 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISAC with Affine Frequency Division Multiplexing: An FMCW-Based Signal Processing Perspective
Nov 15, 2025This paper investigates the sensing potential of affine frequency division multiplexing (AFDM) in high-mobility integrated sensing and communication (ISAC) from the perspective of radar waveforms. We introduce an innovative parameter selection criterion that establishes a precise mathematical equivalence between AFDM subcarriers and Nyquist-sampled frequency-modulated continuous-wave (FMCW). This connection not only provides a clear physical insight into AFDM's sensing mechanism but also enables a direct mapping from the DAFT index to delay-Doppler (DD) parameters of wireless channels. Building on this, we develop a novel input-output model in a DD-parameterized DAFT (DD-DAFT) domain for AFDM, which explicitly reveals the inherent DD coupling effect arising from the chirp-channel interaction. Subsequently, we design two matched-filtering sensing algorithms. The first is performed in the time-frequency domain with low complexity, while the second is operated in the DD-DAFT domain to precisely resolve the DD coupling. Simulations show that our algorithms achieve effective pilot-free sensing and demonstrate a fundamental trade-off between sensing performance, communication overhead, and computational complexity. The proposed AFDM outperforms classical AFDM and other variants in most scenarios.
PanoSplatt3R: Leveraging Perspective Pretraining for Generalized Unposed Wide-Baseline Panorama Reconstruction
Jul 29, 2025Wide-baseline panorama reconstruction has emerged as a highly effective and pivotal approach for not only achieving geometric reconstruction of the surrounding 3D environment, but also generating highly realistic and immersive novel views. Although existing methods have shown remarkable performance across various benchmarks, they are predominantly reliant on accurate pose information. In real-world scenarios, the acquisition of precise pose often requires additional computational resources and is highly susceptible to noise. These limitations hinder the broad applicability and practicality of such methods. In this paper, we present PanoSplatt3R, an unposed wide-baseline panorama reconstruction method. We extend and adapt the foundational reconstruction pretrainings from the perspective domain to the panoramic domain, thus enabling powerful generalization capabilities. To ensure a seamless and efficient domain-transfer process, we introduce RoPE rolling that spans rolled coordinates in rotary positional embeddings across different attention heads, maintaining a minimal modification to RoPE's mechanism, while modeling the horizontal periodicity of panorama images. Comprehensive experiments demonstrate that PanoSplatt3R, even in the absence of pose information, significantly outperforms current state-of-the-art methods. This superiority is evident in both the generation of high-quality novel views and the accuracy of depth estimation, thereby showcasing its great potential for practical applications. Project page: https://npucvr.github.io/PanoSplatt3R
Self-Reflective Planning with Knowledge Graphs: Enhancing LLM Reasoning Reliability for Question Answering
May 26, 2025Recently, large language models (LLMs) have demonstrated remarkable capabilities in natural language processing tasks, yet they remain prone to hallucinations when reasoning with insufficient internal knowledge. While integrating LLMs with knowledge graphs (KGs) provides access to structured, verifiable information, existing approaches often generate incomplete or factually inconsistent reasoning paths. To this end, we propose Self-Reflective Planning (SRP), a framework that synergizes LLMs with KGs through iterative, reference-guided reasoning. Specifically, given a question and topic entities, SRP first searches for references to guide planning and reflection. In the planning process, it checks initial relations and generates a reasoning path. After retrieving knowledge from KGs through a reasoning path, it implements iterative reflection by judging the retrieval result and editing the reasoning path until the answer is correctly retrieved. Extensive experiments on three public datasets demonstrate that SRP surpasses various strong baselines and further underscore its reliable reasoning ability.
Targetless Intrinsics and Extrinsic Calibration of Multiple LiDARs and Cameras with IMU using Continuous-Time Estimation
Jan 06, 2025



Accurate spatiotemporal calibration is a prerequisite for multisensor fusion. However, sensors are typically asynchronous, and there is no overlap between the fields of view of cameras and LiDARs, posing challenges for intrinsic and extrinsic parameter calibration. To address this, we propose a calibration pipeline based on continuous-time and bundle adjustment (BA) capable of simultaneous intrinsic and extrinsic calibration (6 DOF transformation and time offset). We do not require overlapping fields of view or any calibration board. Firstly, we establish data associations between cameras using Structure from Motion (SFM) and perform self-calibration of camera intrinsics. Then, we establish data associations between LiDARs through adaptive voxel map construction, optimizing for extrinsic calibration within the map. Finally, by matching features between the intensity projection of LiDAR maps and camera images, we conduct joint optimization for intrinsic and extrinsic parameters. This pipeline functions in texture-rich structured environments, allowing simultaneous calibration of any number of cameras and LiDARs without the need for intricate sensor synchronization triggers. Experimental results demonstrate our method's ability to fulfill co-visibility and motion constraints between sensors without accumulating errors.
