 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead As Human: Compressing Context via Parallelizable Close Reading and Skimming
Feb 02, 2026Large Language Models (LLMs) demonstrate exceptional capability across diverse tasks. However, their deployment in long-context scenarios is hindered by two challenges: computational inefficiency and redundant information. We propose RAM (Read As HuMan), a context compression framework that adopts an adaptive hybrid reading strategy, to address these challenges. Inspired by human reading behavior (i.e., close reading important content while skimming less relevant content), RAM partitions the context into segments and encodes them with the input query in parallel. High-relevance segments are fully retained (close reading), while low-relevance ones are query-guided compressed into compact summary vectors (skimming). Both explicit textual segments and implicit summary vectors are concatenated and fed into decoder to achieve both superior performance and natural language format interpretability. To refine the decision boundary between close reading and skimming, we further introduce a contrastive learning objective based on positive and negative query-segment pairs. Experiments demonstrate that RAM outperforms existing baselines on multiple question answering and summarization benchmarks across two backbones, while delivering up to a 12x end-to-end speedup on long inputs (average length 16K; maximum length 32K).
CoMeT: Collaborative Memory Transformer for Efficient Long Context Modeling
Feb 02, 2026The quadratic complexity and indefinitely growing key-value (KV) cache of standard Transformers pose a major barrier to long-context processing. To overcome this, we introduce the Collaborative Memory Transformer (CoMeT), a novel architecture that enables LLMs to handle arbitrarily long sequences with constant memory usage and linear time complexity. Designed as an efficient, plug-in module, CoMeT can be integrated into pre-trained models with only minimal fine-tuning. It operates on sequential data chunks, using a dual-memory system to manage context: a temporary memory on a FIFO queue for recent events, and a global memory with a gated update rule for long-range dependencies. These memories then act as a dynamic soft prompt for the next chunk. To enable efficient fine-tuning on extremely long contexts, we introduce a novel layer-level pipeline parallelism strategy. The effectiveness of our approach is remarkable: a model equipped with CoMeT and fine-tuned on 32k contexts can accurately retrieve a passkey from any position within a 1M token sequence. On the SCROLLS benchmark, CoMeT surpasses other efficient methods and achieves performance comparable to a full-attention baseline on summarization tasks. Its practical effectiveness is further validated on real-world agent and user behavior QA tasks. The code is available at: https://anonymous.4open.science/r/comet-B00B/
Data Distribution Matters: A Data-Centric Perspective on Context Compression for Large Language Model
Feb 02, 2026The deployment of Large Language Models (LLMs) in long-context scenarios is hindered by computational inefficiency and significant information redundancy. Although recent advancements have widely adopted context compression to address these challenges, existing research only focus on model-side improvements, the impact of the data distribution itself on context compression remains largely unexplored. To bridge this gap, we are the first to adopt a data-centric perspective to systematically investigate how data distribution impacts compression quality, including two dimensions: input data and intrinsic data (i.e., the model's internal pretrained knowledge). We evaluate the semantic integrity of compressed representations using an autoencoder-based framework to systematically investigate it. Our experimental results reveal that: (1) encoder-measured input entropy negatively correlates with compression quality, while decoder-measured entropy shows no significant relationship under a frozen-decoder setting; and (2) the gap between intrinsic data of the encoder and decoder significantly diminishes compression gains, which is hard to mitigate. Based on these findings, we further present practical guidelines to optimize compression gains.
