 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepStock: Reinforcement Learning with Policy Regularizations for Inventory Management
Mar 20, 2026Deep Reinforcement Learning (DRL) provides a general-purpose methodology for training inventory policies that can leverage big data and compute. However, off-the-shelf implementations of DRL have seen mixed success, often plagued by high sensitivity to the hyperparameters used during training. In this paper, we show that by imposing policy regularizations, grounded in classical inventory concepts such as "Base Stock", we can significantly accelerate hyperparameter tuning and improve the final performance of several DRL methods. We report details from a 100% deployment of DRL with policy regularizations on Alibaba's e-commerce platform, Tmall. We also include extensive synthetic experiments, which show that policy regularizations reshape the narrative on what is the best DRL method for inventory management.
AI Agents for Inventory Control: Human-LLM-OR Complementarity
Feb 13, 2026Inventory control is a fundamental operations problem in which ordering decisions are traditionally guided by theoretically grounded operations research (OR) algorithms. However, such algorithms often rely on rigid modeling assumptions and can perform poorly when demand distributions shift or relevant contextual information is unavailable. Recent advances in large language models (LLMs) have generated interest in AI agents that can reason flexibly and incorporate rich contextual signals, but it remains unclear how best to incorporate LLM-based methods into traditional decision-making pipelines. We study how OR algorithms, LLMs, and humans can interact and complement each other in a multi-period inventory control setting. We construct InventoryBench, a benchmark of over 1,000 inventory instances spanning both synthetic and real-world demand data, designed to stress-test decision rules under demand shifts, seasonality, and uncertain lead times. Through this benchmark, we find that OR-augmented LLM methods outperform either method in isolation, suggesting that these methods are complementary rather than substitutes. We further investigate the role of humans through a controlled classroom experiment that embeds LLM recommendations into a human-in-the-loop decision pipeline. Contrary to prior findings that human-AI collaboration can degrade performance, we show that, on average, human-AI teams achieve higher profits than either humans or AI agents operating alone. Beyond this population-level finding, we formalize an individual-level complementarity effect and derive a distribution-free lower bound on the fraction of individuals who benefit from AI collaboration; empirically, we find this fraction to be substantial.
Evaluating LLM-persona Generated Distributions for Decision-making
Feb 06, 2026LLMs can generate a wealth of data, ranging from simulated personas imitating human valuations and preferences, to demand forecasts based on world knowledge. But how well do such LLM-generated distributions support downstream decision-making? For example, when pricing a new product, a firm could prompt an LLM to simulate how much consumers are willing to pay based on a product description, but how useful is the resulting distribution for optimizing the price? We refer to this approach as LLM-SAA, in which an LLM is used to construct an estimated distribution and the decision is then optimized under that distribution. In this paper, we study metrics to evaluate the quality of these LLM-generated distributions, based on the decisions they induce. Taking three canonical decision-making problems (assortment optimization, pricing, and newsvendor) as examples, we find that LLM-generated distributions are practically useful, especially in low-data regimes. We also show that decision-agnostic metrics such as Wasserstein distance can be misleading when evaluating these distributions for decision-making.
Optimal Bayesian Stopping for Efficient Inference of Consistent LLM Answers
Feb 05, 2026A simple strategy for improving LLM accuracy, especially in math and reasoning problems, is to sample multiple responses and submit the answer most consistently reached. In this paper we leverage Bayesian prior information to save on sampling costs, stopping once sufficient consistency is reached. Although the exact posterior is computationally intractable, we further introduce an efficient "L-aggregated" stopping policy that tracks only the L-1 most frequent answer counts. Theoretically, we prove that L=3 is all you need: this coarse approximation is sufficient to achieve asymptotic optimality, and strictly dominates prior-free baselines, while having a fast posterior computation. Empirically, this identifies the most consistent (i.e., mode) LLM answer using fewer samples, and can achieve similar answer accuracy while cutting the number of LLM calls (i.e., saving on LLM inference costs) by up to 50%.