Rethinking Addressing in Language Models via Contexualized Equivariant Positional Encoding
Jan 01, 2025



Transformers rely on both content-based and position-based addressing mechanisms to make predictions, but existing positional encoding techniques often diminish the effectiveness of position-based addressing. Many current methods enforce rigid patterns in attention maps, limiting the ability to model long-range dependencies and adapt to diverse tasks. Additionally, most positional encodings are learned as general biases, lacking the specialization required for different instances within a dataset. To address this, we propose con$\textbf{T}$extualized equivari$\textbf{A}$nt $\textbf{P}$osition $\textbf{E}$mbedding ($\textbf{TAPE}$), a novel framework that enhances positional embeddings by incorporating sequence content across layers. TAPE introduces dynamic, context-aware positional encodings, overcoming the constraints of traditional fixed patterns. By enforcing permutation and orthogonal equivariance, TAPE ensures the stability of positional encodings during updates, improving robustness and adaptability. Our method can be easily integrated into pre-trained transformers, offering parameter-efficient fine-tuning with minimal overhead. Extensive experiments shows that TAPE achieves superior performance in language modeling, arithmetic reasoning, and long-context retrieval tasks compared to existing positional embedding techniques.
Understanding and Mitigating Bottlenecks of State Space Models through the Lens of Recency and Over-smoothing
Dec 31, 2024



Structured State Space Models (SSMs) have emerged as alternatives to transformers. While SSMs are often regarded as effective in capturing long-sequence dependencies, we rigorously demonstrate that they are inherently limited by strong recency bias. Our empirical studies also reveal that this bias impairs the models' ability to recall distant information and introduces robustness issues. Our scaling experiments then discovered that deeper structures in SSMs can facilitate the learning of long contexts. However, subsequent theoretical analysis reveals that as SSMs increase in depth, they exhibit another inevitable tendency toward over-smoothing, e.g., token representations becoming increasingly indistinguishable. This fundamental dilemma between recency and over-smoothing hinders the scalability of existing SSMs. Inspired by our theoretical findings, we propose to polarize two channels of the state transition matrices in SSMs, setting them to zero and one, respectively, simultaneously addressing recency bias and over-smoothing. Experiments demonstrate that our polarization technique consistently enhances the associative recall accuracy of long-range tokens and unlocks SSMs to benefit further from deeper architectures. All source codes are released at https://github.com/VITA-Group/SSM-Bottleneck.
Detect, Investigate, Judge and Determine: A Novel LLM-based Framework for Few-shot Fake News Detection
Jul 12, 2024Few-Shot Fake News Detection (FS-FND) aims to distinguish inaccurate news from real ones in extremely low-resource scenarios. This task has garnered increased attention due to the widespread dissemination and harmful impact of fake news on social media. Large Language Models (LLMs) have demonstrated competitive performance with the help of their rich prior knowledge and excellent in-context learning abilities. However, existing methods face significant limitations, such as the Understanding Ambiguity and Information Scarcity, which significantly undermine the potential of LLMs. To address these shortcomings, we propose a Dual-perspective Augmented Fake News Detection (DAFND) model, designed to enhance LLMs from both inside and outside perspectives. Specifically, DAFND first identifies the keywords of each news article through a Detection Module. Subsequently, DAFND creatively designs an Investigation Module to retrieve inside and outside valuable information concerning to the current news, followed by another Judge Module to derive its respective two prediction results. Finally, a Determination Module further integrates these two predictions and derives the final result. Extensive experiments on two publicly available datasets show the efficacy of our proposed method, particularly in low-resource settings.
Towards Understanding Sensitive and Decisive Patterns in Explainable AI: A Case Study of Model Interpretation in Geometric Deep Learning
Jun 30, 2024The interpretability of machine learning models has gained increasing attention, particularly in scientific domains where high precision and accountability are crucial. This research focuses on distinguishing between two critical data patterns -- sensitive patterns (model-related) and decisive patterns (task-related) -- which are commonly used as model interpretations but often lead to confusion. Specifically, this study compares the effectiveness of two main streams of interpretation methods: post-hoc methods and self-interpretable methods, in detecting these patterns. Recently, geometric deep learning (GDL) has shown superior predictive performance in various scientific applications, creating an urgent need for principled interpretation methods. Therefore, we conduct our study using several representative GDL applications as case studies. We evaluate thirteen interpretation methods applied to three major GDL backbone models, using four scientific datasets to assess how well these methods identify sensitive and decisive patterns. Our findings indicate that post-hoc methods tend to provide interpretations better aligned with sensitive patterns, whereas certain self-interpretable methods exhibit strong and stable performance in detecting decisive patterns. Additionally, our study offers valuable insights into improving the reliability of these interpretation methods. For example, ensembling post-hoc interpretations from multiple models trained on the same task can effectively uncover the task's decisive patterns.
