 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-KV: Breaking Sequence via Injecting Structural Biases into Large Language Models
Jun 09, 2025Modern large language models (LLMs) are inherently auto-regressive, requiring input to be serialized into flat sequences regardless of their structural dependencies. This serialization hinders the model's ability to leverage structural inductive biases, especially in tasks such as retrieval-augmented generation (RAG) and reasoning on data with native graph structures, where inter-segment dependencies are crucial. We introduce Graph-KV with the potential to overcome this limitation. Graph-KV leverages the KV-cache of text segments as condensed representations and governs their interaction through structural inductive biases. In this framework, 'target' segments selectively attend only to the KV-caches of their designated 'source' segments, rather than all preceding segments in a serialized sequence. This approach induces a graph-structured block mask, sparsifying attention and enabling a message-passing-like step within the LLM. Furthermore, strategically allocated positional encodings for source and target segments reduce positional bias and context window consumption. We evaluate Graph-KV across three scenarios: (1) seven RAG benchmarks spanning direct inference, multi-hop reasoning, and long-document understanding; (2) Arxiv-QA, a novel academic paper QA task with full-text scientific papers structured as citation ego-graphs; and (3) paper topic classification within a citation network. By effectively reducing positional bias and harnessing structural inductive biases, Graph-KV substantially outperforms baselines, including standard costly sequential encoding, across various settings. Code and the Graph-KV data are publicly available.
Towards A Universal Graph Structural Encoder
Apr 15, 2025Recent advancements in large-scale pre-training have shown the potential to learn generalizable representations for downstream tasks. In the graph domain, however, capturing and transferring structural information across different graph domains remains challenging, primarily due to the inherent differences in topological patterns across various contexts. Additionally, most existing models struggle to capture the complexity of rich graph structures, leading to inadequate exploration of the embedding space. To address these challenges, we propose GFSE, a universal graph structural encoder designed to capture transferable structural patterns across diverse domains such as molecular graphs, social networks, and citation networks. GFSE is the first cross-domain graph structural encoder pre-trained with multiple self-supervised learning objectives. Built on a Graph Transformer, GFSE incorporates attention mechanisms informed by graph inductive bias, enabling it to encode intricate multi-level and fine-grained topological features. The pre-trained GFSE produces generic and theoretically expressive positional and structural encoding for graphs, which can be seamlessly integrated with various downstream graph feature encoders, including graph neural networks for vectorized features and Large Language Models for text-attributed graphs. Comprehensive experiments on synthetic and real-world datasets demonstrate GFSE's capability to significantly enhance the model's performance while requiring substantially less task-specific fine-tuning. Notably, GFSE achieves state-of-the-art performance in 81.6% evaluated cases, spanning diverse graph models and datasets, highlighting its potential as a powerful and versatile encoder for graph-structured data.
Simple is Effective: The Roles of Graphs and Large Language Models in Knowledge-Graph-Based Retrieval-Augmented Generation
Oct 28, 2024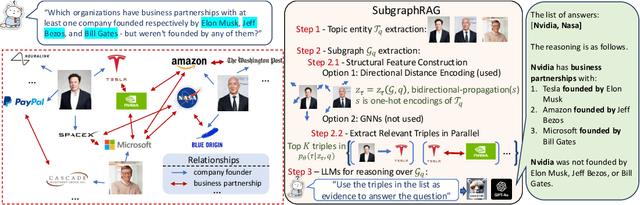


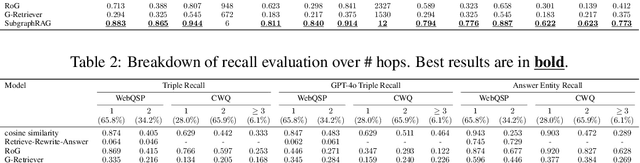
Large Language Models (LLMs) demonstrate strong reasoning abilities but face limitations such as hallucinations and outdated knowledge. Knowledge Graph (KG)-based Retrieval-Augmented Generation (RAG) addresses these issues by grounding LLM outputs in structured external knowledge from KGs. However, current KG-based RAG frameworks still struggle to optimize the trade-off between retrieval effectiveness and efficiency in identifying a suitable amount of relevant graph information for the LLM to digest. We introduce SubgraphRAG, extending the KG-based RAG framework that retrieves subgraphs and leverages LLMs for reasoning and answer prediction. Our approach innovatively integrates a lightweight multilayer perceptron with a parallel triple-scoring mechanism for efficient and flexible subgraph retrieval while encoding directional structural distances to enhance retrieval effectiveness. The size of retrieved subgraphs can be flexibly adjusted to match the query's need and the downstream LLM's capabilities. This design strikes a balance between model complexity and reasoning power, enabling scalable and generalizable retrieval processes. Notably, based on our retrieved subgraphs, smaller LLMs like Llama3.1-8B-Instruct deliver competitive results with explainable reasoning, while larger models like GPT-4o achieve state-of-the-art accuracy compared with previous baselines -- all without fine-tuning. Extensive evaluations on the WebQSP and CWQ benchmarks highlight SubgraphRAG's strengths in efficiency, accuracy, and reliability by reducing hallucinations and improving response grounding.
