 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Task-based Performance Bounds for Accelerated MRI Image Reconstruction Methods by Use of Learned-Ideal Observers
Jan 16, 2025



Medical imaging systems are commonly assessed and optimized by the use of objective measures of image quality (IQ). The performance of the ideal observer (IO) acting on imaging measurements has long been advocated as a figure-of-merit to guide the optimization of imaging systems. For computed imaging systems, the performance of the IO acting on imaging measurements also sets an upper bound on task-performance that no image reconstruction method can transcend. As such, estimation of IO performance can provide valuable guidance when designing under-sampled data-acquisition techniques by enabling the identification of designs that will not permit the reconstruction of diagnostically inappropriate images for a specified task - no matter how advanced the reconstruction method is or how plausible the reconstructed images appear. The need for such analysis is urgent because of the substantial increase of medical device submissions on deep learning-based image reconstruction methods and the fact that they may produce clean images disguising the potential loss of diagnostic information when data is aggressively under-sampled. Recently, convolutional neural network (CNN) approximated IOs (CNN-IOs) was investigated for estimating the performance of data space IOs to establish task-based performance bounds for image reconstruction, under an X-ray computed tomographic (CT) context. In this work, the application of such data space CNN-IO analysis to multi-coil magnetic resonance imaging (MRI) systems has been explored. This study utilized stylized multi-coil sensitivity encoding (SENSE) MRI systems and deep-generated stochastic brain models to demonstrate the approach. Signal-known-statistically and background-known-statistically (SKS/BKS) binary signal detection tasks were selected to study the impact of different acceleration factors on the data space IO performance.
DuDoUniNeXt: Dual-domain unified hybrid model for single and multi-contrast undersampled MRI reconstruction
Mar 08, 2024



Multi-contrast (MC) Magnetic Resonance Imaging (MRI) reconstruction aims to incorporate a reference image of auxiliary modality to guide the reconstruction process of the target modality. Known MC reconstruction methods perform well with a fully sampled reference image, but usually exhibit inferior performance, compared to single-contrast (SC) methods, when the reference image is missing or of low quality. To address this issue, we propose DuDoUniNeXt, a unified dual-domain MRI reconstruction network that can accommodate to scenarios involving absent, low-quality, and high-quality reference images. DuDoUniNeXt adopts a hybrid backbone that combines CNN and ViT, enabling specific adjustment of image domain and k-space reconstruction. Specifically, an adaptive coarse-to-fine feature fusion module (AdaC2F) is devised to dynamically process the information from reference images of varying qualities. Besides, a partially shared shallow feature extractor (PaSS) is proposed, which uses shared and distinct parameters to handle consistent and discrepancy information among contrasts. Experimental results demonstrate that the proposed model surpasses state-of-the-art SC and MC models significantly. Ablation studies show the effectiveness of the proposed hybrid backbone, AdaC2F, PaSS, and the dual-domain unified learning scheme.
O-PRESS: Boosting OCT axial resolution with Prior guidance, Recurrence, and Equivariant Self-Supervision
Jan 06, 2024



Optical coherence tomography (OCT) is a noninvasive technology that enables real-time imaging of tissue microanatomies. The axial resolution of OCT is intrinsically constrained by the spectral bandwidth of the employed light source while maintaining a fixed center wavelength for a specific application. Physically extending this bandwidth faces strong limitations and requires a substantial cost. We present a novel computational approach, called as O-PRESS, for boosting the axial resolution of OCT with Prior Guidance, a Recurrent mechanism, and Equivariant Self-Supervision. Diverging from conventional superresolution methods that rely on physical models or data-driven techniques, our method seamlessly integrates OCT modeling and deep learning, enabling us to achieve real-time axial-resolution enhancement exclusively from measurements without a need for paired images. Our approach solves two primary tasks of resolution enhancement and noise reduction with one treatment. Both tasks are executed in a self-supervised manner, with equivariance imaging and free space priors guiding their respective processes. Experimental evaluations, encompassing both quantitative metrics and visual assessments, consistently verify the efficacy and superiority of our approach, which exhibits performance on par with fully supervised methods. Importantly, the robustness of our model is affirmed, showcasing its dual capability to enhance axial resolution while concurrently improving the signal-to-noise ratio.
Unified Multi-Modal Image Synthesis for Missing Modality Imputation
Apr 11, 2023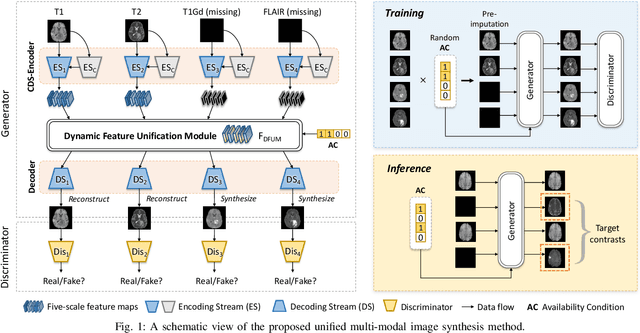