Fair Secretaries with Unfair Predictions
Nov 15, 2024
Algorithms with predictions is a recent framework for decision-making under uncertainty that leverages the power of machine-learned predictions without making any assumption about their quality. The goal in this framework is for algorithms to achieve an improved performance when the predictions are accurate while maintaining acceptable guarantees when the predictions are erroneous. A serious concern with algorithms that use predictions is that these predictions can be biased and, as a result, cause the algorithm to make decisions that are deemed unfair. We show that this concern manifests itself in the classical secretary problem in the learning-augmented setting -- the state-of-the-art algorithm can have zero probability of accepting the best candidate, which we deem unfair, despite promising to accept a candidate whose expected value is at least $\max\{\Omega (1) , 1 - O(\epsilon)\}$ times the optimal value, where $\epsilon$ is the prediction error. We show how to preserve this promise while also guaranteeing to accept the best candidate with probability $\Omega(1)$. Our algorithm and analysis are based on a new "pegging" idea that diverges from existing works and simplifies/unifies some of their results. Finally, we extend to the $k$-secretary problem and complement our theoretical analysis with experiments.
Survey of Data-driven Newsvendor: Unified Analysis and Spectrum of Achievable Regrets
Sep 05, 2024
In the Newsvendor problem, the goal is to guess the number that will be drawn from some distribution, with asymmetric consequences for guessing too high vs. too low. In the data-driven version, the distribution is unknown, and one must work with samples from the distribution. Data-driven Newsvendor has been studied under many variants: additive vs. multiplicative regret, high probability vs. expectation bounds, and different distribution classes. This paper studies all combinations of these variants, filling in many gaps in the literature and simplifying many proofs. In particular, we provide a unified analysis based on the notion of clustered distributions, which in conjunction with our new lower bounds, shows that the entire spectrum of regrets between $1/\sqrt{n}$ and $1/n$ can be possible.
VC Theory for Inventory Policies
Apr 17, 2024

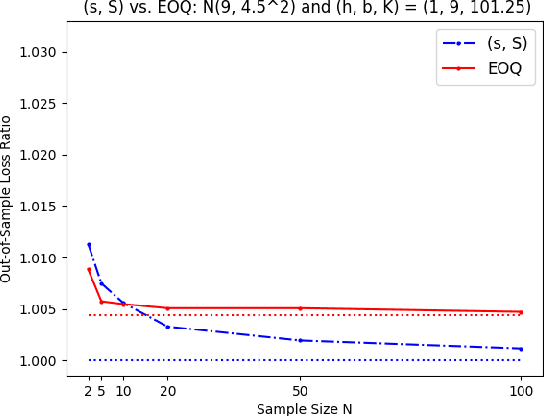

Advances in computational power and AI have increased interest in reinforcement learning approaches to inventory management. This paper provides a theoretical foundation for these approaches and investigates the benefits of restricting to policy structures that are well-established by decades of inventory theory. In particular, we prove generalization guarantees for learning several well-known classes of inventory policies, including base-stock and (s, S) policies, by leveraging the celebrated Vapnik-Chervonenkis (VC) theory. We apply the concepts of the Pseudo-dimension and Fat-shattering dimension from VC theory to determine the generalizability of inventory policies, that is, the difference between an inventory policy's performance on training data and its expected performance on unseen data. We focus on a classical setting without contexts, but allow for an arbitrary distribution over demand sequences and do not make any assumptions such as independence over time. We corroborate our supervised learning results using numerical simulations. Managerially, our theory and simulations translate to the following insights. First, there is a principle of "learning less is more" in inventory management: depending on the amount of data available, it may be beneficial to restrict oneself to a simpler, albeit suboptimal, class of inventory policies to minimize overfitting errors. Second, the number of parameters in a policy class may not be the correct measure of overfitting error: in fact, the class of policies defined by T time-varying base-stock levels exhibits a generalization error comparable to that of the two-parameter (s, S) policy class. Finally, our research suggests situations in which it could be beneficial to incorporate the concepts of base-stock and inventory position into black-box learning machines, instead of having these machines directly learn the order quantity actions.