Towards Understanding Sensitive and Decisive Patterns in Explainable AI: A Case Study of Model Interpretation in Geometric Deep Learning
Jun 30, 2024The interpretability of machine learning models has gained increasing attention, particularly in scientific domains where high precision and accountability are crucial. This research focuses on distinguishing between two critical data patterns -- sensitive patterns (model-related) and decisive patterns (task-related) -- which are commonly used as model interpretations but often lead to confusion. Specifically, this study compares the effectiveness of two main streams of interpretation methods: post-hoc methods and self-interpretable methods, in detecting these patterns. Recently, geometric deep learning (GDL) has shown superior predictive performance in various scientific applications, creating an urgent need for principled interpretation methods. Therefore, we conduct our study using several representative GDL applications as case studies. We evaluate thirteen interpretation methods applied to three major GDL backbone models, using four scientific datasets to assess how well these methods identify sensitive and decisive patterns. Our findings indicate that post-hoc methods tend to provide interpretations better aligned with sensitive patterns, whereas certain self-interpretable methods exhibit strong and stable performance in detecting decisive patterns. Additionally, our study offers valuable insights into improving the reliability of these interpretation methods. For example, ensembling post-hoc interpretations from multiple models trained on the same task can effectively uncover the task's decisive patterns.
What Can We Learn from State Space Models for Machine Learning on Graphs?
Jun 09, 2024Machine learning on graphs has recently found extensive applications across domains. However, the commonly used Message Passing Neural Networks (MPNNs) suffer from limited expressive power and struggle to capture long-range dependencies. Graph transformers offer a strong alternative due to their global attention mechanism, but they come with great computational overheads, especially for large graphs. In recent years, State Space Models (SSMs) have emerged as a compelling approach to replace full attention in transformers to model sequential data. It blends the strengths of RNNs and CNNs, offering a) efficient computation, b) the ability to capture long-range dependencies, and c) good generalization across sequences of various lengths. However, extending SSMs to graph-structured data presents unique challenges due to the lack of canonical node ordering in graphs. In this work, we propose Graph State Space Convolution (GSSC) as a principled extension of SSMs to graph-structured data. By leveraging global permutation-equivariant set aggregation and factorizable graph kernels that rely on relative node distances as the convolution kernels, GSSC preserves all three advantages of SSMs. We demonstrate the provably stronger expressiveness of GSSC than MPNNs in counting graph substructures and show its effectiveness across 10 real-world, widely used benchmark datasets, where GSSC achieves best results on 7 out of 10 datasets with all significant improvements compared to the state-of-the-art baselines and second-best results on the other 3 datasets. Our findings highlight the potential of GSSC as a powerful and scalable model for graph machine learning. Our code is available at https://github.com/Graph-COM/GSSC.
Locality-Sensitive Hashing-Based Efficient Point Transformer with Applications in High-Energy Physics
Feb 19, 2024



This study introduces a novel transformer model optimized for large-scale point cloud processing in scientific domains such as high-energy physics (HEP) and astrophysics. Addressing the limitations of graph neural networks and standard transformers, our model integrates local inductive bias and achieves near-linear complexity with hardware-friendly regular operations. One contribution of this work is the quantitative analysis of the error-complexity tradeoff of various sparsification techniques for building efficient transformers. Our findings highlight the superiority of using locality-sensitive hashing (LSH), especially OR \& AND-construction LSH, in kernel approximation for large-scale point cloud data with local inductive bias. Based on this finding, we propose LSH-based Efficient Point Transformer (\textbf{HEPT}), which combines E$^2$LSH with OR \& AND constructions and is built upon regular computations. HEPT demonstrates remarkable performance in two critical yet time-consuming HEP tasks, significantly outperforming existing GNNs and transformers in accuracy and computational speed, marking a significant advancement in geometric deep learning and large-scale scientific data processing. Our code is available at \url{https://github.com/Graph-COM/HEPT}.