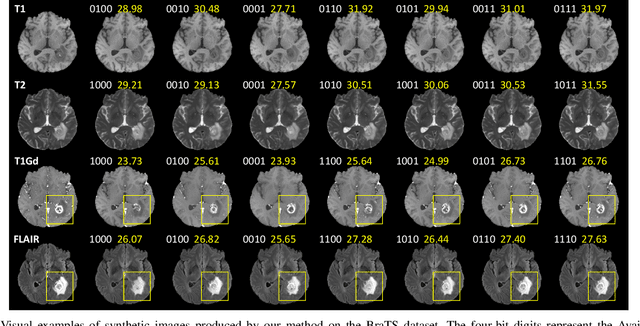
Multi-modal medical images provide complementary soft-tissue characteristics that aid in the screening and diagnosis of diseases. However, limited scanning time, image corruption and various imaging protocols often result in incomplete multi-modal images, thus limiting the usage of multi-modal data for clinical purposes. To address this issue, in this paper, we propose a novel unified multi-modal image synthesis method for missing modality imputation. Our method overall takes a generative adversarial architecture, which aims to synthesize missing modalities from any combination of available ones with a single model. To this end, we specifically design a Commonality- and Discrepancy-Sensitive Encoder for the generator to exploit both modality-invariant and specific information contained in input modalities. The incorporation of both types of information facilitates the generation of images with consistent anatomy and realistic details of the desired distribution. Besides, we propose a Dynamic Feature Unification Module to integrate information from a varying number of available modalities, which enables the network to be robust to random missing modalities. The module performs both hard integration and soft integration, ensuring the effectiveness of feature combination while avoiding information loss. Verified on two public multi-modal magnetic resonance datasets, the proposed method is effective in handling various synthesis tasks and shows superior performance compared to previous methods.
On the impact of incorporating task-information in learning-based image denoising
Nov 23, 2022A variety of deep neural network (DNN)-based image denoising methods have been proposed for use with medical images. These methods are typically trained by minimizing loss functions that quantify a distance between the denoised image, or a transformed version of it, and the defined target image (e.g., a noise-free or low-noise image). They have demonstrated high performance in terms of traditional image quality metrics such as root mean square error (RMSE), structural similarity index measure (SSIM), or peak signal-to-noise ratio (PSNR). However, it has been reported recently that such denoising methods may not always improve objective measures of image quality. In this work, a task-informed DNN-based image denoising method was established and systematically evaluated. A transfer learning approach was employed, in which the DNN is first pre-trained by use of a conventional (non-task-informed) loss function and subsequently fine-tuned by use of the hybrid loss that includes a task-component. The task-component was designed to measure the performance of a numerical observer (NO) on a signal detection task. The impact of network depth and constraining the fine-tuning to specific layers of the DNN was explored. The task-informed training method was investigated in a stylized low-dose X-ray computed tomography (CT) denoising study for which binary signal detection tasks under signal-known-statistically (SKS) with background-known-statistically (BKS) conditions were considered. The impact of changing the specified task at inference time to be different from that employed for model training, a phenomenon we refer to as "task-shift", was also investigated. The presented results indicate that the task-informed training method can improve observer performance while providing control over the trade off between traditional and task-based measures of image quality.
Supervised Learning-Enabled Ideal Observer Approximation for Joint Detection and Estimation Tasks
Oct 22, 2021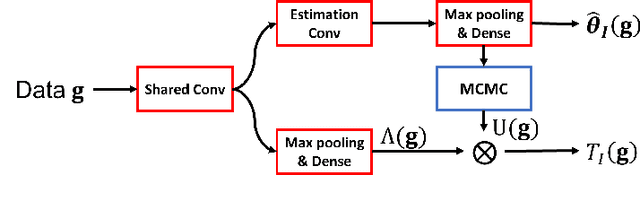
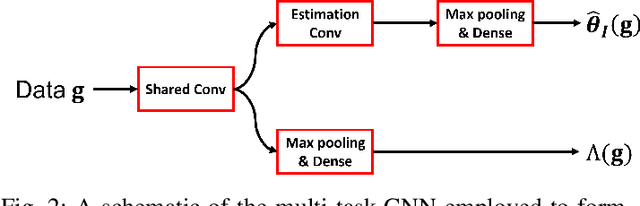


The ideal observer (IO) sets an upper performance limit among all observers and has been advocated for assessing and optimizing imaging systems. For general joint detection and estimation (detection-estimation) tasks, estimation ROC (EROC) analysis has been established for evaluating the performance of observers. However, in general, it is difficult to accurately approximate the IO that maximizes the area under the EROC curve. In this study, a hybrid method that employs machine learning is proposed to accomplish this. Specifically, a hybrid approach is developed that combines a multi-task convolutional neural network and a Markov-Chain Monte Carlo (MCMC) method in order to approximate the IO for detection-estimation tasks. In addition, a purely supervised learning-based sub-ideal observer is proposed. Computer-simulation studies are conducted to validate the proposed method, which include signal-known-statistically/background-known-exactly and signal-known-statistically/background-known-statistically tasks. The EROC curves produced by the proposed method are compared to those produced by the MCMC approach or analytical computation when feasible. The proposed method provides a new approach for approximating the IO and may advance the application of EROC analysis for optimizing imaging systems.
Assessing the Impact of Deep Neural Network-based Image Denoising on Binary Signal Detection Tasks
Apr 28, 2021



A variety of deep neural network (DNN)-based image denoising methods have been proposed for use with medical images. Traditional measures of image quality (IQ) have been employed to optimize and evaluate these methods. However, the objective evaluation of IQ for the DNN-based denoising methods remains largely lacking. In this work, we evaluate the performance of DNN-based denoising methods by use of task-based IQ measures. Specifically, binary signal detection tasks under signal-known-exactly (SKE) with background-known-statistically (BKS) conditions are considered. The performance of the ideal observer (IO) and common linear numerical observers are quantified and detection efficiencies are computed to assess the impact of the denoising operation on task performance. The numerical results indicate that, in the cases considered, the application of a denoising network can result in a loss of task-relevant information in the image. The impact of the depth of the denoising networks on task performance is also assessed. The presented results highlight the need for the objective evaluation of IQ for DNN-based denoising technologies and may suggest future avenues for improving their effectiveness in medical imaging applications.