 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperIMTS: Hypergraph Neural Network for Irregular Multivariate Time Series Forecasting
May 23, 2025Irregular multivariate time series (IMTS) are characterized by irregular time intervals within variables and unaligned observations across variables, posing challenges in learning temporal and variable dependencies. Many existing IMTS models either require padded samples to learn separately from temporal and variable dimensions, or represent original samples via bipartite graphs or sets. However, the former approaches often need to handle extra padding values affecting efficiency and disrupting original sampling patterns, while the latter ones have limitations in capturing dependencies among unaligned observations. To represent and learn both dependencies from original observations in a unified form, we propose HyperIMTS, a Hypergraph neural network for Irregular Multivariate Time Series forecasting. Observed values are converted as nodes in the hypergraph, interconnected by temporal and variable hyperedges to enable message passing among all observations. Through irregularity-aware message passing, HyperIMTS captures variable dependencies in a time-adaptive way to achieve accurate forecasting. Experiments demonstrate HyperIMTS's competitive performance among state-of-the-art models in IMTS forecasting with low computational cost.
Learning Soft Sparse Shapes for Efficient Time-Series Classification
May 11, 2025Shapelets are discriminative subsequences (or shapes) with high interpretability in time series classification. Due to the time-intensive nature of shapelet discovery, existing shapelet-based methods mainly focus on selecting discriminative shapes while discarding others to achieve candidate subsequence sparsification. However, this approach may exclude beneficial shapes and overlook the varying contributions of shapelets to classification performance. To this end, we propose a \textbf{Soft} sparse \textbf{Shape}s (\textbf{SoftShape}) model for efficient time series classification. Our approach mainly introduces soft shape sparsification and soft shape learning blocks. The former transforms shapes into soft representations based on classification contribution scores, merging lower-scored ones into a single shape to retain and differentiate all subsequence information. The latter facilitates intra- and inter-shape temporal pattern learning, improving model efficiency by using sparsified soft shapes as inputs. Specifically, we employ a learnable router to activate a subset of class-specific expert networks for intra-shape pattern learning. Meanwhile, a shared expert network learns inter-shape patterns by converting sparsified shapes into sequences. Extensive experiments show that SoftShape outperforms state-of-the-art methods and produces interpretable results.
Learning Dynamic Tasks on a Large-scale Soft Robot in a Handful of Trials
Nov 13, 2024
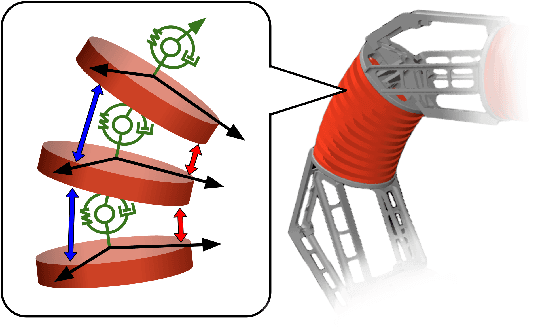
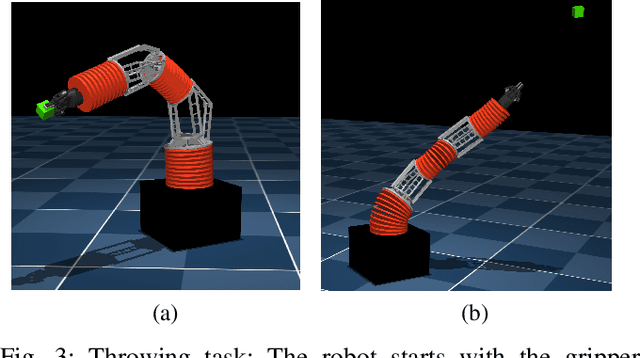
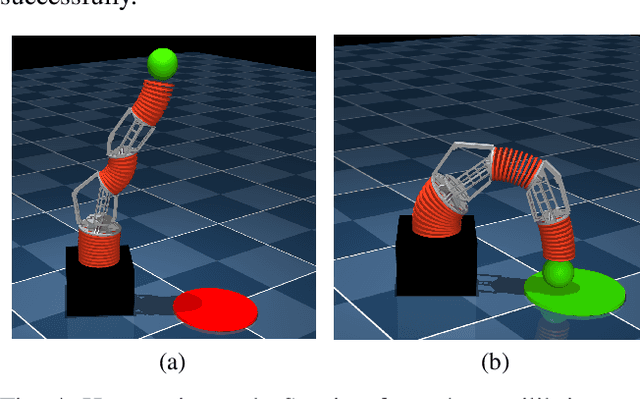
Soft robots offer more flexibility, compliance, and adaptability than traditional rigid robots. They are also typically lighter and cheaper to manufacture. However, their use in real-world applications is limited due to modeling challenges and difficulties in integrating effective proprioceptive sensors. Large-scale soft robots ($\approx$ two meters in length) have greater modeling complexity due to increased inertia and related effects of gravity. Common efforts to ease these modeling difficulties such as assuming simple kinematic and dynamics models also limit the general capabilities of soft robots and are not applicable in tasks requiring fast, dynamic motion like throwing and hammering. To overcome these challenges, we propose a data-efficient Bayesian optimization-based approach for learning control policies for dynamic tasks on a large-scale soft robot. Our approach optimizes the task objective function directly from commanded pressures, without requiring approximate kinematics or dynamics as an intermediate step. We demonstrate the effectiveness of our approach through both simulated and real-world experiments.
