 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Adaptive Reconstruction with Contrastive Learning for Unsupervised Sentence Embeddings
Feb 23, 2024
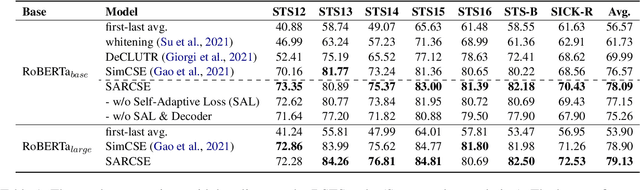
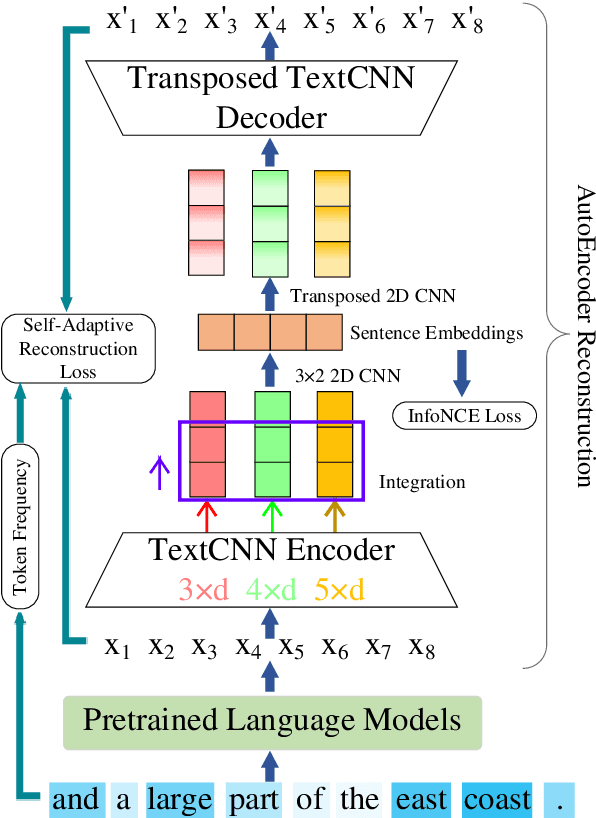
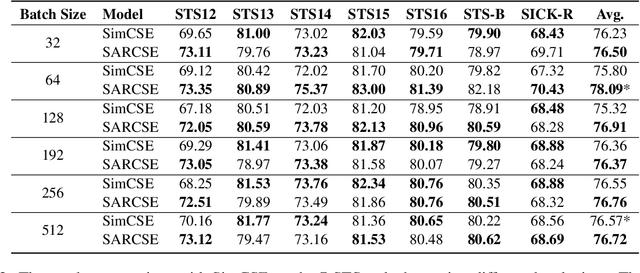
Unsupervised sentence embeddings task aims to convert sentences to semantic vector representations. Most previous works directly use the sentence representations derived from pretrained language models. However, due to the token bias in pretrained language models, the models can not capture the fine-grained semantics in sentences, which leads to poor predictions. To address this issue, we propose a novel Self-Adaptive Reconstruction Contrastive Sentence Embeddings (SARCSE) framework, which reconstructs all tokens in sentences with an AutoEncoder to help the model to preserve more fine-grained semantics during tokens aggregating. In addition, we proposed a self-adaptive reconstruction loss to alleviate the token bias towards frequency. Experimental results show that SARCSE gains significant improvements compared with the strong baseline SimCSE on the 7 STS tasks.
Preserving Commonsense Knowledge from Pre-trained Language Models via Causal Inference
Jun 19, 2023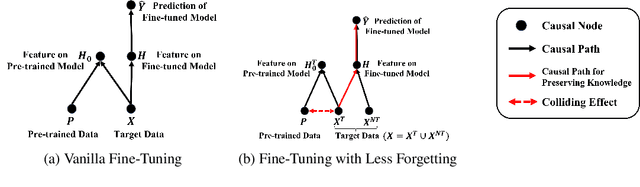
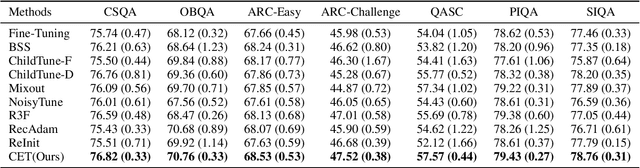
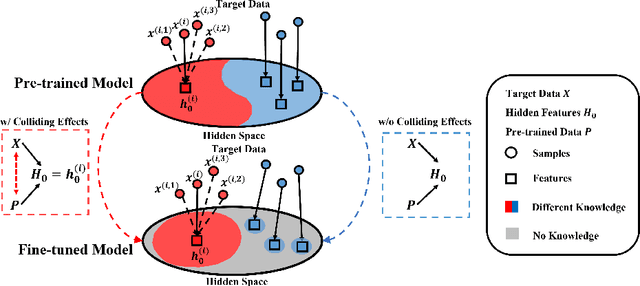
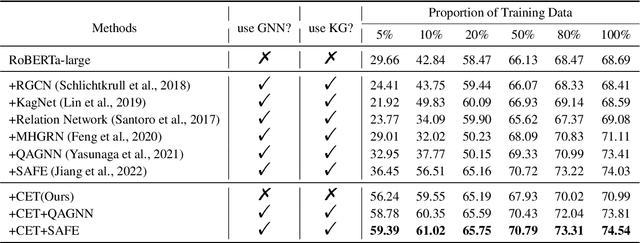
Fine-tuning has been proven to be a simple and effective technique to transfer the learned knowledge of Pre-trained Language Models (PLMs) to downstream tasks. However, vanilla fine-tuning easily overfits the target data and degrades the generalization ability. Most existing studies attribute it to catastrophic forgetting, and they retain the pre-trained knowledge indiscriminately without identifying what knowledge is transferable. Motivated by this, we frame fine-tuning into a causal graph and discover that the crux of catastrophic forgetting lies in the missing causal effects from the pretrained data. Based on the causal view, we propose a unified objective for fine-tuning to retrieve the causality back. Intriguingly, the unified objective can be seen as the sum of the vanilla fine-tuning objective, which learns new knowledge from target data, and the causal objective, which preserves old knowledge from PLMs. Therefore, our method is flexible and can mitigate negative transfer while preserving knowledge. Since endowing models with commonsense is a long-standing challenge, we implement our method on commonsense QA with a proposed heuristic estimation to verify its effectiveness. In the experiments, our method outperforms state-of-the-art fine-tuning methods on all six commonsense QA datasets and can be implemented as a plug-in module to inflate the performance of existing QA models.
