 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Palette: Modulating Reasoning via Latent Contextualization for Controllable Exploration for (V)LMs
Dec 19, 2025



Exploration capacity shapes both inference-time performance and reinforcement learning (RL) training for large (vision-) language models, as stochastic sampling often yields redundant reasoning paths with little high-level diversity. This paper proposes Reasoning Palette, a novel latent-modulation framework that endows the model with a stochastic latent variable for strategic contextualization, guiding its internal planning prior to token generation. This latent context is inferred from the mean-pooled embedding of a question-answer pair via a variational autoencoder (VAE), where each sampled latent potentially encodes a distinct reasoning context. During inference, a sampled latent is decoded into learnable token prefixes and prepended to the input prompt, modulating the model's internal reasoning trajectory. In this way, the model performs internal sampling over reasoning strategies prior to output generation, which shapes the style and structure of the entire response sequence. A brief supervised fine-tuning (SFT) warm-up phase allows the model to adapt to this latent conditioning. Within RL optimization, Reasoning Palette facilitates structured exploration by enabling on-demand injection for diverse reasoning modes, significantly enhancing exploration efficiency and sustained learning capability. Experiments across multiple reasoning benchmarks demonstrate that our method enables interpretable and controllable control over the (vision-) language model's strategic behavior, thereby achieving consistent performance gains over standard RL methods.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
Deconstructing Long Chain-of-Thought: A Structured Reasoning Optimization Framework for Long CoT Distillation
Mar 20, 2025Recent advancements in large language models (LLMs) have demonstrated remarkable reasoning capabilities through long chain-of-thought (CoT) reasoning. The R1 distillation scheme has emerged as a promising approach for training cost-effective models with enhanced reasoning abilities. However, the underlying mechanisms driving its effectiveness remain unclear. This study examines the universality of distillation data and identifies key components that enable the efficient transfer of long-chain reasoning capabilities in LLM distillation. Our findings reveal that the effectiveness of long CoT reasoning distillation from teacher models like Qwen-QwQ degrades significantly on nonhomologous models, challenging the assumed universality of current distillation methods. To gain deeper insights into the structure and patterns of long CoT reasoning, we propose DLCoT (Deconstructing Long Chain-of-Thought), a distillation data enhancement framework. DLCoT consists of three key steps: (1) data segmentation to decompose complex long CoT structures, (2) simplification by eliminating unsolvable and redundant solutions, and (3) optimization of intermediate error states. Our approach significantly improves model performance and token efficiency, facilitating the development of high-performance LLMs.
ChineseEcomQA: A Scalable E-commerce Concept Evaluation Benchmark for Large Language Models
Feb 27, 2025
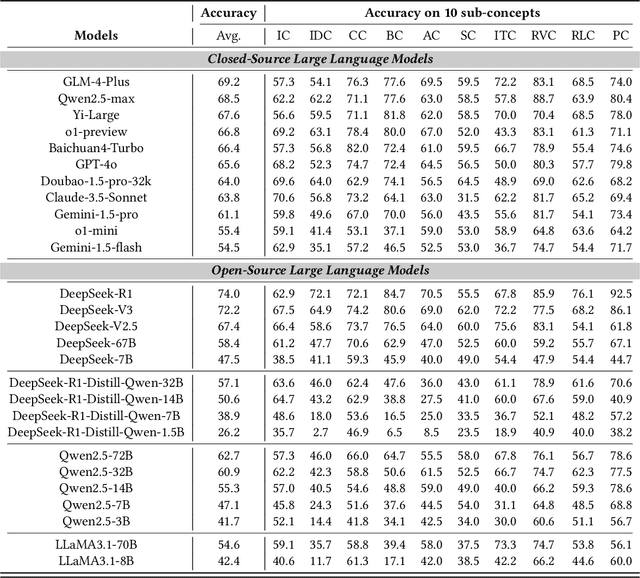
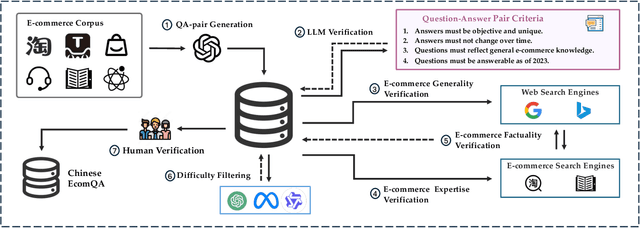