Incremental Sequence Labeling: A Tale of Two Shifts
Feb 16, 2024



The incremental sequence labeling task involves continuously learning new classes over time while retaining knowledge of the previous ones. Our investigation identifies two significant semantic shifts: E2O (where the model mislabels an old entity as a non-entity) and O2E (where the model labels a non-entity or old entity as a new entity). Previous research has predominantly focused on addressing the E2O problem, neglecting the O2E issue. This negligence results in a model bias towards classifying new data samples as belonging to the new class during the learning process. To address these challenges, we propose a novel framework, Incremental Sequential Labeling without Semantic Shifts (IS3). Motivated by the identified semantic shifts (E2O and O2E), IS3 aims to mitigate catastrophic forgetting in models. As for the E2O problem, we use knowledge distillation to maintain the model's discriminative ability for old entities. Simultaneously, to tackle the O2E problem, we alleviate the model's bias towards new entities through debiased loss and optimization levels. Our experimental evaluation, conducted on three datasets with various incremental settings, demonstrates the superior performance of IS3 compared to the previous state-of-the-art method by a significant margin.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023



A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
H-GAP: Humanoid Control with a Generalist Planner
Dec 05, 2023



Humanoid control is an important research challenge offering avenues for integration into human-centric infrastructures and enabling physics-driven humanoid animations. The daunting challenges in this field stem from the difficulty of optimizing in high-dimensional action spaces and the instability introduced by the bipedal morphology of humanoids. However, the extensive collection of human motion-captured data and the derived datasets of humanoid trajectories, such as MoCapAct, paves the way to tackle these challenges. In this context, we present Humanoid Generalist Autoencoding Planner (H-GAP), a state-action trajectory generative model trained on humanoid trajectories derived from human motion-captured data, capable of adeptly handling downstream control tasks with Model Predictive Control (MPC). For 56 degrees of freedom humanoid, we empirically demonstrate that H-GAP learns to represent and generate a wide range of motor behaviours. Further, without any learning from online interactions, it can also flexibly transfer these behaviors to solve novel downstream control tasks via planning. Notably, H-GAP excels established MPC baselines that have access to the ground truth dynamics model, and is superior or comparable to offline RL methods trained for individual tasks. Finally, we do a series of empirical studies on the scaling properties of H-GAP, showing the potential for performance gains via additional data but not computing. Code and videos are available at https://ycxuyingchen.github.io/hgap/.