Pair-Based Joint Encoding with Relational Graph Convolutional Networks for Emotion-Cause Pair Extraction
Dec 04, 2022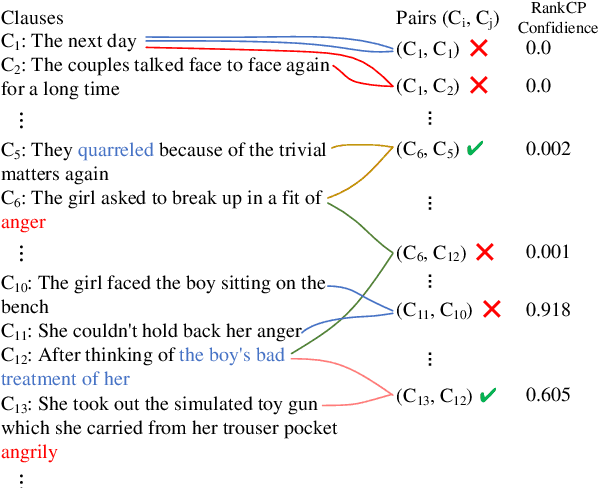
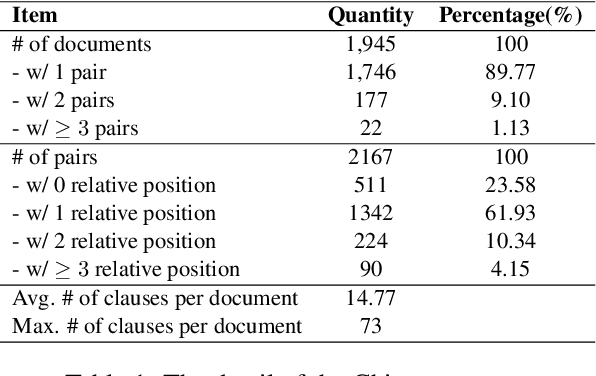
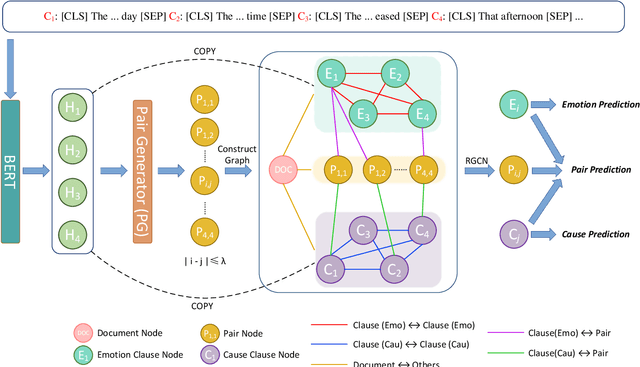
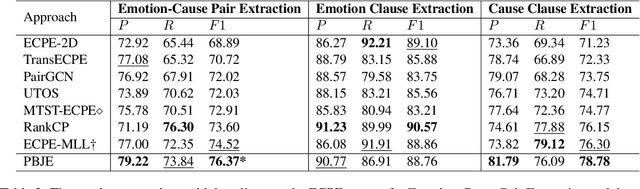
Emotion-cause pair extraction (ECPE) aims to extract emotion clauses and corresponding cause clauses, which have recently received growing attention. Previous methods sequentially encode features with a specified order. They first encode the emotion and cause features for clause extraction and then combine them for pair extraction. This lead to an imbalance in inter-task feature interaction where features extracted later have no direct contact with the former. To address this issue, we propose a novel Pair-Based Joint Encoding (PBJE) network, which generates pairs and clauses features simultaneously in a joint feature encoding manner to model the causal relationship in clauses. PBJE can balance the information flow among emotion clauses, cause clauses and pairs. From a multi-relational perspective, we construct a heterogeneous undirected graph and apply the Relational Graph Convolutional Network (RGCN) to capture the various relationship between clauses and the relationship between pairs and clauses. Experimental results show that PBJE achieves state-of-the-art performance on the Chinese benchmark corpus.