 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Reward Supervision: Rubric-Conditioned Self-Distillation
Jun 17, 2026Post-training of reasoning language models is commonly driven by supervised distillation and reinforcement learning with verifiable rewards. Distillation often relies on chain-of-thought annotations that are expensive to obtain and may themselves be noisy, incomplete, or partially incorrect; even when the final solution is correct, an imperfect rationale can interfere with learning. Reinforcement learning with verified rewards, on the other hand, typically compresses evaluative feedback into a scalar signal, obscuring which aspects of a response should be improved. We propose \textbf{Rubric-Conditioned Self-Distillation}, a framework that incorporates rubrics as structured, fine-grained feedback for on-policy self-distillation. Our method conditions the teacher model on criterion-level rubrics and uses it to provide token-level guidance on the student's own sampled trajectories. This design avoids treating a single reference rationale as the sole supervision target. Instead, rubrics specify what a strong response should satisfy, enabling more fine-grained credit assignment over the reasoning process than scalar reward optimization. We instantiate this framework with a two-stage pipeline that first learns to generate task-specific rubrics and then trains a rubric-guided reasoner. We evaluate on a diverse suite of science reasoning benchmarks and results show that rubric-conditioned self-distillation effectively converts rubric-level criteria into token-level guidance over the reasoning process, surpassing GRPO by 1.0 points and OPSD by 0.9 points on average.
Reasoning through Verifiable Forecast Actions: Consistency-Grounded RL for Financial LLMs
May 21, 2026Financial markets are characterized by extreme non-stationarity, low signal-to-noise ratios, and strong dependence on external information such as news, company fundamentals, and macroeconomic signals. Yet, existing approaches either abstract time-series into text or decouple forecasting from language-based reasoning, leading to a fundamental mismatch between qualitative reasoning and quantitative outcomes. To address this, we introduce StockR1, a time-series-enhanced LLM that unifies stock forecasting and financial reasoning through a verifiable forecast action. Based on a tool-call design, the model first emits a forecast action, which is a structured and interpretable representation of its qualitative market outlook. It then invokes a time-series decoder conditioned on this action to generate distributional future trajectories, leading to more informed question answering and financial reasoning. We optimize the full pipeline with reinforcement learning, where rewards jointly reflect answer validity, forecast accuracy, and consistency between generated actions and observed time-series dynamics. In addition, rewards are reweighted by a sample-level uncertainty scalar, encouraging the model to accommodate varying uncertainty in market dynamics. We evaluate StockR1 on financial question answering and stock forecasting over a large-scale 10-year benchmark. Our method consistently outperforms time-series baselines and general-purpose LLMs, improving reasoning accuracy by 17.7% (4B) and 25.9% (8B). These findings demonstrate that structuring the forecast actions establishes a powerful synergy between language reasoning and temporal prediction, enabling LLMs to reason through verifiable, interpretable, and numerically grounded decisions.
Salca: A Sparsity-Aware Hardware Accelerator for Efficient Long-Context Attention Decoding
Apr 27, 2026Long contexts improve capabilities of large language models but pose serious hardware challenges: compute and memory footprints grow linearly with sequence length. Particularly, the decoding phase continuously accesses massive KV cache, dramatically increasing bandwidth and computing pressure. Existing accelerators are primarily designed and evaluated for short contexts. They suffer from significant performance degradation when processing long contexts. To bridge this gap, we identify the major bottleneck and present a hardware accelerator for long context attention decoding via hardware-software co-design. On the software side, we propose dual-compression dynamic sparse attention. It combines ultra-low-precision quantization with feature sparsity to minimize prediction overhead. A hardware-friendly approximate Top-K selection further reduces filter complexity from $O(n \log k)$ to $O(n)$. On the hardware side, we deeply optimize compute and memory access to tackle bottlenecks from intricate interplay between sparse attention and long contexts, and establish a performance model to derive the optimal co-design scheme. The resulting hardware adopts a fully pipelined parallel architecture and achieves $O(n)$ efficiency even for long sequences. Experiments show that our design delivers $3.82\times$ speedup and $74.19\times$ energy efficiency over A100. Compared to SOTA accelerators, this is the first ASIC accelerator that efficiently supports long context inference, with at least $3.5\times$ higher throughput and $2.08\times$ better energy efficiency.