ChessGPT: Bridging Policy Learning and Language Modeling
Jun 15, 2023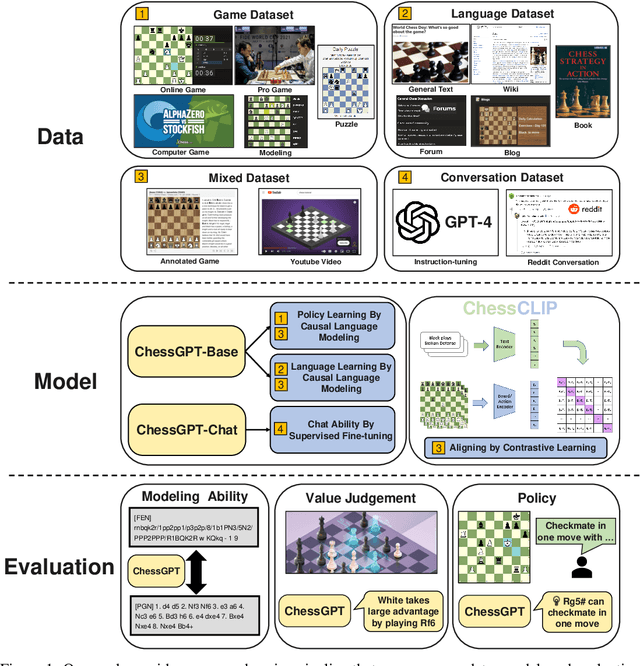
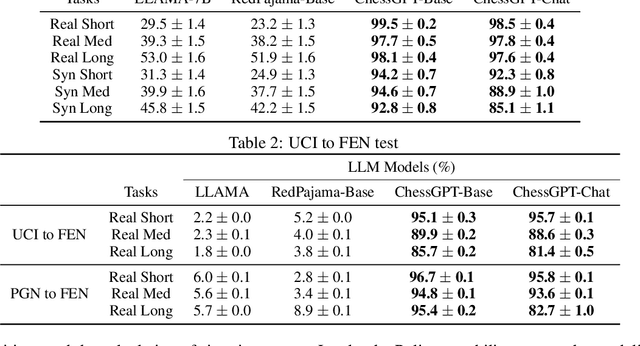
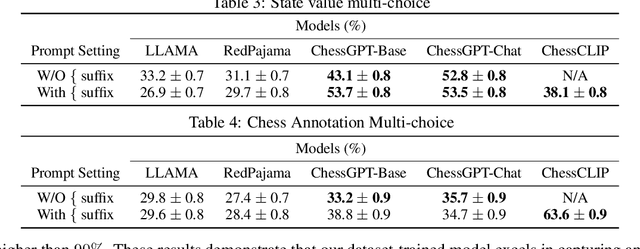
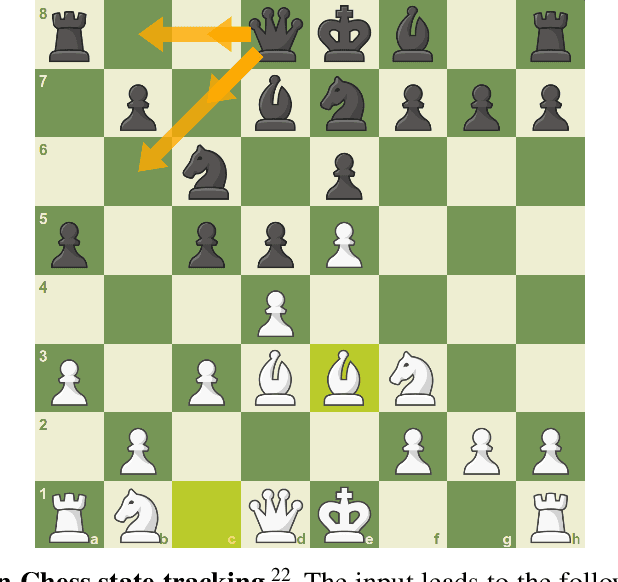
When solving decision-making tasks, humans typically depend on information from two key sources: (1) Historical policy data, which provides interaction replay from the environment, and (2) Analytical insights in natural language form, exposing the invaluable thought process or strategic considerations. Despite this, the majority of preceding research focuses on only one source: they either use historical replay exclusively to directly learn policy or value functions, or engaged in language model training utilizing mere language corpus. In this paper, we argue that a powerful autonomous agent should cover both sources. Thus, we propose ChessGPT, a GPT model bridging policy learning and language modeling by integrating data from these two sources in Chess games. Specifically, we build a large-scale game and language dataset related to chess. Leveraging the dataset, we showcase two model examples ChessCLIP and ChessGPT, integrating policy learning and language modeling. Finally, we propose a full evaluation framework for evaluating language model's chess ability. Experimental results validate our model and dataset's effectiveness. We open source our code, model, and dataset at https://github.com/waterhorse1/ChessGPT.
