 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeNeRF: Edge-Guided Regularization for Neural Radiance Fields from Sparse Views
Jan 04, 2026Neural Radiance Fields (NeRF) achieve remarkable performance in dense multi-view scenarios, but their reconstruction quality degrades significantly under sparse inputs due to geometric artifacts. Existing methods utilize global depth regularization to mitigate artifacts, leading to the loss of geometric boundary details. To address this problem, we propose EdgeNeRF, an edge-guided sparse-view 3D reconstruction algorithm. Our method leverages the prior that abrupt changes in depth and normals generate edges. Specifically, we first extract edges from input images, then apply depth and normal regularization constraints to non-edge regions, enhancing geometric consistency while preserving high-frequency details at boundaries. Experiments on LLFF and DTU datasets demonstrate EdgeNeRF's superior performance, particularly in retaining sharp geometric boundaries and suppressing artifacts. Additionally, the proposed edge-guided depth regularization module can be seamlessly integrated into other methods in a plug-and-play manner, significantly improving their performance without substantially increasing training time. Code is available at https://github.com/skyhigh404/edgenerf.
PathFinder: Advancing Path Loss Prediction for Single-to-Multi-Transmitter Scenario
Dec 16, 2025Radio path loss prediction (RPP) is critical for optimizing 5G networks and enabling IoT, smart city, and similar applications. However, current deep learning-based RPP methods lack proactive environmental modeling, struggle with realistic multi-transmitter scenarios, and generalize poorly under distribution shifts, particularly when training/testing environments differ in building density or transmitter configurations. This paper identifies three key issues: (1) passive environmental modeling that overlooks transmitters and key environmental features; (2) overemphasis on single-transmitter scenarios despite real-world multi-transmitter prevalence; (3) excessive focus on in-distribution performance while neglecting distribution shift challenges. To address these, we propose PathFinder, a novel architecture that actively models buildings and transmitters via disentangled feature encoding and integrates Mask-Guided Low-rank Attention to independently focus on receiver and building regions. We also introduce a Transmitter-Oriented Mixup strategy for robust training and a new benchmark, single-to-multi-transmitter RPP (S2MT-RPP), tailored to evaluate extrapolation performance (multi-transmitter testing after single-transmitter training). Experimental results show PathFinder outperforms state-of-the-art methods significantly, especially in challenging multi-transmitter scenarios. Our code and project site are available at: https://emorzz1g.github.io/PathFinder/.
FS-Diff: Semantic guidance and clarity-aware simultaneous multimodal image fusion and super-resolution
Sep 11, 2025As an influential information fusion and low-level vision technique, image fusion integrates complementary information from source images to yield an informative fused image. A few attempts have been made in recent years to jointly realize image fusion and super-resolution. However, in real-world applications such as military reconnaissance and long-range detection missions, the target and background structures in multimodal images are easily corrupted, with low resolution and weak semantic information, which leads to suboptimal results in current fusion techniques. In response, we propose FS-Diff, a semantic guidance and clarity-aware joint image fusion and super-resolution method. FS-Diff unifies image fusion and super-resolution as a conditional generation problem. It leverages semantic guidance from the proposed clarity sensing mechanism for adaptive low-resolution perception and cross-modal feature extraction. Specifically, we initialize the desired fused result as pure Gaussian noise and introduce the bidirectional feature Mamba to extract the global features of the multimodal images. Moreover, utilizing the source images and semantics as conditions, we implement a random iterative denoising process via a modified U-Net network. This network istrained for denoising at multiple noise levels to produce high-resolution fusion results with cross-modal features and abundant semantic information. We also construct a powerful aerial view multiscene (AVMS) benchmark covering 600 pairs of images. Extensive joint image fusion and super-resolution experiments on six public and our AVMS datasets demonstrated that FS-Diff outperforms the state-of-the-art methods at multiple magnifications and can recover richer details and semantics in the fused images. The code is available at https://github.com/XylonXu01/FS-Diff.