With the increasing use of Large Language Models (LLMs) in fields such as e-commerce, domain-specific concept evaluation benchmarks are crucial for assessing their domain capabilities. Existing LLMs may generate factually incorrect information within the complex e-commerce applications. Therefore, it is necessary to build an e-commerce concept benchmark. Existing benchmarks encounter two primary challenges: (1) handle the heterogeneous and diverse nature of tasks, (2) distinguish between generality and specificity within the e-commerce field. To address these problems, we propose \textbf{ChineseEcomQA}, a scalable question-answering benchmark focused on fundamental e-commerce concepts. ChineseEcomQA is built on three core characteristics: \textbf{Focus on Fundamental Concept}, \textbf{E-commerce Generality} and \textbf{E-commerce Expertise}. Fundamental concepts are designed to be applicable across a diverse array of e-commerce tasks, thus addressing the challenge of heterogeneity and diversity. Additionally, by carefully balancing generality and specificity, ChineseEcomQA effectively differentiates between broad e-commerce concepts, allowing for precise validation of domain capabilities. We achieve this through a scalable benchmark construction process that combines LLM validation, Retrieval-Augmented Generation (RAG) validation, and rigorous manual annotation. Based on ChineseEcomQA, we conduct extensive evaluations on mainstream LLMs and provide some valuable insights. We hope that ChineseEcomQA could guide future domain-specific evaluations, and facilitate broader LLM adoption in e-commerce applications.
Affine Frequency Division Multiplexing: Extending OFDM for Scenario-Flexibility and Resilience
Feb 07, 2025



Next-generation wireless networks are conceived to provide reliable and high-data-rate communication services for diverse scenarios, such as vehicle-to-vehicle, unmanned aerial vehicles, and satellite networks. The severe Doppler spreads in the underlying time-varying channels induce destructive inter-carrier interference (ICI) in the extensively adopted orthogonal frequency division multiplexing (OFDM) waveform, leading to severe performance degradation. This calls for a new air interface design that can accommodate the severe delay-Doppler spreads in highly dynamic channels while possessing sufficient flexibility to cater to various applications. This article provides a comprehensive overview of a promising chirp-based waveform named affine frequency division multiplexing (AFDM). It is featured with two tunable parameters and achieves optimal diversity order in doubly dispersive channels (DDC). We study the fundamental principle of AFDM, illustrating its intrinsic suitability for DDC. Based on that, several potential applications of AFDM are explored. Furthermore, the major challenges and the corresponding solutions of AFDM are presented, followed by several future research directions. Finally, we draw some instructive conclusions about AFDM, hoping to provide useful inspiration for its development.
Adaptive Dense Reward: Understanding the Gap Between Action and Reward Space in Alignment
Oct 23, 2024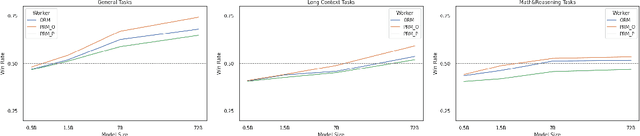
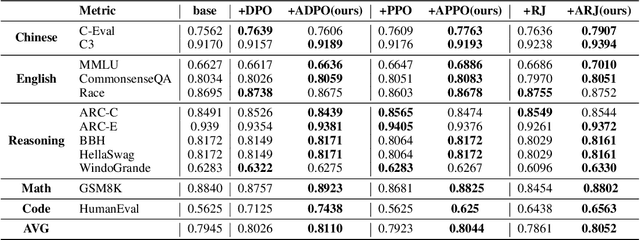
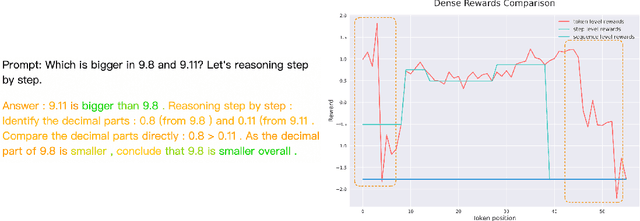
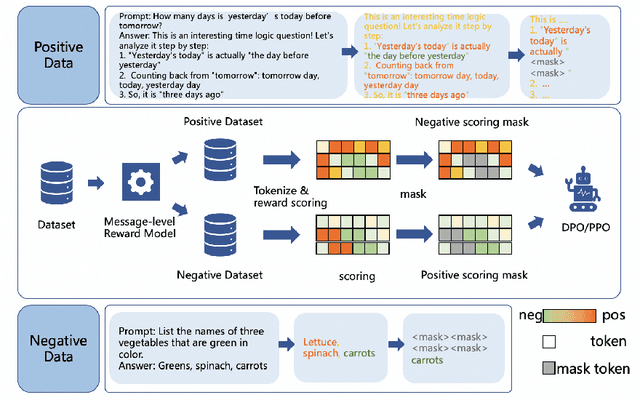
