 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlag-Preamble-Based Delay-Doppler Channel Estimation for Next-Evolution Waveforms
Mar 16, 2026Accurate delay-Doppler channel estimation is critical for next-evolution waveforms (NEWs) to enable reliable signal detection. This paper proposes a robust channel estimation algorithm that integrates Flag sequences optimized via an adaptive accelerated parallel majorization-minimization (AP-MM) algorithm with a proposed channel estimation algorithm. To enable efficient, low-complexity parameter extraction and further overcome the robustness issues of conventional greedy estimation, we introduce two key enhancements, i.e., a candidate selection strategy to mitigate spurious sidelobe peaks, and a global least squares (LS) refinement stage to eliminate error propagation caused by sidelobe masking effects. Numerical results demonstrate that the proposed scheme significantly outperforms traditional existing algorithms, achieving the desired estimation accuracy.
Integrated Channel Sounding and Communication: Requirements, Architecture, Challenges, and Key Technologies
Mar 16, 2026Channel models are essential for the design, evaluation, and optimization of wireless communication systems. The emerging space-air-ground-sea integrated network (SAGSIN), characterized by diverse service applications and extended-spectrum operations, places even greater demands on highly accurate channel models. However, conventional channel sounding is limited by generalized measurement campaigns, inadequate cross-band consistency, and insufficient real-time adaptability, making it unable to meet the needs of SAGSIN for scenario-specific and high-precision channel modeling. To address this challenge, we propose a novel technological framework, termed integrated channel sounding and communication (ICSC). By deeply integrating sounding and communication, the ICSC enables efficient and real-time acquisition of dynamic channel characteristics during communication processes, supporting fine-grained site- and scenario-specific measurements. Furthermore, leveraging artificial intelligence techniques, ICSC can identify channel conditions and adapt waveform parameters in real-time according to scenario variations, which in turn enhances communication performance. This article first introduces the fundamental principles of the ICSC framework, elaborates on its core concepts and key advantages, and demonstrates its feasibility through the development of an integrated verification system (IVS). Subsequently, the potential applications and opportunities of the ICSC are analyzed in depth, followed by a discussion of its future development directions and remaining challenges.
Landscape-aware Automated Algorithm Design: An Efficient Framework for Real-world Optimization
Feb 04, 2026The advent of Large Language Models (LLMs) has opened new frontiers in automated algorithm design, giving rise to numerous powerful methods. However, these approaches retain critical limitations: they require extensive evaluation of the target problem to guide the search process, making them impractical for real-world optimization tasks, where each evaluation consumes substantial computational resources. This research proposes an innovative and efficient framework that decouples algorithm discovery from high-cost evaluation. Our core innovation lies in combining a Genetic Programming (GP) function generator with an LLM-driven evolutionary algorithm designer. The evolutionary direction of the GP-based function generator is guided by the similarity between the landscape characteristics of generated proxy functions and those of real-world problems, ensuring that algorithms discovered via proxy functions exhibit comparable performance on real-world problems. Our method enables deep exploration of the algorithmic space before final validation while avoiding costly real-world evaluations. We validated the framework's efficacy across multiple real-world problems, demonstrating its ability to discover high-performance algorithms while substantially reducing expensive evaluations. This approach shows a path to apply LLM-based automated algorithm design to computationally intensive real-world optimization challenges.
Scalable Data-Driven Reachability Analysis and Control via Koopman Operators with Conformal Coverage Guarantees
Jan 03, 2026We propose a scalable reachability-based framework for probabilistic, data-driven safety verification of unknown nonlinear dynamics. We use Koopman theory with a neural network (NN) lifting function to learn an approximate linear representation of the dynamics and design linear controllers in this space to enable closed-loop tracking of a reference trajectory distribution. Closed-loop reachable sets are efficiently computed in the lifted space and mapped back to the original state space via NN verification tools. To capture model mismatch between the Koopman dynamics and the true system, we apply conformal prediction to produce statistically-valid error bounds that inflate the reachable sets to ensure the true trajectories are contained with a user-specified probability. These bounds generalize across references, enabling reuse without recomputation. Results on high-dimensional MuJoCo tasks (11D Hopper, 28D Swimmer) and 12D quadcopters show improved reachable set coverage rate, computational efficiency, and conservativeness over existing methods.