PECKER: A Precisely Efficient Critical Knowledge Erasure Recipe For Machine Unlearning in Diffusion Models
Apr 07, 2026Machine unlearning (MU) has become a critical technique for GenAI models' safe and compliant operation. While existing MU methods are effective, most impose prohibitive training time and computational overhead. Our analysis suggests the root cause lies in poorly directed gradient updates, which reduce training efficiency and destabilize convergence. To mitigate these issues, we propose PECKER, an efficient MU approach that matches or outperforms prevailing methods. Within a distillation framework, PECKER introduces a saliency mask to prioritize updates to parameters that contribute most to forgetting the targeted data, thereby reducing unnecessary gradient computation and shortening overall training time without sacrificing unlearning efficacy. Our method generates samples that unlearn related class or concept more quickly, while closely aligning with the true image distribution on CIFAR-10 and STL-10 datasets, achieving shorter training times for both class forgetting and concept forgetting.
Fin-RATE: A Real-world Financial Analytics and Tracking Evaluation Benchmark for LLMs on SEC Filings
Feb 07, 2026With increasing deployment of Large Language Models (LLMs) in the finance domain, LLMs are increasingly expected to parse complex regulatory disclosures. However, existing benchmarks often focus on isolated details, failing to reflect the complexity of professional analysis that requires synthesizing information across multiple documents, reporting periods, and corporate entities. They do not distinguish whether errors stem from retrieval failures, generation flaws, finance-specific reasoning mistakes, or misunderstanding of the query or context. This makes it difficult to pinpoint performance bottlenecks. To bridge these gaps, we introduce Fin-RATE, a benchmark built on U.S. Securities and Exchange Commission (SEC) filings and mirror financial analyst workflows through three pathways: detail-oriented reasoning within individual disclosures, cross-entity comparison under shared topics, and longitudinal tracking of the same firm across reporting periods. We benchmark 17 leading LLMs, spanning open-source, closed-source, and finance-specialized models, under both ground-truth context and retrieval-augmented settings. Results show substantial performance degradation, with accuracy dropping by 18.60% and 14.35% as tasks shift from single-document reasoning to longitudinal and cross-entity analysis. This is driven by rising comparison hallucinations, time and entity mismatches, and mirrored by declines in reasoning and factuality--limitations that prior benchmarks have yet to formally categorize or quantify.
Multi-Modal Time Series Prediction via Mixture of Modulated Experts
Jan 29, 2026Real-world time series exhibit complex and evolving dynamics, making accurate forecasting extremely challenging. Recent multi-modal forecasting methods leverage textual information such as news reports to improve prediction, but most rely on token-level fusion that mixes temporal patches with language tokens in a shared embedding space. However, such fusion can be ill-suited when high-quality time-text pairs are scarce and when time series exhibit substantial variation in scale and characteristics, thus complicating cross-modal alignment. In parallel, Mixture-of-Experts (MoE) architectures have proven effective for both time series modeling and multi-modal learning, yet many existing MoE-based modality integration methods still depend on token-level fusion. To address this, we propose Expert Modulation, a new paradigm for multi-modal time series prediction that conditions both routing and expert computation on textual signals, enabling direct and efficient cross-modal control over expert behavior. Through comprehensive theoretical analysis and experiments, our proposed method demonstrates substantial improvements in multi-modal time series prediction. The current code is available at https://github.com/BruceZhangReve/MoME
Analyzing Gait Adaptation with Hemiplegia Simulation Suits and Digital Twins
Sep 05, 2025



To advance the development of assistive and rehabilitation robots, it is essential to conduct experiments early in the design cycle. However, testing early prototypes directly with users can pose safety risks. To address this, we explore the use of condition-specific simulation suits worn by healthy participants in controlled environments as a means to study gait changes associated with various impairments and support rapid prototyping. This paper presents a study analyzing the impact of a hemiplegia simulation suit on gait. We collected biomechanical data using a Vicon motion capture system and Delsys Trigno EMG and IMU sensors under four walking conditions: with and without a rollator, and with and without the simulation suit. The gait data was integrated into a digital twin model, enabling machine learning analyses to detect the use of the simulation suit and rollator, identify turning behavior, and evaluate how the suit affects gait over time. Our findings show that the simulation suit significantly alters movement and muscle activation patterns, prompting users to compensate with more abrupt motions. We also identify key features and sensor modalities that are most informative for accurately capturing gait dynamics and modeling human-rollator interaction within the digital twin framework.