Reinforcement Learning from Human Feedback (RLHF) has proven highly effective in aligning Large Language Models (LLMs) with human preferences. However, the original RLHF typically optimizes under an overall reward, which can lead to a suboptimal learning process. This limitation stems from RLHF's lack of awareness regarding which specific tokens should be reinforced or suppressed. Moreover, conflicts in supervision can arise, for instance, when a chosen response includes erroneous tokens, while a rejected response contains accurate elements. To rectify these shortcomings, increasing dense reward methods, such as step-wise and token-wise RLHF, have been proposed. However, these existing methods are limited to specific tasks (like mathematics). In this paper, we propose the ``Adaptive Message-wise RLHF'' method, which robustly applies to various tasks. By defining pivot tokens as key indicators, our approach adaptively identifies essential information and converts sample-level supervision into fine-grained, subsequence-level supervision. This aligns the density of rewards and action spaces more closely with the information density of the input. Experiments demonstrate that our method can be integrated into various training methods, significantly mitigating hallucinations and catastrophic forgetting problems while outperforming other methods on multiple evaluation metrics. Our method improves the success rate on adversarial samples by 10\% compared to the sample-wise approach and achieves a 1.3\% improvement on evaluation benchmarks such as MMLU, GSM8K, and HumanEval et al.
Step-Back Profiling: Distilling User History for Personalized Scientific Writing
Jun 20, 2024Large language models (LLMs) excel at a variety of natural language processing tasks, yet they struggle to generate personalized content for individuals, particularly in real-world scenarios like scientific writing. Addressing this challenge, we introduce Step-Back Profiling to personalize LLMs by distilling user history into concise profiles, including essential traits and preferences of users. Regarding our experiments, we construct a Personalized Scientific Writing (PSW) dataset to study multiuser personalization. PSW requires the models to write scientific papers given specialized author groups with diverse academic backgrounds. As for the results, we demonstrate the effectiveness of capturing user characteristics via Step-Back Profiling for collaborative writing. Moreover, our approach outperforms the baselines by up to 3.6 points on the general personalization benchmark (LaMP), including 7 personalization LLM tasks. Our extensive ablation studies validate the contributions of different components in our method and provide insights into our task definition. Our dataset and code are available at \url{https://github.com/gersteinlab/step-back-profiling}.
A DAFT Based Unified Waveform Design Framework for High-Mobility Communications
Jun 04, 2024



With the increasing demand for multi-carrier communication in high-mobility scenarios, it is urgent to design new multi-carrier communication waveforms that can resist large delay-Doppler spreads. Various multi-carrier waveforms in the transform domain were proposed for the fast time-varying channels, including orthogonal time frequency space (OTFS), orthogonal chirp division multiplexing (OCDM), and affine frequency division multiplexing (AFDM). Among these, the AFDM is a strong candidate for its low implementation complexity and ability to achieve optimal diversity. This paper unifies the waveforms based on the discrete affine Fourier transform (DAFT) by using the chirp slope factor "k" in the time-frequency representation to construct a unified design framework for high-mobility communications. The design framework is employed to verify that the bit error rate performance of the DAFT-based waveform can be enhanced when the signal-to-noise ratio (SNR) is sufficiently high by adjusting the chirp slope factor "k".