InfiniteVL: Synergizing Linear and Sparse Attention for Highly-Efficient, Unlimited-Input Vision-Language Models
Dec 09, 2025Window attention and linear attention represent two principal strategies for mitigating the quadratic complexity and ever-growing KV cache in Vision-Language Models (VLMs). However, we observe that window-based VLMs suffer performance degradation when sequence length exceeds the window size, while linear attention underperforms on information-intensive tasks such as OCR and document understanding. To overcome these limitations, we propose InfiniteVL, a linear-complexity VLM architecture that synergizes sliding window attention (SWA) with Gated DeltaNet. For achieving competitive multimodal performance under constrained resources, we design a three-stage training strategy comprising distillation pretraining, instruction tuning, and long-sequence SFT. Remarkably, using less than 2\% of the training data required by leading VLMs, InfiniteVL not only substantially outperforms previous linear-complexity VLMs but also matches the performance of leading Transformer-based VLMs, while demonstrating effective long-term memory retention. Compared to similar-sized Transformer-based VLMs accelerated by FlashAttention-2, InfiniteVL achieves over 3.6\times inference speedup while maintaining constant latency and memory footprint. In streaming video understanding scenarios, it sustains a stable 24 FPS real-time prefill speed while preserving long-term memory cache. Code and models are available at https://github.com/hustvl/InfiniteVL.
ISAC with Affine Frequency Division Multiplexing: An FMCW-Based Signal Processing Perspective
Nov 15, 2025This paper investigates the sensing potential of affine frequency division multiplexing (AFDM) in high-mobility integrated sensing and communication (ISAC) from the perspective of radar waveforms. We introduce an innovative parameter selection criterion that establishes a precise mathematical equivalence between AFDM subcarriers and Nyquist-sampled frequency-modulated continuous-wave (FMCW). This connection not only provides a clear physical insight into AFDM's sensing mechanism but also enables a direct mapping from the DAFT index to delay-Doppler (DD) parameters of wireless channels. Building on this, we develop a novel input-output model in a DD-parameterized DAFT (DD-DAFT) domain for AFDM, which explicitly reveals the inherent DD coupling effect arising from the chirp-channel interaction. Subsequently, we design two matched-filtering sensing algorithms. The first is performed in the time-frequency domain with low complexity, while the second is operated in the DD-DAFT domain to precisely resolve the DD coupling. Simulations show that our algorithms achieve effective pilot-free sensing and demonstrate a fundamental trade-off between sensing performance, communication overhead, and computational complexity. The proposed AFDM outperforms classical AFDM and other variants in most scenarios.
Beyond Plain Demos: A Demo-centric Anchoring Paradigm for In-Context Learning in Alzheimer's Disease Detection
Nov 10, 2025Detecting Alzheimer's disease (AD) from narrative transcripts challenges large language models (LLMs): pre-training rarely covers this out-of-distribution task, and all transcript demos describe the same scene, producing highly homogeneous contexts. These factors cripple both the model's built-in task knowledge (\textbf{task cognition}) and its ability to surface subtle, class-discriminative cues (\textbf{contextual perception}). Because cognition is fixed after pre-training, improving in-context learning (ICL) for AD detection hinges on enriching perception through better demonstration (demo) sets. We demonstrate that standard ICL quickly saturates, its demos lack diversity (context width) and fail to convey fine-grained signals (context depth), and that recent task vector (TV) approaches improve broad task adaptation by injecting TV into the LLMs' hidden states (HSs), they are ill-suited for AD detection due to the mismatch of injection granularity, strength and position. To address these bottlenecks, we introduce \textbf{DA4ICL}, a demo-centric anchoring framework that jointly expands context width via \emph{\textbf{Diverse and Contrastive Retrieval}} (DCR) and deepens each demo's signal via \emph{\textbf{Projected Vector Anchoring}} (PVA) at every Transformer layer. Across three AD benchmarks, DA4ICL achieves large, stable gains over both ICL and TV baselines, charting a new paradigm for fine-grained, OOD and low-resource LLM adaptation.
