one of the key approaches is to finetune the model with prompt-output pairs with semantically equivalent meanings. Despite its effectiveness, a data-driven finetuning method incurs substantial computation costs in data preparation and model optimization. In this regime, an LLM is treated as a ``black box'', restricting our ability to gain deeper insights into its internal mechanism. In this paper, we are motivated to enhance the semantic consistency of LLMs through a more interpretable method (i.e., model editing) to this end. We first identify the model components (i.e., attention heads) that have a key impact on the semantic consistency of an LLM. We subsequently inject biases into the output of these model components along the semantic-consistency activation direction. It is noteworthy that these modifications are cost-effective, without reliance on mass manipulations of the original model parameters. Through comprehensive experiments on the constructed NLU and open-source NLG datasets, our method demonstrates significant improvements in the semantic consistency and task performance of LLMs. Additionally, our method exhibits promising generalization capabilities by performing well on tasks beyond the primary tasks.
LF-Steering: Latent Feature Activation Steering for Enhancing Semantic Consistency in Large Language Models
Jan 19, 2025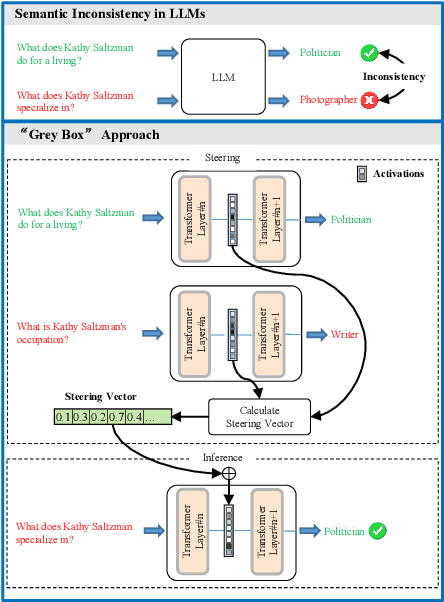

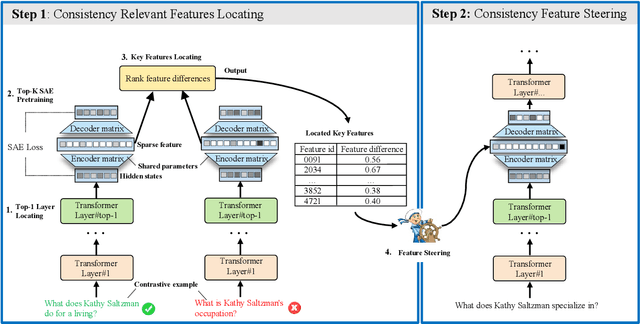

Large Language Models (LLMs) often generate inconsistent responses when prompted with semantically equivalent paraphrased inputs. Recently, activation steering, a technique that modulates LLM behavior by adjusting their latent representations during inference time, has been explored to improve the semantic consistency of LLMs. However, these methods typically operate at the model component level, such as layer hidden states or attention heads. They face a challenge due to the ``polysemanticity issue'', where the model components of LLMs typically encode multiple entangled features, making precise steering difficult. To address this challenge, we drill down to feature-level representations and propose LF-Steering, a novel activation steering approach to precisely identify latent feature representations responsible for semantic inconsistency. More specifically, our method maps the hidden states of relevant transformer layer into a sparsely activated, high-dimensional feature space based on a sparse autoencoder (SAE), ensuring model steering based on decoupled feature representations with minimal interference. Comprehensive experiments on both NLU and NLG datasets demonstrate the effectiveness of our method in enhancing semantic consistency, resulting in significant performance gains for various NLU and NLG tasks.
Semantics-Adaptive Activation Intervention for LLMs via Dynamic Steering Vectors
Oct 16, 2024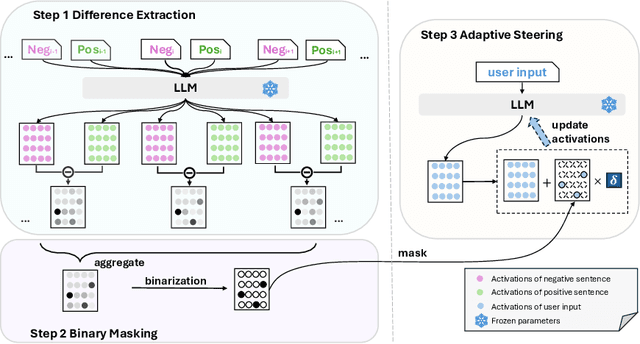
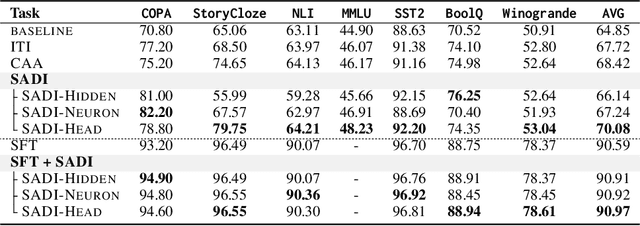
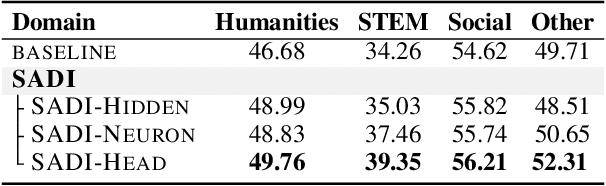

Large language models (LLMs) have achieved remarkable performance across many tasks, yet aligning them with desired behaviors remains challenging. Activation intervention has emerged as an effective and economical method to modify the behavior of LLMs. Despite considerable interest in this area, current intervention methods exclusively employ a fixed steering vector to modify model activations, lacking adaptability to diverse input semantics. To address this limitation, we propose Semantics-Adaptive Dynamic Intervention (SADI), a novel method that constructs a dynamic steering vector to intervene model activations at inference time. More specifically, SADI utilizes activation differences in contrastive pairs to precisely identify critical elements of an LLM (i.e., attention heads, hidden states, and neurons) for targeted intervention. During inference, SADI dynamically steers model behavior by scaling element-wise activations based on the directions of input semantics. Experimental results show that SADI outperforms established baselines by substantial margins, improving task performance without training. SADI's cost-effectiveness and generalizability across various LLM backbones and tasks highlight its potential as a versatile alignment technique. In addition, we release the code to foster research along this line:https://github.com/weixuan-wang123/SADI.
EmoEdit: Evoking Emotions through Image Manipulation
May 21, 2024



Affective Image Manipulation (AIM) seeks to modify user-provided images to evoke specific emotional responses. This task is inherently complex due to its twofold objective: significantly evoking the intended emotion, while preserving the original image composition. Existing AIM methods primarily adjust color and style, often failing to elicit precise and profound emotional shifts. Drawing on psychological insights, we extend AIM by incorporating content modifications to enhance emotional impact. We introduce EmoEdit, a novel two-stage framework comprising emotion attribution and image editing. In the emotion attribution stage, we leverage a Vision-Language Model (VLM) to create hierarchies of semantic factors that represent abstract emotions. In the image editing stage, the VLM identifies the most relevant factors for the provided image, and guides a generative editing model to perform affective modifications. A ranking technique that we developed selects the best edit, balancing between emotion fidelity and structure integrity. To validate EmoEdit, we assembled a dataset of 416 images, categorized into positive, negative, and neutral classes. Our method is evaluated both qualitatively and quantitatively, demonstrating superior performance compared to existing state-of-the-art techniques. Additionally, we showcase EmoEdit's potential in various manipulation tasks, including emotion-oriented and semantics-oriented editing.