TRACE: Grounding Time Series in Context for Multimodal Embedding and Retrieval
Jun 10, 2025The ubiquity of dynamic data in domains such as weather, healthcare, and energy underscores a growing need for effective interpretation and retrieval of time-series data. These data are inherently tied to domain-specific contexts, such as clinical notes or weather narratives, making cross-modal retrieval essential not only for downstream tasks but also for developing robust time-series foundation models by retrieval-augmented generation (RAG). Despite the increasing demand, time-series retrieval remains largely underexplored. Existing methods often lack semantic grounding, struggle to align heterogeneous modalities, and have limited capacity for handling multi-channel signals. To address this gap, we propose TRACE, a generic multimodal retriever that grounds time-series embeddings in aligned textual context. TRACE enables fine-grained channel-level alignment and employs hard negative mining to facilitate semantically meaningful retrieval. It supports flexible cross-modal retrieval modes, including Text-to-Timeseries and Timeseries-to-Text, effectively linking linguistic descriptions with complex temporal patterns. By retrieving semantically relevant pairs, TRACE enriches downstream models with informative context, leading to improved predictive accuracy and interpretability. Beyond a static retrieval engine, TRACE also serves as a powerful standalone encoder, with lightweight task-specific tuning that refines context-aware representations while maintaining strong cross-modal alignment. These representations achieve state-of-the-art performance on downstream forecasting and classification tasks. Extensive experiments across multiple domains highlight its dual utility, as both an effective encoder for downstream applications and a general-purpose retriever to enhance time-series models.
Towards Non-Euclidean Foundation Models: Advancing AI Beyond Euclidean Frameworks
May 20, 2025In the era of foundation models and Large Language Models (LLMs), Euclidean space is the de facto geometric setting of our machine learning architectures. However, recent literature has demonstrated that this choice comes with fundamental limitations. To that end, non-Euclidean learning is quickly gaining traction, particularly in web-related applications where complex relationships and structures are prevalent. Non-Euclidean spaces, such as hyperbolic, spherical, and mixed-curvature spaces, have been shown to provide more efficient and effective representations for data with intrinsic geometric properties, including web-related data like social network topology, query-document relationships, and user-item interactions. Integrating foundation models with non-Euclidean geometries has great potential to enhance their ability to capture and model the underlying structures, leading to better performance in search, recommendations, and content understanding. This workshop focuses on the intersection of Non-Euclidean Foundation Models and Geometric Learning (NEGEL), exploring its potential benefits, including the potential benefits for advancing web-related technologies, challenges, and future directions. Workshop page: [https://hyperboliclearning.github.io/events/www2025workshop](https://hyperboliclearning.github.io/events/www2025workshop)
DYNUS: Uncertainty-aware Trajectory Planner in Dynamic Unknown Environments
Apr 24, 2025

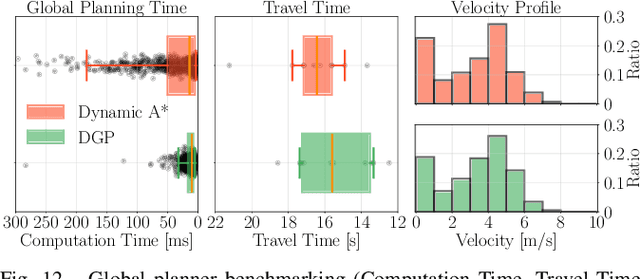

This paper introduces DYNUS, an uncertainty-aware trajectory planner designed for dynamic unknown environments. Operating in such settings presents many challenges -- most notably, because the agent cannot predict the ground-truth future paths of obstacles, a previously planned trajectory can become unsafe at any moment, requiring rapid replanning to avoid collisions. Recently developed planners have used soft-constraint approaches to achieve the necessary fast computation times; however, these methods do not guarantee collision-free paths even with static obstacles. In contrast, hard-constraint methods ensure collision-free safety, but typically have longer computation times. To address these issues, we propose three key contributions. First, the DYNUS Global Planner (DGP) and Temporal Safe Corridor Generation operate in spatio-temporal space and handle both static and dynamic obstacles in the 3D environment. Second, the Safe Planning Framework leverages a combination of exploratory, safe, and contingency trajectories to flexibly re-route when potential future collisions with dynamic obstacles are detected. Finally, the Fast Hard-Constraint Local Trajectory Formulation uses a variable elimination approach to reduce the problem size and enable faster computation by pre-computing dependencies between free and dependent variables while still ensuring collision-free trajectories. We evaluated DYNUS in a variety of simulations, including dense forests, confined office spaces, cave systems, and dynamic environments. Our experiments show that DYNUS achieves a success rate of 100% and travel times that are approximately 25.0% faster than state-of-the-art methods. We also evaluated DYNUS on multiple platforms -- a quadrotor, a wheeled robot, and a quadruped -- in both simulation and hardware experiments.