Finetuning from Offline Reinforcement Learning: Challenges, Trade-offs and Practical Solutions
Mar 30, 2023Offline reinforcement learning (RL) allows for the training of competent agents from offline datasets without any interaction with the environment. Online finetuning of such offline models can further improve performance. But how should we ideally finetune agents obtained from offline RL training? While offline RL algorithms can in principle be used for finetuning, in practice, their online performance improves slowly. In contrast, we show that it is possible to use standard online off-policy algorithms for faster improvement. However, we find this approach may suffer from policy collapse, where the policy undergoes severe performance deterioration during initial online learning. We investigate the issue of policy collapse and how it relates to data diversity, algorithm choices and online replay distribution. Based on these insights, we propose a conservative policy optimization procedure that can achieve stable and sample-efficient online learning from offline pretraining.
Optimal Transport for Offline Imitation Learning
Mar 24, 2023



With the advent of large datasets, offline reinforcement learning (RL) is a promising framework for learning good decision-making policies without the need to interact with the real environment. However, offline RL requires the dataset to be reward-annotated, which presents practical challenges when reward engineering is difficult or when obtaining reward annotations is labor-intensive. In this paper, we introduce Optimal Transport Reward labeling (OTR), an algorithm that assigns rewards to offline trajectories, with a few high-quality demonstrations. OTR's key idea is to use optimal transport to compute an optimal alignment between an unlabeled trajectory in the dataset and an expert demonstration to obtain a similarity measure that can be interpreted as a reward, which can then be used by an offline RL algorithm to learn the policy. OTR is easy to implement and computationally efficient. On D4RL benchmarks, we show that OTR with a single demonstration can consistently match the performance of offline RL with ground-truth rewards.
Learning to Construct 3D Building Wireframes from 3D Line Clouds
Aug 25, 2022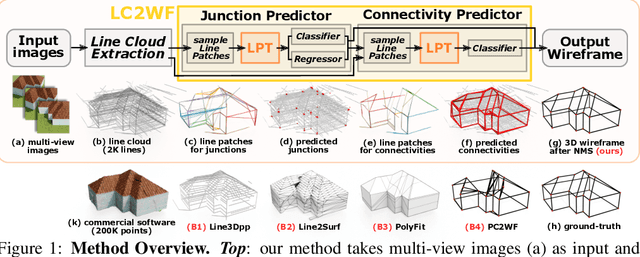
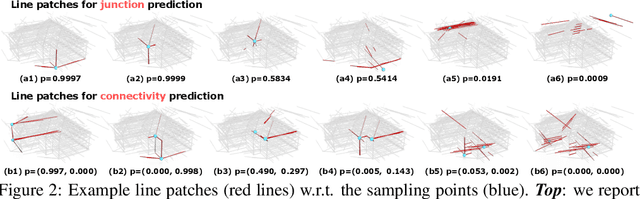

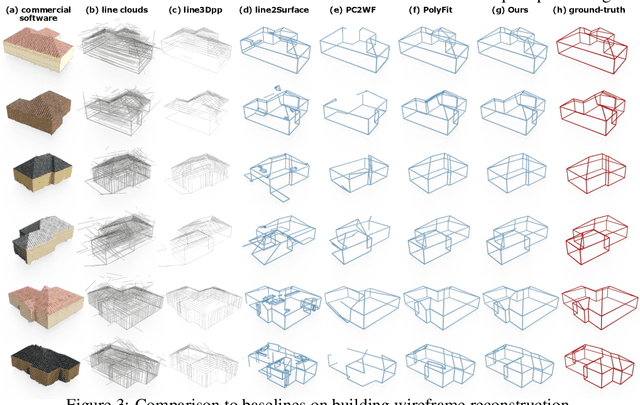
Line clouds, though under-investigated in the previous work, potentially encode more compact structural information of buildings than point clouds extracted from multi-view images. In this work, we propose the first network to process line clouds for building wireframe abstraction. The network takes a line cloud as input , i.e., a nonstructural and unordered set of 3D line segments extracted from multi-view images, and outputs a 3D wireframe of the underlying building, which consists of a sparse set of 3D junctions connected by line segments. We observe that a line patch, i.e., a group of neighboring line segments, encodes sufficient contour information to predict the existence and even the 3D position of a potential junction, as well as the likelihood of connectivity between two query junctions. We therefore introduce a two-layer Line-Patch Transformer to extract junctions and connectivities from sampled line patches to form a 3D building wireframe model. We also introduce a synthetic dataset of multi-view images with ground-truth 3D wireframe. We extensively justify that our reconstructed 3D wireframe models significantly improve upon multiple baseline building reconstruction methods.