 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the Value of Censored Data? An Exact Analysis for the Data-driven Newsvendor
Feb 18, 2026We study the offline data-driven newsvendor problem with censored demand data. In contrast to prior works where demand is fully observed, we consider the setting where demand is censored at the inventory level and only sales are observed; sales match demand when there is sufficient inventory, and equal the available inventory otherwise. We provide a general procedure to compute the exact worst-case regret of classical data-driven inventory policies, evaluated over all demand distributions. Our main technical result shows that this infinite-dimensional, non-convex optimization problem can be reduced to a finite-dimensional one, enabling an exact characterization of the performance of policies for any sample size and censoring levels. We leverage this reduction to derive sharp insights on the achievable performance of standard inventory policies under demand censoring. In particular, our analysis of the Kaplan-Meier policy shows that while demand censoring fundamentally limits what can be learned from passive sales data, just a small amount of targeted exploration at high inventory levels can substantially improve worst-case guarantees, enabling near-optimal performance even under heavy censoring. In contrast, when the point-of-sale system does not record stockout events and only reports realized sales, a natural and commonly used approach is to treat sales as demand. Our results show that policies based on this sales-as-demand heuristic can suffer severe performance degradation as censored data accumulates, highlighting how the quality of point-of-sale information critically shapes what can, and cannot, be learned offline.
Auction Design using Value Prediction with Hallucinations
Feb 12, 2025We investigate a Bayesian mechanism design problem where a seller seeks to maximize revenue by selling an indivisible good to one of n buyers, incorporating potentially unreliable predictions (signals) of buyers' private values derived from a machine learning model. We propose a framework where these signals are sometimes reflective of buyers' true valuations but other times are hallucinations, which are uncorrelated with the buyers' true valuations. Our main contribution is a characterization of the optimal auction under this framework. Our characterization establishes a near-decomposition of how to treat types above and below the signal. For the one buyer case, the seller's optimal strategy is to post one of three fairly intuitive prices depending on the signal, which we call the "ignore", "follow" and "cap" actions.
Quality vs. Quantity of Data in Contextual Decision-Making: Exact Analysis under Newsvendor Loss
Feb 16, 2023When building datasets, one needs to invest time, money and energy to either aggregate more data or to improve their quality. The most common practice favors quantity over quality without necessarily quantifying the trade-off that emerges. In this work, we study data-driven contextual decision-making and the performance implications of quality and quantity of data. We focus on contextual decision-making with a Newsvendor loss. This loss is that of a central capacity planning problem in Operations Research, but also that associated with quantile regression. We consider a model in which outcomes observed in similar contexts have similar distributions and analyze the performance of a classical class of kernel policies which weigh data according to their similarity in a contextual space. We develop a series of results that lead to an exact characterization of the worst-case expected regret of these policies. This exact characterization applies to any sample size and any observed contexts. The model we develop is flexible, and captures the case of partially observed contexts. This exact analysis enables to unveil new structural insights on the learning behavior of uniform kernel methods: i) the specialized analysis leads to very large improvements in quantification of performance compared to state of the art general purpose bounds. ii) we show an important non-monotonicity of the performance as a function of data size not captured by previous bounds; and iii) we show that in some regimes, a little increase in the quality of the data can dramatically reduce the amount of samples required to reach a performance target. All in all, our work demonstrates that it is possible to quantify in a precise fashion the interplay of data quality and quantity, and performance in a central problem class. It also highlights the need for problem specific bounds in order to understand the trade-offs at play.
Beyond IID: data-driven decision-making in heterogeneous environments
Jun 20, 2022
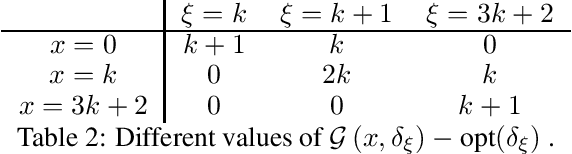
In this work, we study data-driven decision-making and depart from the classical identically and independently distributed (i.i.d.) assumption. We present a new framework in which historical samples are generated from unknown and different distributions, which we dub heterogeneous environments. These distributions are assumed to lie in a heterogeneity ball with known radius and centered around the (also) unknown future (out-of-sample) distribution on which the performance of a decision will be evaluated. We quantify the asymptotic worst-case regret that is achievable by central data-driven policies such as Sample Average Approximation, but also by rate-optimal ones, as a function of the radius of the heterogeneity ball. Our work shows that the type of achievable performance varies considerably across different combinations of problem classes and notions of heterogeneity. We demonstrate the versatility of our framework by comparing achievable guarantees for the heterogeneous version of widely studied data-driven problems such as pricing, ski-rental, and newsvendor. En route, we establish a new connection between data-driven decision-making and distributionally robust optimization.