The Silent Saboteur: Imperceptible Adversarial Attacks against Black-Box Retrieval-Augmented Generation Systems
May 24, 2025



We explore adversarial attacks against retrieval-augmented generation (RAG) systems to identify their vulnerabilities. We focus on generating human-imperceptible adversarial examples and introduce a novel imperceptible retrieve-to-generate attack against RAG. This task aims to find imperceptible perturbations that retrieve a target document, originally excluded from the initial top-$k$ candidate set, in order to influence the final answer generation. To address this task, we propose ReGENT, a reinforcement learning-based framework that tracks interactions between the attacker and the target RAG and continuously refines attack strategies based on relevance-generation-naturalness rewards. Experiments on newly constructed factual and non-factual question-answering benchmarks demonstrate that ReGENT significantly outperforms existing attack methods in misleading RAG systems with small imperceptible text perturbations.
HyperIMTS: Hypergraph Neural Network for Irregular Multivariate Time Series Forecasting
May 23, 2025Irregular multivariate time series (IMTS) are characterized by irregular time intervals within variables and unaligned observations across variables, posing challenges in learning temporal and variable dependencies. Many existing IMTS models either require padded samples to learn separately from temporal and variable dimensions, or represent original samples via bipartite graphs or sets. However, the former approaches often need to handle extra padding values affecting efficiency and disrupting original sampling patterns, while the latter ones have limitations in capturing dependencies among unaligned observations. To represent and learn both dependencies from original observations in a unified form, we propose HyperIMTS, a Hypergraph neural network for Irregular Multivariate Time Series forecasting. Observed values are converted as nodes in the hypergraph, interconnected by temporal and variable hyperedges to enable message passing among all observations. Through irregularity-aware message passing, HyperIMTS captures variable dependencies in a time-adaptive way to achieve accurate forecasting. Experiments demonstrate HyperIMTS's competitive performance among state-of-the-art models in IMTS forecasting with low computational cost.
EasyFS: an Efficient Model-free Feature Selection Framework via Elastic Transformation of Features
Feb 04, 2024



Traditional model-free feature selection methods treat each feature independently while disregarding the interrelationships among features, which leads to relatively poor performance compared with the model-aware methods. To address this challenge, we propose an efficient model-free feature selection framework via elastic expansion and compression of the features, namely EasyFS, to achieve better performance than state-of-the-art model-aware methods while sharing the characters of efficiency and flexibility with the existing model-free methods. In particular, EasyFS expands the feature space by using the random non-linear projection network to achieve the non-linear combinations of the original features, so as to model the interrelationships among the features and discover most correlated features. Meanwhile, a novel redundancy measurement based on the change of coding rate is proposed for efficient filtering of redundant features. Comprehensive experiments on 21 different datasets show that EasyFS outperforms state-of-the art methods up to 10.9\% in the regression tasks and 5.7\% in the classification tasks while saving more than 94\% of the time.