High Pileup Particle Tracking with Object Condensation
Dec 06, 2023
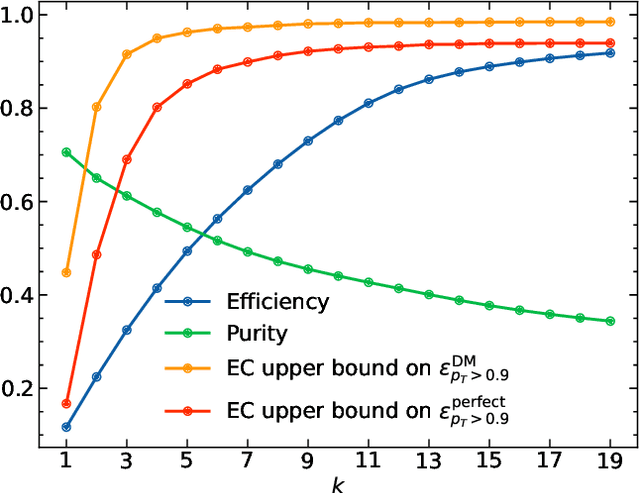
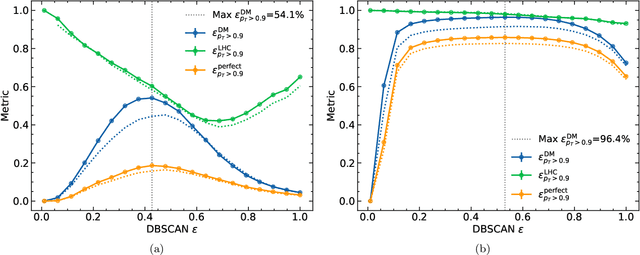
Recent work has demonstrated that graph neural networks (GNNs) can match the performance of traditional algorithms for charged particle tracking while improving scalability to meet the computing challenges posed by the HL-LHC. Most GNN tracking algorithms are based on edge classification and identify tracks as connected components from an initial graph containing spurious connections. In this talk, we consider an alternative based on object condensation (OC), a multi-objective learning framework designed to cluster points (hits) belonging to an arbitrary number of objects (tracks) and regress the properties of each object. Building on our previous results, we present a streamlined model and show progress toward a one-shot OC tracking algorithm in a high-pileup environment.
GDL-DS: A Benchmark for Geometric Deep Learning under Distribution Shifts
Oct 12, 2023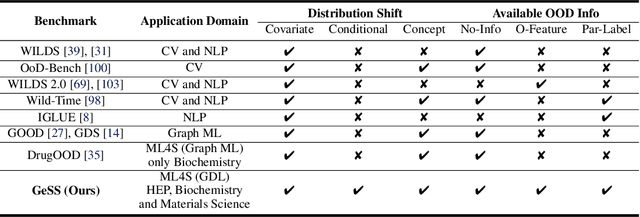
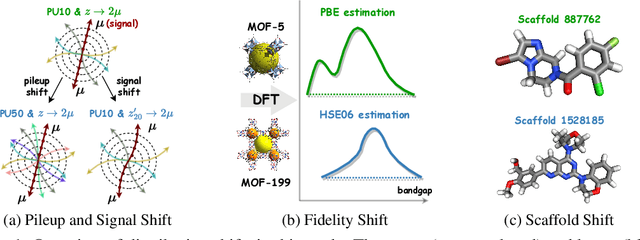
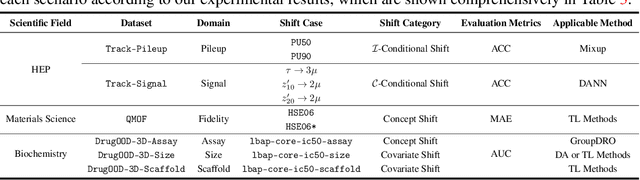
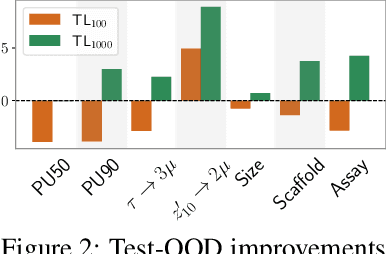
Geometric deep learning (GDL) has gained significant attention in various scientific fields, chiefly for its proficiency in modeling data with intricate geometric structures. Yet, very few works have delved into its capability of tackling the distribution shift problem, a prevalent challenge in many relevant applications. To bridge this gap, we propose GDL-DS, a comprehensive benchmark designed for evaluating the performance of GDL models in scenarios with distribution shifts. Our evaluation datasets cover diverse scientific domains from particle physics and materials science to biochemistry, and encapsulate a broad spectrum of distribution shifts including conditional, covariate, and concept shifts. Furthermore, we study three levels of information access from the out-of-distribution (OOD) testing data, including no OOD information, only OOD features without labels, and OOD features with a few labels. Overall, our benchmark results in 30 different experiment settings, and evaluates 3 GDL backbones and 11 learning algorithms in each setting. A thorough analysis of the evaluation results is provided, poised to illuminate insights for DGL researchers and domain practitioners who are to use DGL in their applications.