PretrainRL: Alleviating Factuality Hallucination of Large Language Models at the Beginning
Feb 02, 2026Large language models (LLMs), despite their powerful capabilities, suffer from factual hallucinations where they generate verifiable falsehoods. We identify a root of this issue: the imbalanced data distribution in the pretraining corpus, which leads to a state of "low-probability truth" and "high-probability falsehood". Recent approaches, such as teaching models to say "I don't know" or post-hoc knowledge editing, either evade the problem or face catastrophic forgetting. To address this issue from its root, we propose \textbf{PretrainRL}, a novel framework that integrates reinforcement learning into the pretraining phase to consolidate factual knowledge. The core principle of PretrainRL is "\textbf{debiasing then learning}." It actively reshapes the model's probability distribution by down-weighting high-probability falsehoods, thereby making "room" for low-probability truths to be learned effectively. To enable this, we design an efficient negative sampling strategy to discover these high-probability falsehoods and introduce novel metrics to evaluate the model's probabilistic state concerning factual knowledge. Extensive experiments on three public benchmarks demonstrate that PretrainRL significantly alleviates factual hallucinations and outperforms state-of-the-art methods.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
ECKGBench: Benchmarking Large Language Models in E-commerce Leveraging Knowledge Graph
Mar 20, 2025Large language models (LLMs) have demonstrated their capabilities across various NLP tasks. Their potential in e-commerce is also substantial, evidenced by practical implementations such as platform search, personalized recommendations, and customer service. One primary concern associated with LLMs is their factuality (e.g., hallucination), which is urgent in e-commerce due to its significant impact on user experience and revenue. Despite some methods proposed to evaluate LLMs' factuality, issues such as lack of reliability, high consumption, and lack of domain expertise leave a gap between effective assessment in e-commerce. To bridge the evaluation gap, we propose ECKGBench, a dataset specifically designed to evaluate the capacities of LLMs in e-commerce knowledge. Specifically, we adopt a standardized workflow to automatically generate questions based on a large-scale knowledge graph, guaranteeing sufficient reliability. We employ the simple question-answering paradigm, substantially improving the evaluation efficiency by the least input and output tokens. Furthermore, we inject abundant e-commerce expertise in each evaluation stage, including human annotation, prompt design, negative sampling, and verification. Besides, we explore the LLMs' knowledge boundaries in e-commerce from a novel perspective. Through comprehensive evaluations of several advanced LLMs on ECKGBench, we provide meticulous analysis and insights into leveraging LLMs for e-commerce.
ChineseEcomQA: A Scalable E-commerce Concept Evaluation Benchmark for Large Language Models
Feb 27, 2025
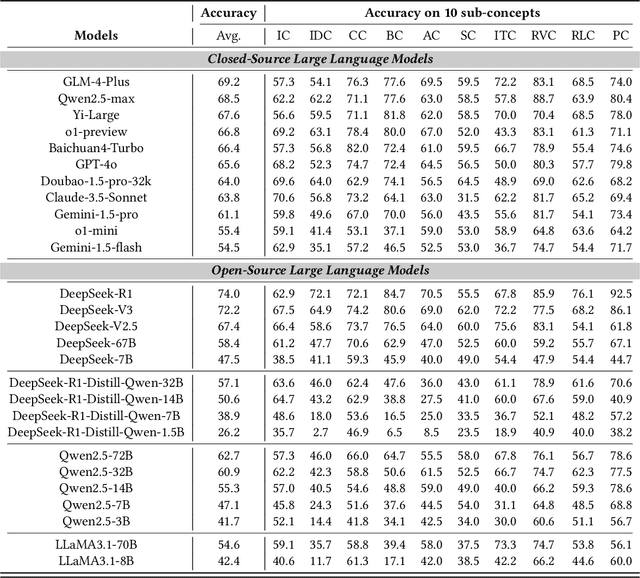
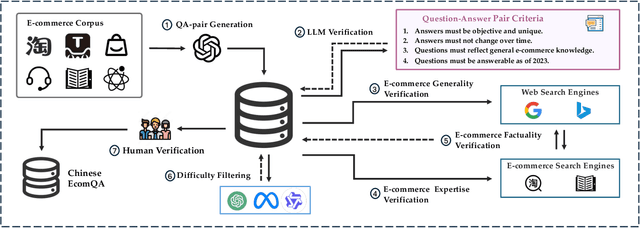

With the increasing use of Large Language Models (LLMs) in fields such as e-commerce, domain-specific concept evaluation benchmarks are crucial for assessing their domain capabilities. Existing LLMs may generate factually incorrect information within the complex e-commerce applications. Therefore, it is necessary to build an e-commerce concept benchmark. Existing benchmarks encounter two primary challenges: (1) handle the heterogeneous and diverse nature of tasks, (2) distinguish between generality and specificity within the e-commerce field. To address these problems, we propose \textbf{ChineseEcomQA}, a scalable question-answering benchmark focused on fundamental e-commerce concepts. ChineseEcomQA is built on three core characteristics: \textbf{Focus on Fundamental Concept}, \textbf{E-commerce Generality} and \textbf{E-commerce Expertise}. Fundamental concepts are designed to be applicable across a diverse array of e-commerce tasks, thus addressing the challenge of heterogeneity and diversity. Additionally, by carefully balancing generality and specificity, ChineseEcomQA effectively differentiates between broad e-commerce concepts, allowing for precise validation of domain capabilities. We achieve this through a scalable benchmark construction process that combines LLM validation, Retrieval-Augmented Generation (RAG) validation, and rigorous manual annotation. Based on ChineseEcomQA, we conduct extensive evaluations on mainstream LLMs and provide some valuable insights. We hope that ChineseEcomQA could guide future domain-specific evaluations, and facilitate broader LLM adoption in e-commerce applications.