AVR: Attention based Salient Visual Relationship Detection
Mar 16, 2020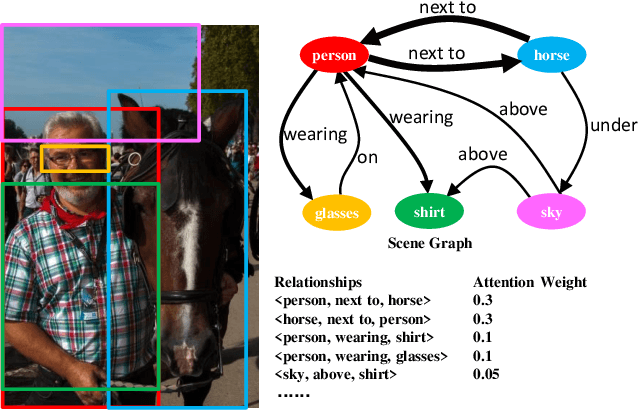
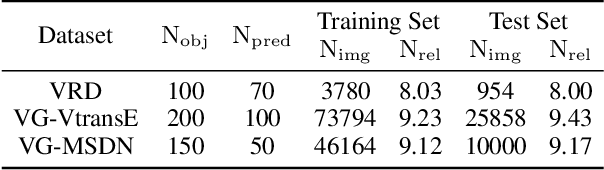
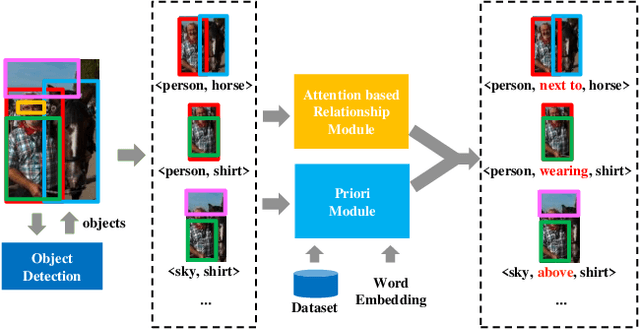
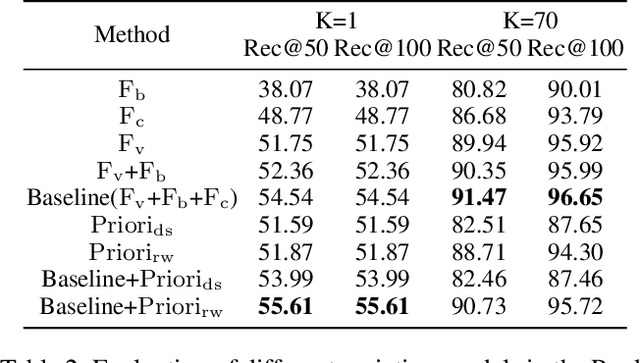
Visual relationship detection aims to locate objects in images and recognize the relationships between objects. Traditional methods treat all observed relationships in an image equally, which causes a relatively poor performance in the detection tasks on complex images with abundant visual objects and various relationships. To address this problem, we propose an attention based model, namely AVR, to achieve salient visual relationships based on both local and global context of the relationships. Specifically, AVR recognizes relationships and measures the attention on the relationships in the local context of an input image by fusing the visual features, semantic and spatial information of the relationships. AVR then applies the attention to assign important relationships with larger salient weights for effective information filtering. Furthermore, AVR is integrated with the priori knowledge in the global context of image datasets to improve the precision of relationship prediction, where the context is modeled as a heterogeneous graph to measure the priori probability of relationships based on the random walk algorithm. Comprehensive experiments are conducted to demonstrate the effectiveness of AVR in several real-world image datasets, and the results show that AVR outperforms state-of-the-art visual relationship detection methods significantly by up to $87.5\%$ in terms of recall.
Learning Shared Semantic Space with Correlation Alignment for Cross-modal Event Retrieval
Jan 15, 2019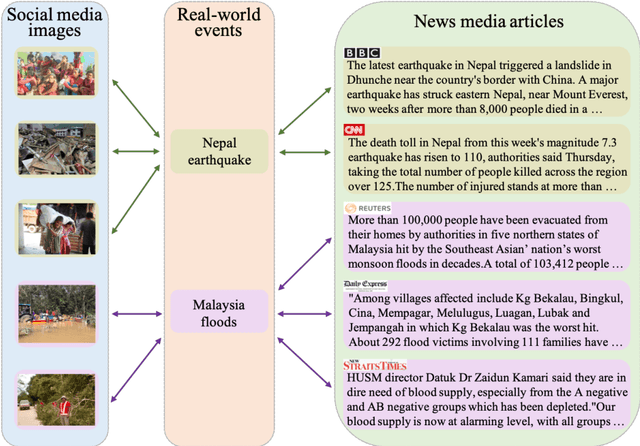

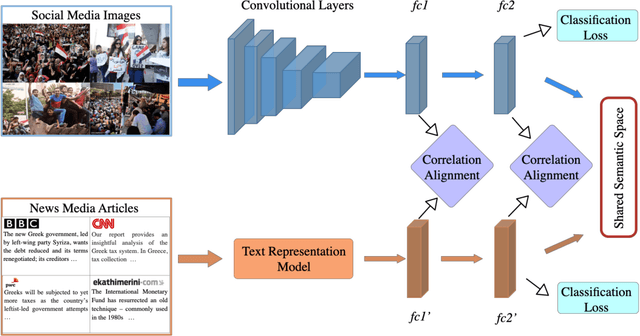
In this paper, we propose to learn shared semantic space with correlation alignment (${S}^{3}CA$) for multimodal data representations, which aligns nonlinear correlations of multimodal data distributions in deep neural networks designed for heterogeneous data. In the context of cross-modal (event) retrieval, we design a neural network with convolutional layers and fully-connected layers to extract features for images, including images on Flickr-like social media. Simultaneously, we exploit a fully-connected neural