 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO-PRESS: Boosting OCT axial resolution with Prior guidance, Recurrence, and Equivariant Self-Supervision
Jan 06, 2024



Optical coherence tomography (OCT) is a noninvasive technology that enables real-time imaging of tissue microanatomies. The axial resolution of OCT is intrinsically constrained by the spectral bandwidth of the employed light source while maintaining a fixed center wavelength for a specific application. Physically extending this bandwidth faces strong limitations and requires a substantial cost. We present a novel computational approach, called as O-PRESS, for boosting the axial resolution of OCT with Prior Guidance, a Recurrent mechanism, and Equivariant Self-Supervision. Diverging from conventional superresolution methods that rely on physical models or data-driven techniques, our method seamlessly integrates OCT modeling and deep learning, enabling us to achieve real-time axial-resolution enhancement exclusively from measurements without a need for paired images. Our approach solves two primary tasks of resolution enhancement and noise reduction with one treatment. Both tasks are executed in a self-supervised manner, with equivariance imaging and free space priors guiding their respective processes. Experimental evaluations, encompassing both quantitative metrics and visual assessments, consistently verify the efficacy and superiority of our approach, which exhibits performance on par with fully supervised methods. Importantly, the robustness of our model is affirmed, showcasing its dual capability to enhance axial resolution while concurrently improving the signal-to-noise ratio.
Dirichlet Energy Enhancement of Graph Neural Networks by Framelet Augmentation
Nov 09, 2023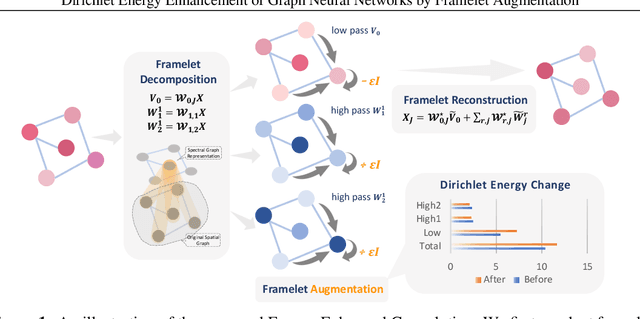
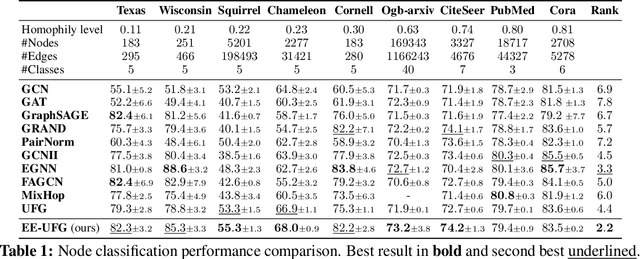
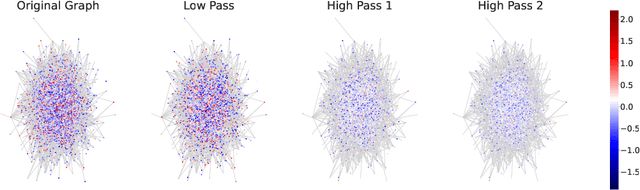
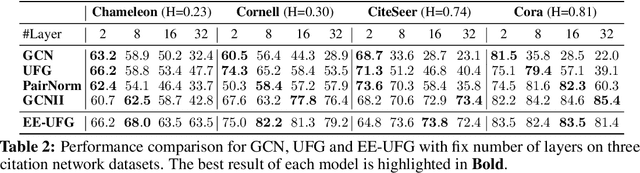
Graph convolutions have been a pivotal element in learning graph representations. However, recursively aggregating neighboring information with graph convolutions leads to indistinguishable node features in deep layers, which is known as the over-smoothing issue. The performance of graph neural networks decays fast as the number of stacked layers increases, and the Dirichlet energy associated with the graph decreases to zero as well. In this work, we introduce a framelet system into the analysis of Dirichlet energy and take a multi-scale perspective to leverage the Dirichlet energy and alleviate the over-smoothing issue. Specifically, we develop a Framelet Augmentation strategy by adjusting the update rules with positive and negative increments for low-pass and high-passes respectively. Based on that, we design the Energy Enhanced Convolution (EEConv), which is an effective and practical operation that is proved to strictly enhance Dirichlet energy. From a message-passing perspective, EEConv inherits multi-hop aggregation property from the framelet transform and takes into account all hops in the multi-scale representation, which benefits the node classification tasks over heterophilous graphs. Experiments show that deep GNNs with EEConv achieve state-of-the-art performance over various node classification datasets, especially for heterophilous graphs, while also lifting the Dirichlet energy as the network goes deeper.