Cross-domain Named Entity Recognition via Graph Matching
Aug 02, 2024Cross-domain NER is a practical yet challenging problem since the data scarcity in the real-world scenario. A common practice is first to learn a NER model in a rich-resource general domain and then adapt the model to specific domains. Due to the mismatch problem between entity types across domains, the wide knowledge in the general domain can not effectively transfer to the target domain NER model. To this end, we model the label relationship as a probability distribution and construct label graphs in both source and target label spaces. To enhance the contextual representation with label structures, we fuse the label graph into the word embedding output by BERT. By representing label relationships as graphs, we formulate cross-domain NER as a graph matching problem. Furthermore, the proposed method has good applicability with pre-training methods and is potentially capable of other cross-domain prediction tasks. Empirical results on four datasets show that our method outperforms a series of transfer learning, multi-task learning, and few-shot learning methods.
ConceptMath: A Bilingual Concept-wise Benchmark for Measuring Mathematical Reasoning of Large Language Models
Feb 23, 2024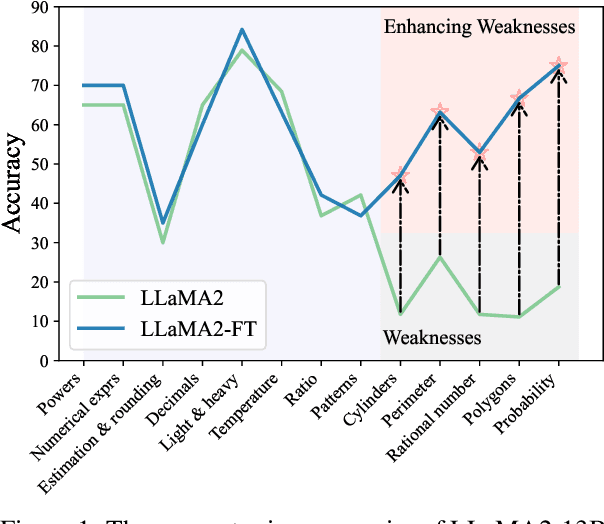
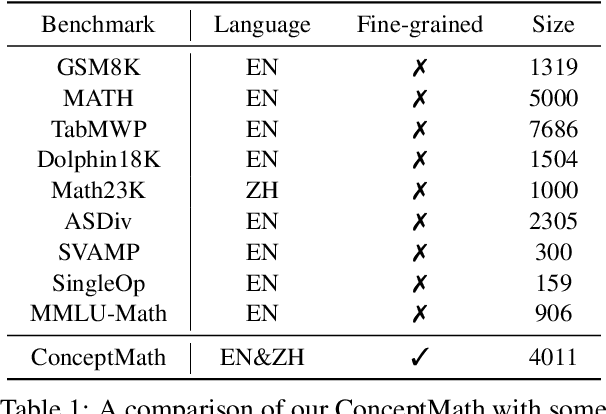
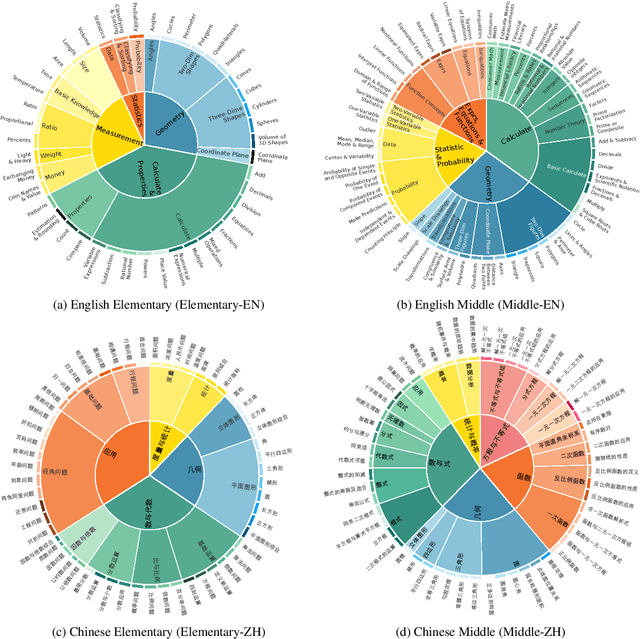
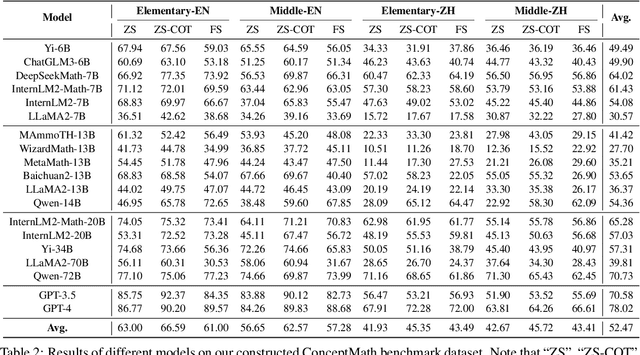
This paper introduces ConceptMath, a bilingual (English and Chinese), fine-grained benchmark that evaluates concept-wise mathematical reasoning of Large Language Models (LLMs). Unlike traditional benchmarks that evaluate general mathematical reasoning with an average accuracy, ConceptMath systematically organizes math problems under a hierarchy of math concepts, so that mathematical reasoning can be evaluated at different granularity with concept-wise accuracies. Based on our ConcepthMath, we evaluate a broad range of LLMs, and we observe existing LLMs, though achieving high average accuracies on traditional benchmarks, exhibit