 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Deep Learning Meets Polyhedral Theory: A Survey
Apr 29, 2023In the past decade, deep learning became the prevalent methodology for predictive modeling thanks to the remarkable accuracy of deep neural networks in tasks such as computer vision and natural language processing. Meanwhile, the structure of neural networks converged back to simpler representations based on piecewise constant and piecewise linear functions such as the Rectified Linear Unit (ReLU), which became the most commonly used type of activation function in neural networks. That made certain types of network structure $\unicode{x2014}$such as the typical fully-connected feedforward neural network$\unicode{x2014}$ amenable to analysis through polyhedral theory and to the application of methodologies such as Linear Programming (LP) and Mixed-Integer Linear Programming (MILP) for a variety of purposes. In this paper, we survey the main topics emerging from this fast-paced area of work, which bring a fresh perspective to understanding neural networks in more detail as well as to applying linear optimization techniques to train, verify, and reduce the size of such networks.
Neural Network Verification as Piecewise Linear Optimization: Formulations for the Composition of Staircase Functions
Nov 27, 2022



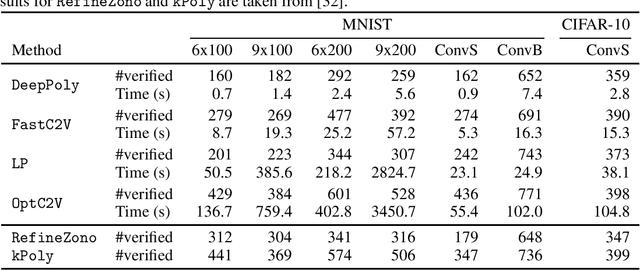
We present a technique for neural network verification using mixed-integer programming (MIP) formulations. We derive a \emph{strong formulation} for each neuron in a network using piecewise linear activation functions. Additionally, as in general, these formulations may require an exponential number of inequalities, we also derive a separation procedure that runs in super-linear time in the input dimension. We first introduce and develop our technique on the class of \emph{staircase} functions, which generalizes the ReLU, binarized, and quantized activation functions. We then use results for staircase activation functions to obtain a separation method for general piecewise linear activation functions. Empirically, using our strong formulation and separation technique, we can reduce the computational time in exact verification settings based on MIP and improve the false negative rate for inexact verifiers relying on the relaxation of the MIP formulation.
The Convex Relaxation Barrier, Revisited: Tightened Single-Neuron Relaxations for Neural Network Verification
Jun 24, 2020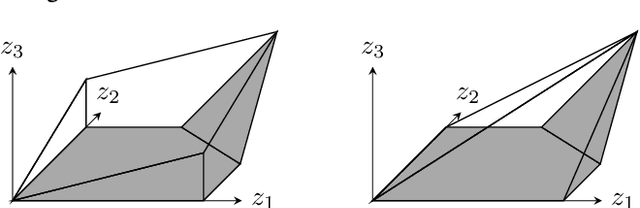
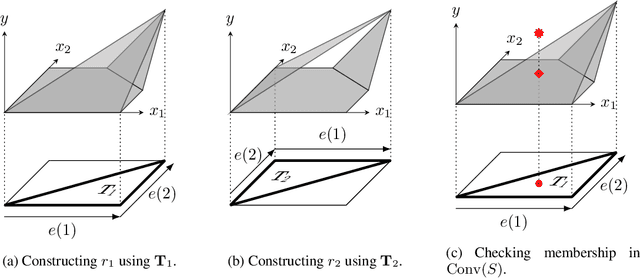
We improve the effectiveness of propagation- and linear-optimization-based neural network verification algorithms with a new tightened convex relaxation for ReLU neurons. Unlike previous single-neuron relaxations which focus only on the univariate input space of the ReLU, our method considers the multivariate input space of the affine pre-activation function preceding the ReLU. Using results from submodularity and convex geometry, we derive an explicit description of the tightest possible convex relaxation when this multivariate input is over a box domain. We show that our convex relaxation is significantly stronger than the commonly used univariate-input relaxation which has been proposed as a natural convex relaxation barrier for verification. While our description of the relaxation may require an exponential number of inequalities, we show that they can be separated in linear time and hence can be efficiently incorporated into optimization algorithms on an as-needed basis. Based on this novel relaxation, we design two polynomial-time algorithms for neural network verification: a linear-programming-based algorithm that leverages the full power of our relaxation, and a fast propagation algorithm that generalizes existing approaches. In both cases, we show that for a modest increase in computational effort, our strengthened relaxation enables us to verify a significantly larger number of instances compared to similar algorithms.
Contextual Reserve Price Optimization in Auctions
Feb 20, 2020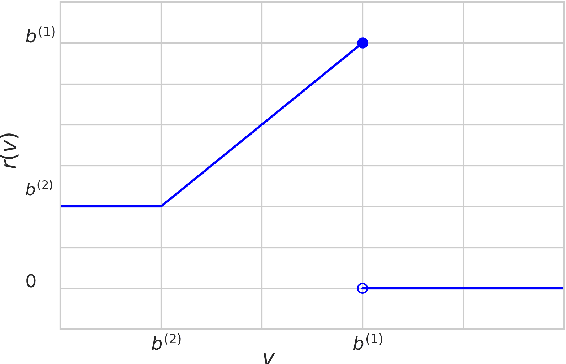
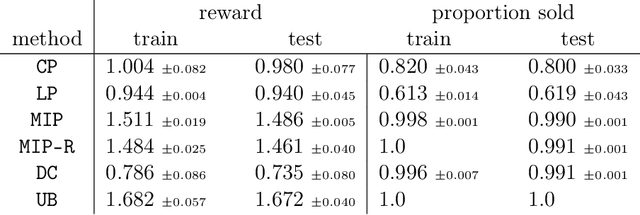
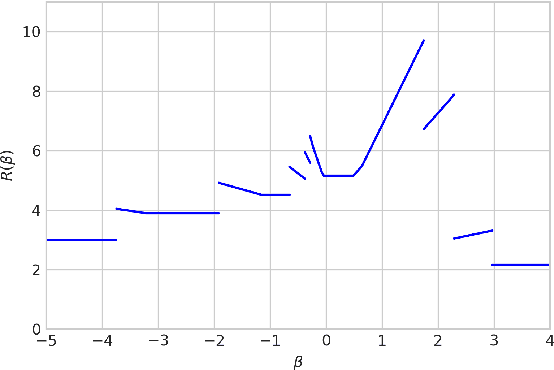
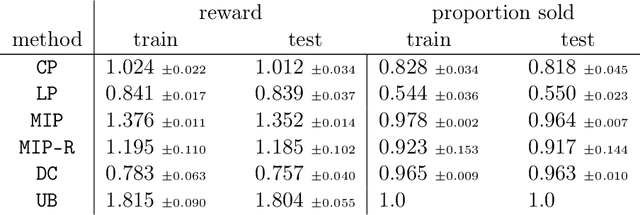
We study the problem of learning a linear model to set the reserve price in order to maximize expected revenue in an auction, given contextual information. First, we show that it is not possible to solve this problem in polynomial time unless the \emph{Exponential Time Hypothesis} fails. Second, we present a strong mixed-integer programming (MIP) formulation for this problem, which is capable of exactly modeling the nonconvex and discontinuous expected reward function. Moreover, we show that this MIP formulation is ideal (the strongest possible formulation) for the revenue function. Since it can be computationally expensive to exactly solve the MIP formulation, we also study the performance of its linear programming (LP) relaxation. We show that, unfortunately, in the worst case the objective gap of the linear programming relaxation can be $O(n)$ times larger than the optimal objective of the actual problem, where $n$ is the number of samples. Finally, we present computational results, showcasing that the mixed-integer programming formulation, along with its linear programming relaxation, are able to superior both the in-sample performance and the out-of-sample performance of the state-of-the-art algorithms on both real and synthetic datasets.
Strong mixed-integer programming formulations for trained neural networks
Nov 20, 2018