Retrosynthesis Prediction via Search in (Hyper) Graph
Feb 09, 2024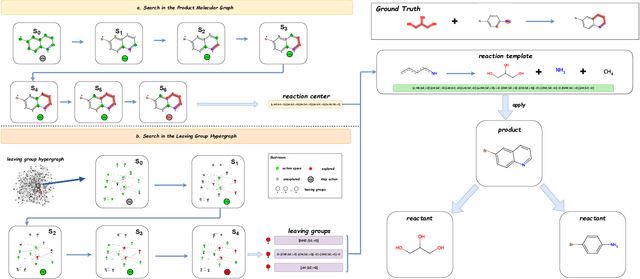
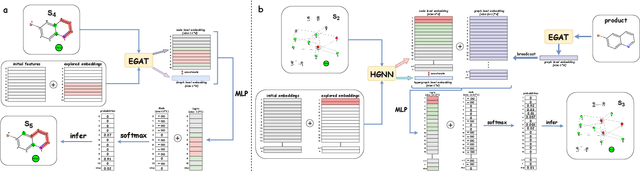
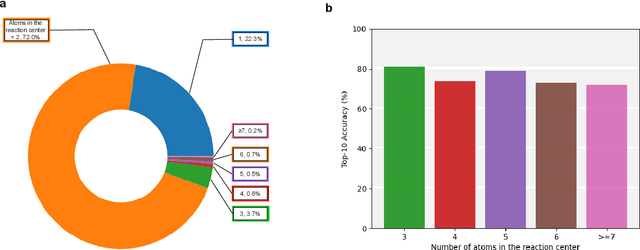
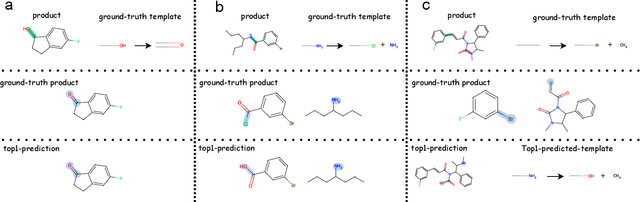
Predicting reactants from a specified core product stands as a fundamental challenge within organic synthesis, termed retrosynthesis prediction. Recently, semi-template-based methods and graph-edits-based methods have achieved good performance in terms of both interpretability and accuracy. However, due to their mechanisms these methods cannot predict complex reactions, e.g., reactions with multiple reaction center or attaching the same leaving group to more than one atom. In this study we propose a semi-template-based method, the \textbf{Retro}synthesis via \textbf{S}earch \textbf{i}n (Hyper) \textbf{G}raph (RetroSiG) framework to alleviate these limitations. In the proposed method, we turn the reaction center identification and the leaving group completion tasks as tasks of searching in the product molecular graph and leaving group hypergraph respectively. As a semi-template-based method RetroSiG has several advantages. First, RetroSiG is able to handle the complex reactions mentioned above by its novel search mechanism. Second, RetroSiG naturally exploits the hypergraph to model the implicit dependencies between leaving groups. Third, RetroSiG makes full use of the prior, i.e., one-hop constraint. It reduces the search space and enhances overall performance. Comprehensive experiments demonstrated that RetroSiG achieved competitive results. Furthermore, we conducted experiments to show the capability of RetroSiG in predicting complex reactions. Ablation experiments verified the efficacy of specific elements, such as the one-hop constraint and the leaving group hypergraph.
A Low-Complexity Range Estimation with Adjusted Affine Frequency Division Multiplexing Waveform
Dec 29, 2023Affine frequency division multiplexing (AFDM) is a recently proposed communication waveform for time-varying channel scenarios. As a chirp-based multicarrier modulation technique it can not only satisfy the needs of multiple scenarios in future mobile communication networks but also achieve good performance in radar sensing by adjusting the built-in parameters, making it a promising air interface waveform in integrated sensing and communication (ISAC) applications. In this paper, we investigate an AFDM-based radar system and analyze the radar ambiguity function of AFDM with different built-in parameters, based on which we find an AFDM waveform with the specific parameter c2 owns the near-optimal time-domain ambiguity function. Then a low-complexity algorithm based on matched filtering for high-resolution target range estimation is proposed for this specific AFDM waveform. Through simulation and analysis, the specific AFDM waveform has near-optimal range estimation performance with the proposed low-complexity algorithm while having the same bit error rate (BER) performance as orthogonal time frequency space (OTFS) using simple linear minimum mean square error (LMMSE) equalizer.