 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Lifelong Learning of Large Language Models: A Survey
Jun 10, 2024As the applications of large language models (LLMs) expand across diverse fields, the ability of these models to adapt to ongoing changes in data, tasks, and user preferences becomes crucial. Traditional training methods, relying on static datasets, are increasingly inadequate for coping with the dynamic nature of real-world information. Lifelong learning, also known as continual or incremental learning, addresses this challenge by enabling LLMs to learn continuously and adaptively over their operational lifetime, integrating new knowledge while retaining previously learned information and preventing catastrophic forgetting. This survey delves into the sophisticated landscape of lifelong learning, categorizing strategies into two primary groups: Internal Knowledge and External Knowledge. Internal Knowledge includes continual pretraining and continual finetuning, each enhancing the adaptability of LLMs in various scenarios. External Knowledge encompasses retrieval-based and tool-based lifelong learning, leveraging external data sources and computational tools to extend the model's capabilities without modifying core parameters. The key contributions of our survey are: (1) Introducing a novel taxonomy categorizing the extensive literature of lifelong learning into 12 scenarios; (2) Identifying common techniques across all lifelong learning scenarios and classifying existing literature into various technique groups within each scenario; (3) Highlighting emerging techniques such as model expansion and data selection, which were less explored in the pre-LLM era. Through a detailed examination of these groups and their respective categories, this survey aims to enhance the adaptability, reliability, and overall performance of LLMs in real-world applications.
Incremental Sequence Labeling: A Tale of Two Shifts
Feb 16, 2024



The incremental sequence labeling task involves continuously learning new classes over time while retaining knowledge of the previous ones. Our investigation identifies two significant semantic shifts: E2O (where the model mislabels an old entity as a non-entity) and O2E (where the model labels a non-entity or old entity as a new entity). Previous research has predominantly focused on addressing the E2O problem, neglecting the O2E issue. This negligence results in a model bias towards classifying new data samples as belonging to the new class during the learning process. To address these challenges, we propose a novel framework, Incremental Sequential Labeling without Semantic Shifts (IS3). Motivated by the identified semantic shifts (E2O and O2E), IS3 aims to mitigate catastrophic forgetting in models. As for the E2O problem, we use knowledge distillation to maintain the model's discriminative ability for old entities. Simultaneously, to tackle the O2E problem, we alleviate the model's bias towards new entities through debiased loss and optimization levels. Our experimental evaluation, conducted on three datasets with various incremental settings, demonstrates the superior performance of IS3 compared to the previous state-of-the-art method by a significant margin.
Concept-1K: A Novel Benchmark for Instance Incremental Learning
Feb 13, 2024Incremental learning (IL) is essential to realize the human-level intelligence in the neural network. However, existing IL scenarios and datasets are unqualified for assessing forgetting in PLMs, giving an illusion that PLMs do not suffer from catastrophic forgetting. To this end, we propose a challenging IL scenario called instance-incremental learning (IIL) and a novel dataset called Concept-1K, which supports an order of magnitude larger IL steps. Based on the experiments on Concept-1K, we reveal that billion-parameter PLMs still suffer from catastrophic forgetting, and the forgetting is affected by both model scale, pretraining, and buffer size. Furthermore, existing IL methods and a popular finetuning technique, LoRA, fail to achieve satisfactory performance. Our study provides a novel scenario for future studies to explore the catastrophic forgetting of PLMs and encourage more powerful techniques to be designed for alleviating the forgetting in PLMs. The data, code and scripts are publicly available at https://github.com/zzz47zzz/pretrained-lm-for-incremental-learning.
Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models
Dec 13, 2023Incremental Learning (IL) has been a long-standing problem in both vision and Natural Language Processing (NLP) communities. In recent years, as Pre-trained Language Models (PLMs) have achieved remarkable progress in various NLP downstream tasks, utilizing PLMs as backbones has become a common practice in recent research of IL in NLP. Most assume that catastrophic forgetting is the biggest obstacle to achieving superior IL performance and propose various techniques to overcome this issue. However, we find that this assumption is problematic. Specifically, we revisit more than 20 methods on four classification tasks (Text Classification, Intent Classification, Relation Extraction, and Named Entity Recognition) under the two most popular IL settings (Class-Incremental and Task-Incremental) and reveal that most of them severely underestimate the inherent anti-forgetting ability of PLMs. Based on the observation, we propose a frustratingly easy method called SEQ* for IL with PLMs. The results show that SEQ* has competitive or superior performance compared to state-of-the-art (SOTA) IL methods and requires considerably less trainable parameters and training time. These findings urge us to revisit the IL with PLMs and encourage future studies to have a fundamental understanding of the catastrophic forgetting in PLMs. The data, code and scripts are publicly available at https://github.com/zzz47zzz/pretrained-lm-for-incremental-learning.
Preserving Commonsense Knowledge from Pre-trained Language Models via Causal Inference
Jun 19, 2023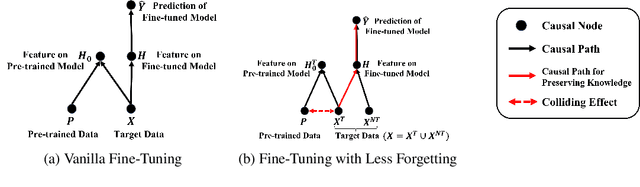
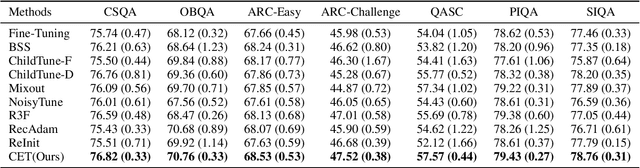
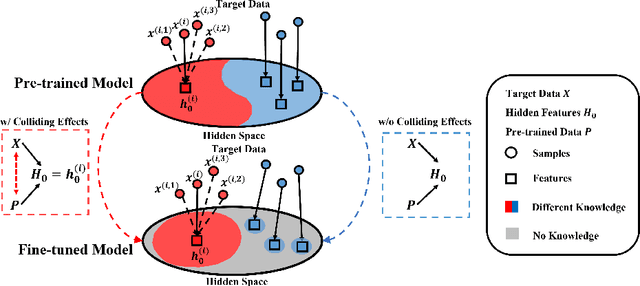
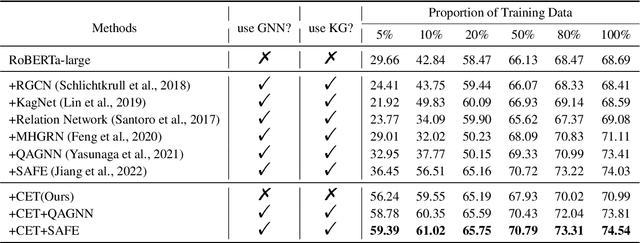
Fine-tuning has been proven to be a simple and effective technique to transfer the learned knowledge of Pre-trained Language Models (PLMs) to downstream tasks. However, vanilla fine-tuning easily overfits the target data and degrades the generalization ability. Most existing studies attribute it to catastrophic forgetting, and they retain the pre-trained knowledge indiscriminately without identifying what knowledge is transferable. Motivated by this, we frame fine-tuning into a causal graph and discover that the crux of catastrophic forgetting lies in the missing causal effects from the pretrained data. Based on the causal view, we propose a unified objective for fine-tuning to retrieve the causality back. Intriguingly, the unified objective can be seen as the sum of the vanilla fine-tuning objective, which learns new knowledge from target data, and the causal objective, which preserves old knowledge from PLMs. Therefore, our method is flexible and can mitigate negative transfer while preserving knowledge. Since endowing models with commonsense is a long-standing challenge, we implement our method on commonsense QA with a proposed heuristic estimation to verify its effectiveness. In the experiments, our method outperforms state-of-the-art fine-tuning methods on all six commonsense QA datasets and can be implemented as a plug-in module to inflate the performance of existing QA models.