ACMP: Allen-Cahn Message Passing for Graph Neural Networks with Particle Phase Transition
Jun 11, 2022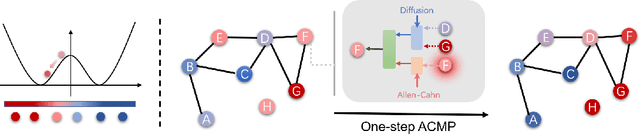

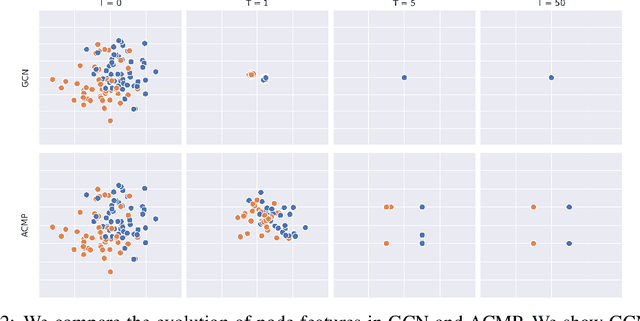
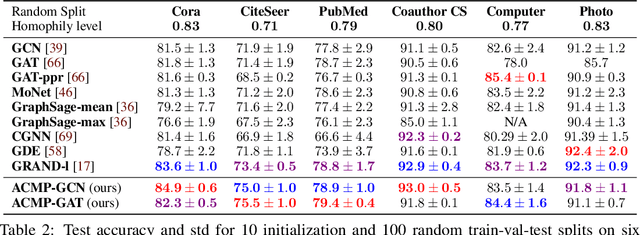
Neural message passing is a basic feature extraction unit for graph-structured data that takes account of the impact of neighboring node features in network propagation from one layer to the next. We model such process by an interacting particle system with attractive and repulsive forces and the Allen-Cahn force arising in the modeling of phase transition. The system is a reaction-diffusion process which can separate particles to different clusters. This induces an Allen-Cahn message passing (ACMP) for graph neural networks where the numerical iteration for the solution constitutes the message passing propagation. The mechanism behind ACMP is phase transition of particles which enables the formation of multi-clusters and thus GNNs prediction for node classification. ACMP can propel the network depth to hundreds of layers with theoretically proven strictly positive lower bound of the Dirichlet energy. It thus provides a deep model of GNNs which circumvents the common GNN problem of oversmoothing. Experiments for various real node classification datasets, with possible high homophily difficulty, show the GNNs with ACMP can achieve state of the art performance with no decay of Dirichlet energy.
Bidirectional Machine Reading Comprehension for Aspect Sentiment Triplet Extraction
Mar 13, 2021
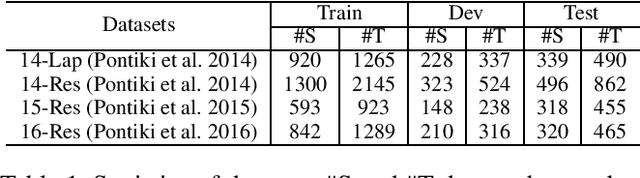
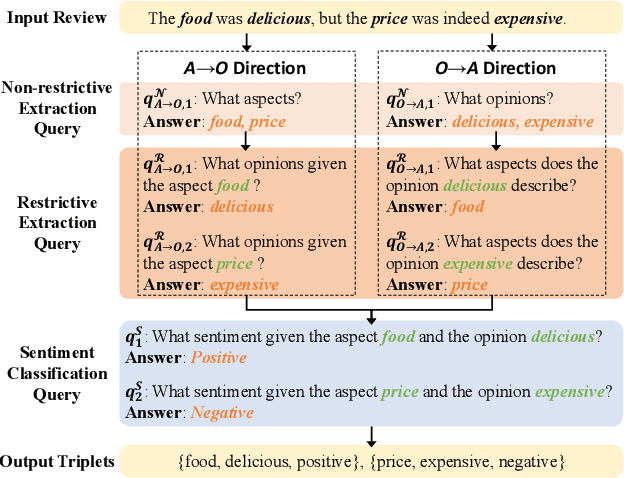
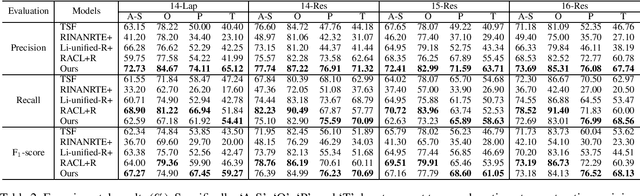
Aspect sentiment triplet extraction (ASTE), which aims to identify aspects from review sentences along with their corresponding opinion expressions and sentiments, is an emerging task in fine-grained opinion mining. Since ASTE consists of multiple subtasks, including opinion entity extraction, relation detection, and sentiment classification, it is critical and challenging to appropriately capture and utilize the associations among them. In this paper, we transform ASTE task into a multi-turn machine reading comprehension (MTMRC) task and propose a bidirectional MRC (BMRC) framework to address this challenge. Specifically, we devise three types of queries, including non-restrictive extraction queries, restrictive extraction queries and sentiment classification queries, to build the associations among different subtasks. Furthermore, considering that an aspect sentiment triplet can derive from either an aspect or an opinion expression, we design a bidirectional MRC structure. One direction sequentially recognizes aspects, opinion expressions, and sentiments to obtain triplets, while the other direction identifies opinion expressions first, then aspects, and at last sentiments. By making the two directions complement each other, our framework can identify triplets more comprehensively. To verify the effectiveness of our approach, we conduct extensive experiments on four benchmark datasets. The experimental results demonstrate that BMRC achieves state-of-the-art performances.