Ambiguity Function Analysis of AFDM Under Pulse-Shaped Random ISAC Signaling
Nov 06, 2025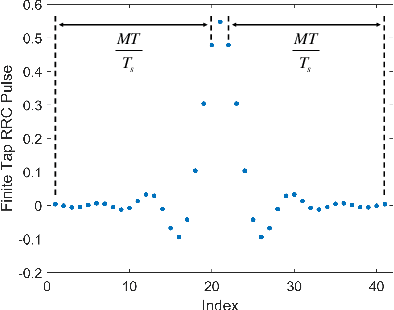
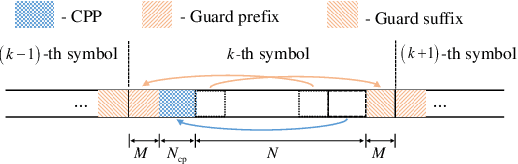
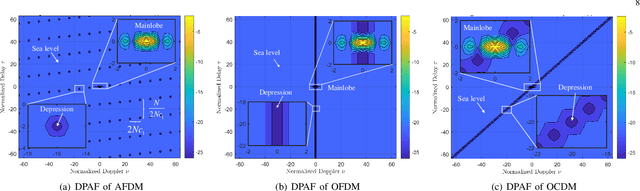
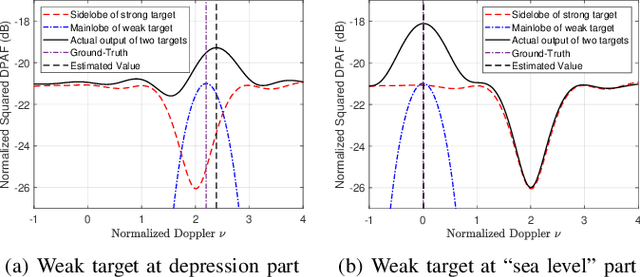
This paper investigates the ambiguity function (AF) of the emerging affine frequency division multiplexing (AFDM) waveform for Integrated Sensing and Communication (ISAC) signaling under a pulse shaping regime. Specifically, we first derive the closed-form expression of the average squared discrete period AF (DPAF) for AFDM waveform without pulse shaping, revealing that the AF depends on the parameter $c_1$ and the kurtosis of random communication data, while being independent of the parameter $c_2$. As a step further, we conduct a comprehensive analysis on the AFs of various waveforms, including AFDM, orthogonal frequency division multiplexing (OFDM) and orthogonal chirp-division multiplexing (OCDM). Our results indicate that all three waveforms exhibit the same number of regular depressions in the sidelobes of their AFs, which incurs performance loss for detecting and estimating weak targets. However, the AFDM waveform can flexibly control the positions of depressions by adjusting the parameter $c_1$, which motivates a novel design approach of the AFDM parameters to mitigate the adverse impact of depressions of the strong target on the weak target. Furthermore, a closed-form expression of the average squared DPAF for pulse-shaped random AFDM waveform is derived, which demonstrates that the pulse shaping filter generates the shaped mainlobe along the delay axis and the rapid roll-off sidelobes along the Doppler axis. Numerical results verify the effectiveness of our theoretical analysis and proposed design methodology for the AFDM modulation.
From OFDM to AFDM: Enabling Adaptive Integrated Sensing and Communication in High-Mobility Scenarios
Oct 31, 2025Integrated sensing and communication (ISAC) is a key feature of next-generation wireless networks, enabling a wide range of emerging applications such as vehicle-to-everything (V2X) and unmanned aerial vehicles (UAVs), which operate in high-mobility scenarios. Notably, the wireless channels within these applications typically exhibit severe delay and Doppler spreads. The latter causes serious communication performance degradation in the Orthogonal Frequency-Division Multiplexing (OFDM) waveform that is widely adopted in current wireless networks. To address this challenge, the recently proposed Doppler-resilient affine frequency division multiplexing (AFDM) waveform, which uses flexible chirp signals as subcarriers, shows great potential for achieving adaptive ISAC in high-mobility scenarios. This article provides a comprehensive overview of AFDM-ISAC. We begin by presenting the fundamentals of AFDM-ISAC, highlighting its inherent frequency-modulated continuous-wave (FMCW)-like characteristics. Then, we explore its ISAC performance limits by analyzing its diversity order, ambiguity function (AF), and Cramer-Rao Bound (CRB). Finally, we present several effective sensing algorithms and opportunities for AFDM-ISAC, with the aim of sparking new ideas in this emerging field.
BLADE: Benchmark suite for LLM-driven Automated Design and Evolution of iterative optimisation heuristics
Apr 28, 2025The application of Large Language Models (LLMs) for Automated Algorithm Discovery (AAD), particularly for optimisation heuristics, is an emerging field of research. This emergence necessitates robust, standardised benchmarking practices to rigorously evaluate the capabilities and limitations of LLM-driven AAD methods and the resulting generated algorithms, especially given the opacity of their design process and known issues with existing benchmarks. To address this need, we introduce BLADE (Benchmark suite for LLM-driven Automated Design and Evolution), a modular and extensible framework specifically designed for benchmarking LLM-driven AAD methods in a continuous black-box optimisation context. BLADE integrates collections of benchmark problems (including MA-BBOB and SBOX-COST among others) with instance generators and textual descriptions aimed at capability-focused testing, such as generalisation, specialisation and information exploitation. It offers flexible experimental setup options, standardised logging for reproducibility and fair comparison, incorporates methods for analysing the AAD process (e.g., Code Evolution Graphs and various visualisation approaches) and facilitates comparison against human-designed baselines through integration with established tools like IOHanalyser and IOHexplainer. BLADE provides an `out-of-the-box' solution to systematically evaluate LLM-driven AAD approaches. The framework is demonstrated through two distinct use cases exploring mutation prompt strategies and function specialisation.