network to extract semantic features for texts, including news articles from news media. In particular, nonlinear correlations of layer activations in the two neural networks are aligned with correlation alignment during the joint training of the networks. Furthermore, we project the multimodal data into a shared semantic space for cross-modal (event) retrieval, where the distances between heterogeneous data samples can be measured directly. In addition, we contribute a Wiki-Flickr Event dataset, where the multimodal data samples are not describing each other in pairs like the existing paired datasets, but all of them are describing semantic events. Extensive experiments conducted on both paired and unpaired datasets manifest the effectiveness of ${S}^{3}CA$, outperforming the state-of-the-art methods.
Cross-dataset Person Re-Identification Using Similarity Preserved Generative Adversarial Networks
Jun 21, 2018

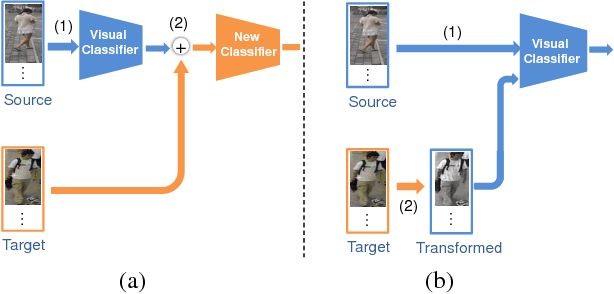
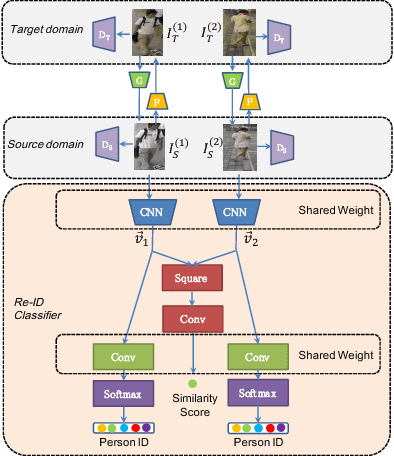
Person re-identification (Re-ID) aims to match the image frames which contain the same person in the surveillance videos. Most of the Re-ID algorithms conduct supervised training in some small labeled datasets, so directly deploying these trained models to the real-world large camera networks may lead to a poor performance due to underfitting. The significant difference between the source training dataset and the target testing dataset makes it challenging to incrementally optimize the model. To address this challenge, we propose a novel solution by transforming the unlabeled images in the target domain to fit the original classifier by using our proposed similarity preserved generative adversarial networks model, SimPGAN. Specifically, SimPGAN adopts the generative adversarial networks with the cycle consistency constraint to transform the unlabeled images in the target domain to the style of the source domain. Meanwhile, SimPGAN uses the similarity consistency loss, which is measured by a siamese deep convolutional neural network, to preserve the similarity of the transformed images of the same person. Comprehensive experiments based on multiple real surveillance datasets are conducted, and the results show that our algorithm is better than the state-of-the-art cross-dataset unsupervised person Re-ID algorithms.
