 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepStock: Reinforcement Learning with Policy Regularizations for Inventory Management
Mar 20, 2026Deep Reinforcement Learning (DRL) provides a general-purpose methodology for training inventory policies that can leverage big data and compute. However, off-the-shelf implementations of DRL have seen mixed success, often plagued by high sensitivity to the hyperparameters used during training. In this paper, we show that by imposing policy regularizations, grounded in classical inventory concepts such as "Base Stock", we can significantly accelerate hyperparameter tuning and improve the final performance of several DRL methods. We report details from a 100% deployment of DRL with policy regularizations on Alibaba's e-commerce platform, Tmall. We also include extensive synthetic experiments, which show that policy regularizations reshape the narrative on what is the best DRL method for inventory management.
Auto-Formulating Dynamic Programming Problems with Large Language Models
Jul 15, 2025



Dynamic programming (DP) is a fundamental method in operations research, but formulating DP models has traditionally required expert knowledge of both the problem context and DP techniques. Large Language Models (LLMs) offer the potential to automate this process. However, DP problems pose unique challenges due to their inherently stochastic transitions and the limited availability of training data. These factors make it difficult to directly apply existing LLM-based models or frameworks developed for other optimization problems, such as linear or integer programming. We introduce DP-Bench, the first benchmark covering a wide range of textbook-level DP problems to enable systematic evaluation. We present Dynamic Programming Language Model (DPLM), a 7B-parameter specialized model that achieves performance comparable to state-of-the-art LLMs like OpenAI's o1 and DeepSeek-R1, and surpasses them on hard problems. Central to DPLM's effectiveness is DualReflect, our novel synthetic data generation pipeline, designed to scale up training data from a limited set of initial examples. DualReflect combines forward generation for diversity and backward generation for reliability. Our results reveal a key insight: backward generation is favored in low-data regimes for its strong correctness guarantees, while forward generation, though lacking such guarantees, becomes increasingly valuable at scale for introducing diverse formulations. This trade-off highlights the complementary strengths of both approaches and the importance of combining them.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
VC Theory for Inventory Policies
Apr 17, 2024

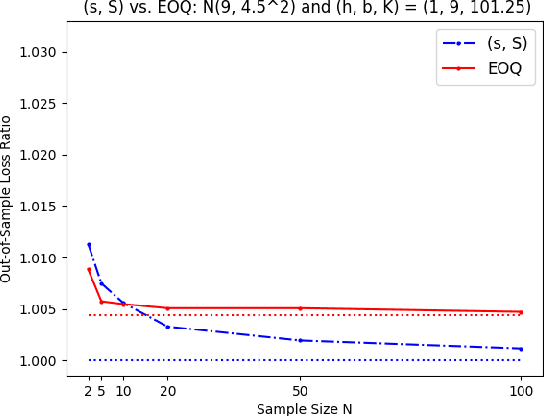

Advances in computational power and AI have increased interest in reinforcement learning approaches to inventory management. This paper provides a theoretical foundation for these approaches and investigates the benefits of restricting to policy structures that are well-established by decades of inventory theory. In particular, we prove generalization guarantees for learning several well-known classes of inventory policies, including base-stock and (s, S) policies, by leveraging the celebrated Vapnik-Chervonenkis (VC) theory. We apply the concepts of the Pseudo-dimension and Fat-shattering dimension from VC theory to determine the generalizability of inventory policies, that is, the difference between an inventory policy's performance on training data and its expected performance on unseen data. We focus on a classical setting without contexts, but allow for an arbitrary distribution over demand sequences and do not make any assumptions such as independence over time. We corroborate our supervised learning results using numerical simulations. Managerially, our theory and simulations translate to the following insights. First, there is a principle of "learning less is more" in inventory management: depending on the amount of data available, it may be beneficial to restrict oneself to a simpler, albeit suboptimal, class of inventory policies to minimize overfitting errors. Second, the number of parameters in a policy class may not be the correct measure of overfitting error: in fact, the class of policies defined by T time-varying base-stock levels exhibits a generalization error comparable to that of the two-parameter (s, S) policy class. Finally, our research suggests situations in which it could be beneficial to incorporate the concepts of base-stock and inventory position into black-box learning machines, instead of having these machines directly learn the order quantity actions.