Interpretable Geometric Deep Learning via Learnable Randomness Injection
Oct 30, 2022Point cloud data is ubiquitous in scientific fields. Recently, geometric deep learning (GDL) has been widely applied to solve prediction tasks with such data. However, GDL models are often complicated and hardly interpretable, which poses concerns to scientists when deploying these models in scientific analysis and experiments. This work proposes a general mechanism named learnable randomness injection (LRI), which allows building inherently interpretable models based on general GDL backbones. LRI-induced models, once being trained, can detect the points in the point cloud data that carry information indicative of the prediction label. We also propose four datasets from real scientific applications that cover the domains of high-energy physics and biochemistry to evaluate the LRI mechanism. Compared with previous post-hoc interpretation methods, the points detected by LRI align much better and stabler with the ground-truth patterns that have actual scientific meanings. LRI is grounded by the information bottleneck principle. LRI-induced models also show more robustness to the distribution shifts between training and test scenarios. Our code and datasets are available at \url{https://github.com/Graph-COM/LRI}.
Interpretable and Generalizable Graph Learning via Stochastic Attention Mechanism
Jan 31, 2022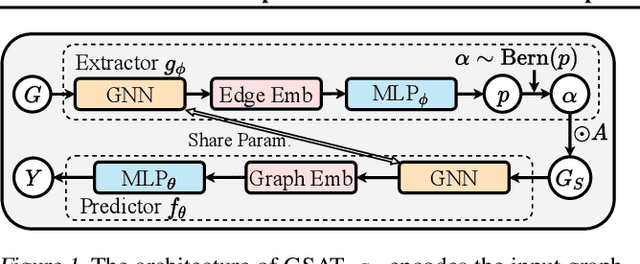
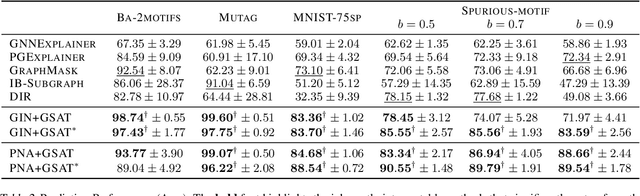

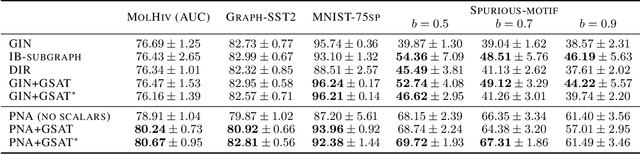
Interpretable graph learning is in need as many scientific applications depend on learning models to collect insights from graph-structured data. Previous works mostly focused on using post-hoc approaches to interpret a pre-trained model (graph neural network models in particular). They argue against inherently interpretable models because good interpretation of these models is often at the cost of their prediction accuracy. And, the widely used attention mechanism for inherent interpretation often fails to provide faithful interpretation in graph learning tasks. In this work, we address both issues by proposing Graph Stochastic Attention (GSAT), an attention mechanism derived from the information bottleneck principle. GSAT leverages stochastic attention to block the information from the task-irrelevant graph components while learning stochasticity-reduced attention to select the task-relevant subgraphs for interpretation. GSAT can also apply to fine-tuning and interpreting pre-trained models via stochastic attention mechanism. Extensive experiments on eight datasets show that GSAT outperforms the state-of-the-art methods by up to 20%$\uparrow$ in interpretation AUC and 5%$\uparrow$ in prediction accuracy.