Unsupervised Cross-dataset Person Re-identification by Transfer Learning of Spatial-Temporal Patterns
Mar 20, 2018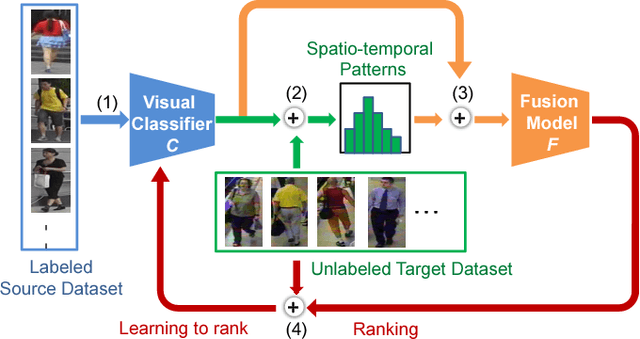
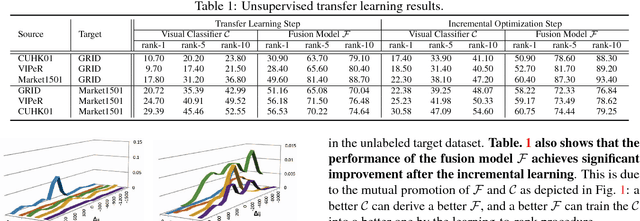
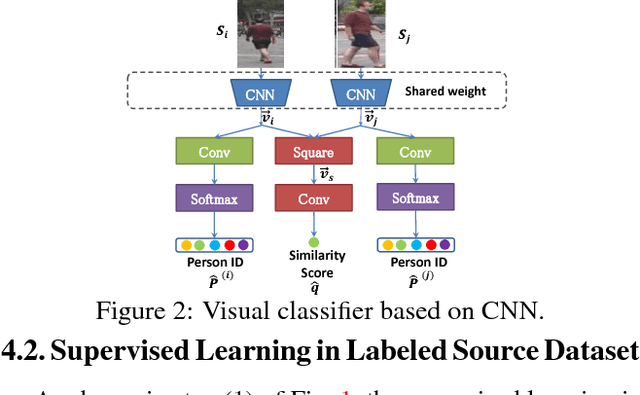
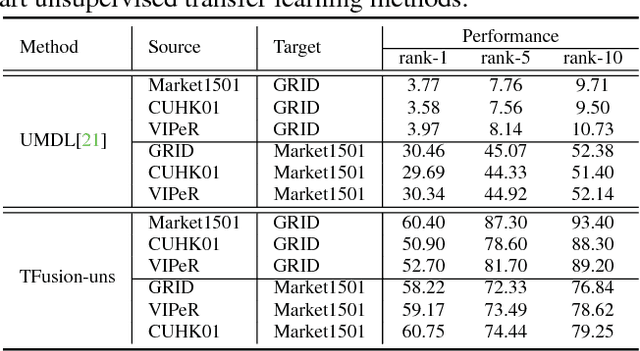
Most of the proposed person re-identification algorithms conduct supervised training and testing on single labeled datasets with small size, so directly deploying these trained models to a large-scale real-world camera network may lead to poor performance due to underfitting. It is challenging to incrementally optimize the models by using the abundant unlabeled data collected from the target domain. To address this challenge, we propose an unsupervised incremental learning algorithm, TFusion, which is aided by the transfer learning of the pedestrians' spatio-temporal patterns in the target domain. Specifically, the algorithm firstly transfers the visual classifier trained from small labeled source dataset to the unlabeled target dataset so as to learn the pedestrians' spatial-temporal patterns. Secondly, a Bayesian fusion model is proposed to combine the learned spatio-temporal patterns with visual features to achieve a significantly improved classifier. Finally, we propose a learning-to-rank based mutual promotion procedure to incrementally optimize the classifiers based on the unlabeled data in the target domain. Comprehensive experiments based on multiple real surveillance datasets are conducted, and the results show that our algorithm gains significant improvement compared with the state-of-art cross-dataset unsupervised person re-identification algorithms.