 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Adaptive Reconstruction with Contrastive Learning for Unsupervised Sentence Embeddings
Paper and Code

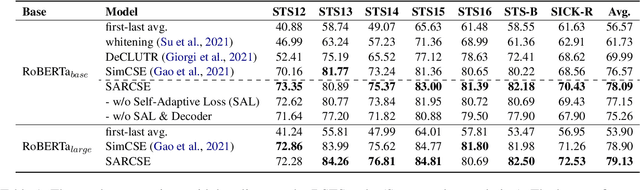
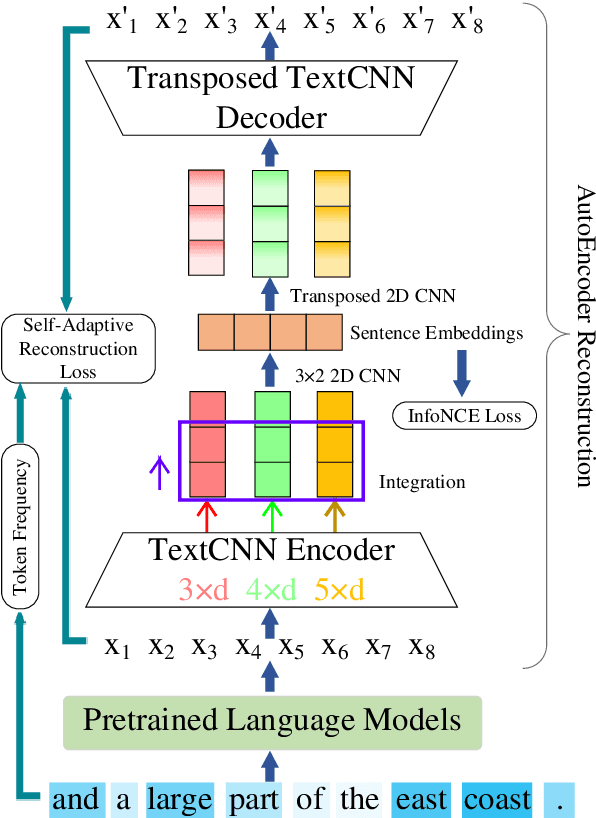
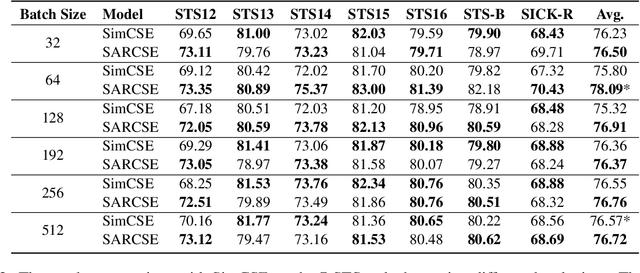
Unsupervised sentence embeddings task aims to convert sentences to semantic vector representations. Most previous works directly use the sentence representations derived from pretrained language models. However, due to the token bias in pretrained language models, the models can not capture the fine-grained semantics in sentences, which leads to poor predictions. To address this issue, we propose a novel Self-Adaptive Reconstruction Contrastive Sentence Embeddings (SARCSE) framework, which reconstructs all tokens in sentences with an AutoEncoder to help the model to preserve more fine-grained semantics during tokens aggregating. In addition, we proposed a self-adaptive reconstruction loss to alleviate the token bias towards frequency. Experimental results show that SARCSE gains significant improvements compared with the strong baseline SimCSE on the 7 STS tasks.