significant performance variations across different math concepts and may even fail catastrophically on the most basic ones. Besides, we also introduce an efficient fine-tuning strategy to enhance the weaknesses of existing LLMs. Finally, we hope ConceptMath could guide the developers to understand the fine-grained mathematical abilities of their models and facilitate the growth of foundation models.
Preserving Commonsense Knowledge from Pre-trained Language Models via Causal Inference
Jun 19, 2023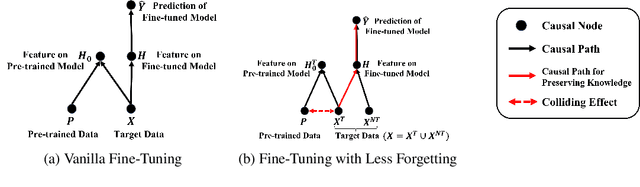
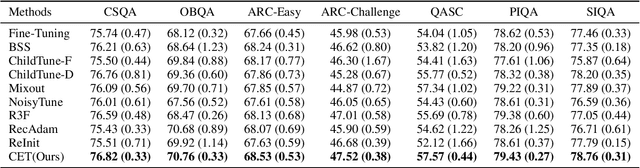
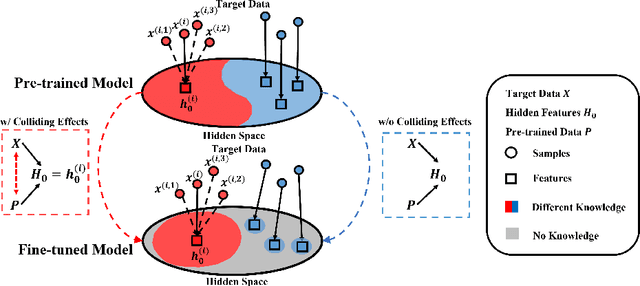
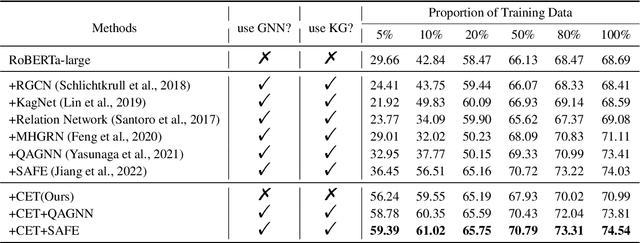
Fine-tuning has been proven to be a simple and effective technique to transfer the learned knowledge of Pre-trained Language Models (PLMs) to downstream tasks. However, vanilla fine-tuning easily overfits the target data and degrades the generalization ability. Most existing studies attribute it to catastrophic forgetting, and they retain the pre-trained knowledge indiscriminately without identifying what knowledge is transferable. Motivated by this, we frame fine-tuning into a causal graph and discover that the crux of catastrophic forgetting lies in the missing causal effects from the pretrained data. Based on the causal view, we propose a unified objective for fine-tuning to retrieve the causality back. Intriguingly, the unified objective can be seen as the sum of the vanilla fine-tuning objective, which learns new knowledge from target data, and the causal objective, which preserves old knowledge from PLMs. Therefore, our method is flexible and can mitigate negative transfer while preserving knowledge. Since endowing models with commonsense is a long-standing challenge, we implement our method on commonsense QA with a proposed heuristic estimation to verify its effectiveness. In the experiments, our method outperforms state-of-the-art fine-tuning methods on all six commonsense QA datasets and can be implemented as a plug-in module to inflate the performance of existing QA models.