Quality vs. Quantity of Data in Contextual Decision-Making: Exact Analysis under Newsvendor Loss
Feb 16, 2023When building datasets, one needs to invest time, money and energy to either aggregate more data or to improve their quality. The most common practice favors quantity over quality without necessarily quantifying the trade-off that emerges. In this work, we study data-driven contextual decision-making and the performance implications of quality and quantity of data. We focus on contextual decision-making with a Newsvendor loss. This loss is that of a central capacity planning problem in Operations Research, but also that associated with quantile regression. We consider a model in which outcomes observed in similar contexts have similar distributions and analyze the performance of a classical class of kernel policies which weigh data according to their similarity in a contextual space. We develop a series of results that lead to an exact characterization of the worst-case expected regret of these policies. This exact characterization applies to any sample size and any observed contexts. The model we develop is flexible, and captures the case of partially observed contexts. This exact analysis enables to unveil new structural insights on the learning behavior of uniform kernel methods: i) the specialized analysis leads to very large improvements in quantification of performance compared to state of the art general purpose bounds. ii) we show an important non-monotonicity of the performance as a function of data size not captured by previous bounds; and iii) we show that in some regimes, a little increase in the quality of the data can dramatically reduce the amount of samples required to reach a performance target. All in all, our work demonstrates that it is possible to quantify in a precise fashion the interplay of data quality and quantity, and performance in a central problem class. It also highlights the need for problem specific bounds in order to understand the trade-offs at play.
Degeneracy is OK: Logarithmic Regret for Network Revenue Management with Indiscrete Distributions
Oct 14, 2022We study the classical Network Revenue Management (NRM) problem with accept/reject decisions and $T$ IID arrivals. We consider a distributional form where each arrival must fall under a finite number of possible categories, each with a deterministic resource consumption vector, but a random value distributed continuously over an interval. We develop an online algorithm that achieves $O(\log^2 T)$ regret under this model, with no further assumptions. We develop another online algorithm that achieves an improved $O(\log T)$ regret, with only a second-order growth assumption. To our knowledge, these are the first results achieving logarithmic-level regret in a continuous-distribution NRM model without further ``non-degeneracy'' assumptions. Our results are achieved via new techniques including: a new method of bounding myopic regret, a ``semi-fluid'' relaxation of the offline allocation, and an improved bound on the ``dual convergence''.
Beyond IID: data-driven decision-making in heterogeneous environments
Jun 20, 2022
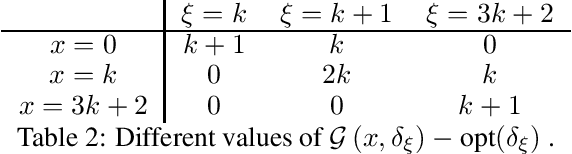
In this work, we study data-driven decision-making and depart from the classical identically and independently distributed (i.i.d.) assumption. We present a new framework in which historical samples are generated from unknown and different distributions, which we dub heterogeneous environments. These distributions are assumed to lie in a heterogeneity ball with known radius and centered around the (also) unknown future (out-of-sample) distribution on which the performance of a decision will be evaluated. We quantify the asymptotic worst-case regret that is achievable by central data-driven policies such as Sample Average Approximation, but also by rate-optimal ones, as a function of the radius of the heterogeneity ball. Our work shows that the type of achievable performance varies considerably across different combinations of problem classes and notions of heterogeneity. We demonstrate the versatility of our framework by comparing achievable guarantees for the heterogeneous version of widely studied data-driven problems such as pricing, ski-rental, and newsvendor. En route, we establish a new connection between data-driven decision-making and distributionally robust optimization.