Grounding Language Models for Visual Entity Recognition
Feb 28, 2024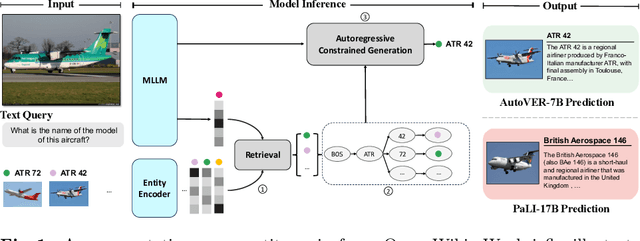
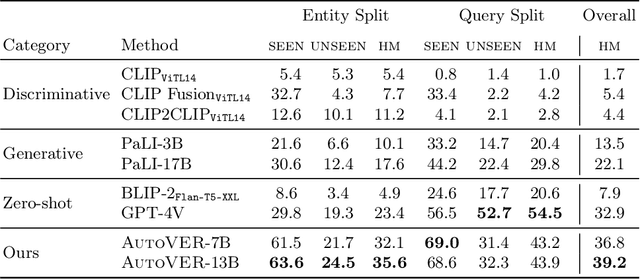
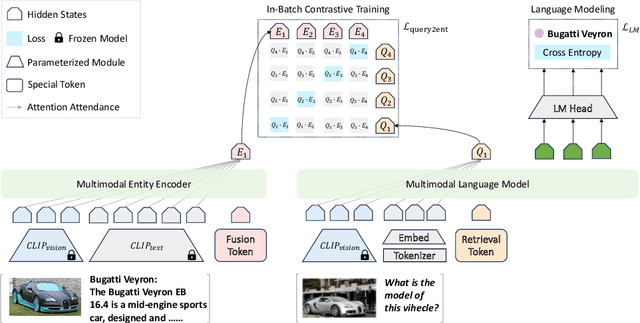
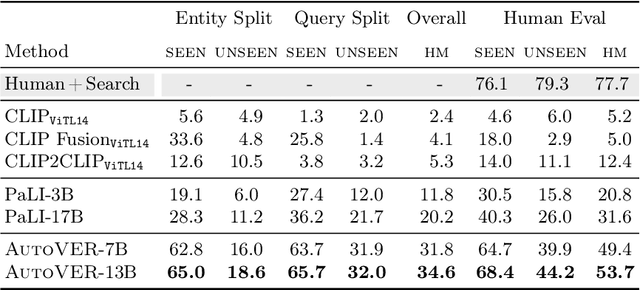
We introduce AutoVER, an Autoregressive model for Visual Entity Recognition. Our model extends an autoregressive Multi-modal Large Language Model by employing retrieval augmented constrained generation. It mitigates low performance on out-of-domain entities while excelling in queries that require visually-situated reasoning. Our method learns to distinguish similar entities within a vast label space by contrastively training on hard negative pairs in parallel with a sequence-to-sequence objective without an external retriever. During inference, a list of retrieved candidate answers explicitly guides language generation by removing invalid decoding paths. The proposed method achieves significant improvements across different dataset splits in the recently proposed Oven-Wiki benchmark. Accuracy on the Entity seen split rises from 32.7% to 61.5%. It also demonstrates superior performance on the unseen and query splits by a substantial double-digit margin.
MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning
Nov 16, 2023Large Language Models (LLMs), despite their remarkable progress across various general domains, encounter significant barriers in medicine and healthcare. This field faces unique challenges such as domain-specific terminologies and the reasoning over specialized knowledge. To address these obstinate issues, we propose a novel Multi-disciplinary Collaboration (MC) framework for the medical domain that leverages role-playing LLM-based agents who participate in a collaborative multi-round discussion, thereby enhancing LLM proficiency and reasoning capabilities. This training-free and interpretable framework encompasses five critical steps: gathering domain experts, proposing individual analyses, summarising these analyses into a report, iterating over discussions until a consensus is reached, and ultimately making a decision. Our work particularly focuses on the zero-shot scenario, our results on nine data sets (MedQA, MedMCQA, PubMedQA, and six subtasks from MMLU) establish that our proposed MC framework excels at mining and harnessing the medical expertise in LLMs, as well as extending its reasoning abilities. Based on these outcomes, we further conduct a human evaluation to pinpoint and categorize common errors within our method, as well as ablation studies aimed at understanding the impact of various factors on overall performance. Our code can be found at \url{https://github.com/gersteinlab/MedAgents}.