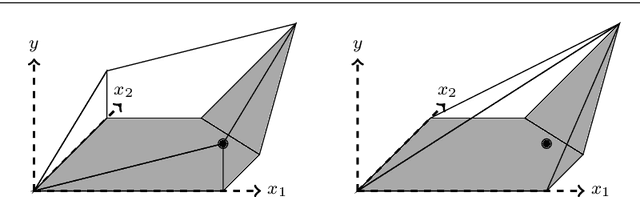

We present an ideal mixed-integer programming (MIP) formulation for a rectified linear unit (ReLU) appearing in a trained neural network. Our formulation requires a single binary variable and no additional continuous variables beyond the input and output variables of the ReLU. We contrast it with an ideal "extended" formulation with a linear number of additional continuous variables, derived through standard techniques. An apparent drawback of our formulation is that it requires an exponential number of inequality constraints, but we provide a routine to separate the inequalities in linear time. We also prove that these exponentially-many constraints are facet-defining under mild conditions. Finally, we present computational results showing that dynamically separating from the exponential inequalities 1) is much more computationally efficient and scalable than the extended formulation, 2) decreases the solve time of a state-of-the-art MIP solver by a factor of 7 on smaller instances, and 3) nearly matches the dual bounds of a state-of-the-art MIP solver on harder instances, after just a few rounds of separation and in orders of magnitude less time.