A Comprehensive Survey of Grammar Error Correction
May 02, 2020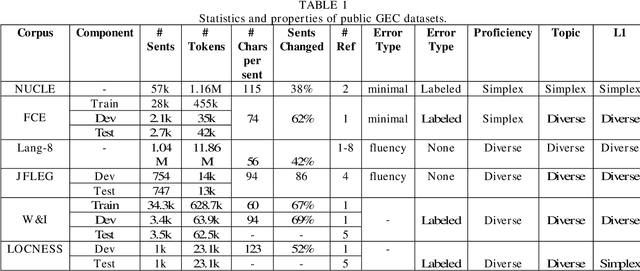
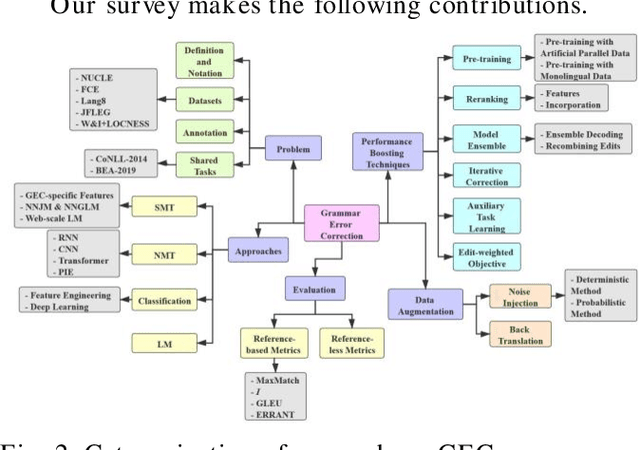
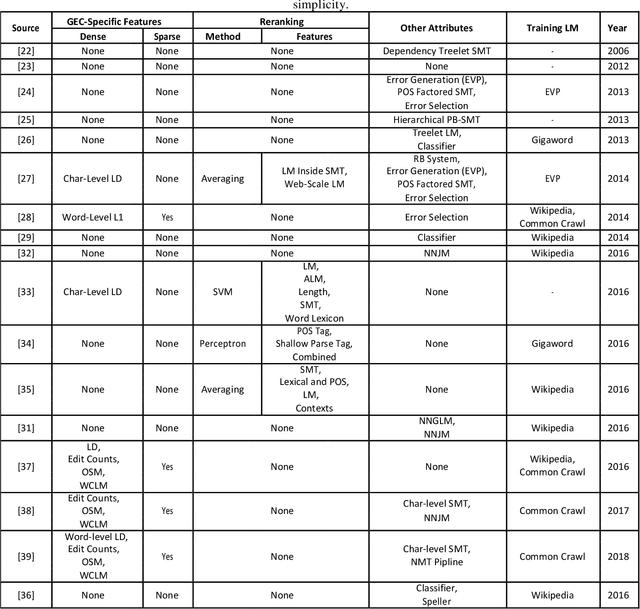

Grammar error correction (GEC) is an important application aspect of natural language processing techniques. The past decade has witnessed significant progress achieved in GEC for the sake of increasing popularity of machine learning and deep learning, especially in late 2010s when near human-level GEC systems are available. However, there is no prior work focusing on the whole recapitulation of the progress. We present the first survey in GEC for a comprehensive retrospect of the literature in this area. We first give the introduction of five public datasets, data annotation schema, two important shared tasks and four standard evaluation metrics. More importantly, we discuss four kinds of basic approaches, including statistical machine translation based approach, neural machine translation based approach, classification based approach and language model based approach, six commonly applied performance boosting techniques for GEC systems and two data augmentation methods. Since GEC is typically viewed as a sister task of machine translation, many GEC systems are based on neural machine translation (NMT) approaches, where the neural sequence-to-sequence model is applied. Similarly, some performance boosting techniques are adapted from machine translation and are successfully combined with GEC systems for enhancement on the final performance. Furthermore, we conduct an analysis in level of basic approaches, performance boosting techniques and integrated GEC systems based on their experiment results respectively for more clear patterns and conclusions. Finally, we discuss five prospective directions for future GEC researches.