 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Large-scale Generative Ranking
May 08, 2025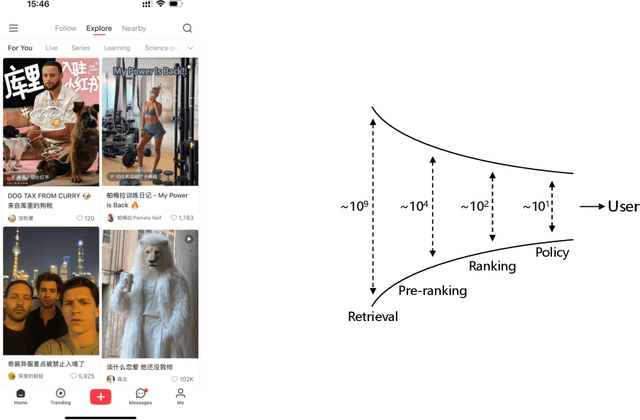
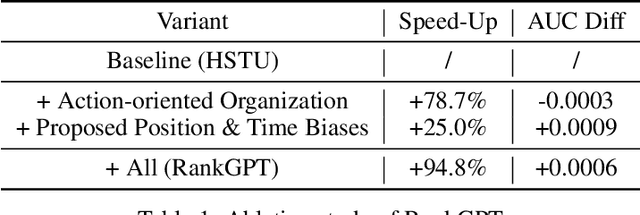
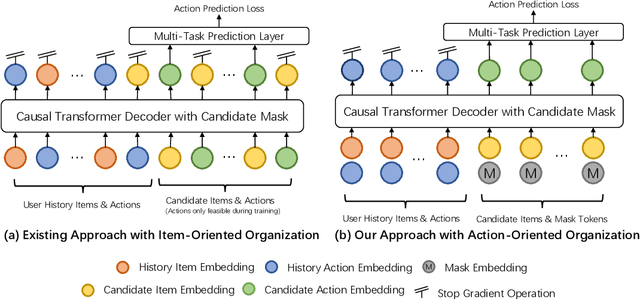

Generative recommendation has recently emerged as a promising paradigm in information retrieval. However, generative ranking systems are still understudied, particularly with respect to their effectiveness and feasibility in large-scale industrial settings. This paper investigates this topic at the ranking stage of Xiaohongshu's Explore Feed, a recommender system that serves hundreds of millions of users. Specifically, we first examine how generative ranking outperforms current industrial recommenders. Through theoretical and empirical analyses, we find that the primary improvement in effectiveness stems from the generative architecture, rather than the training paradigm. To facilitate efficient deployment of generative ranking, we introduce GenRank, a novel generative architecture for ranking. We validate the effectiveness and efficiency of our solution through online A/B experiments. The results show that GenRank achieves significant improvements in user satisfaction with nearly equivalent computational resources compared to the existing production system.
ThinTact:Thin Vision-Based Tactile Sensor by Lensless Imaging
Jan 16, 2025

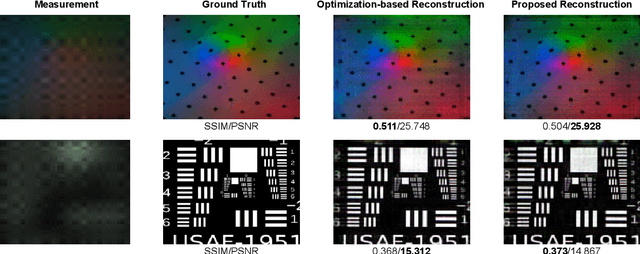
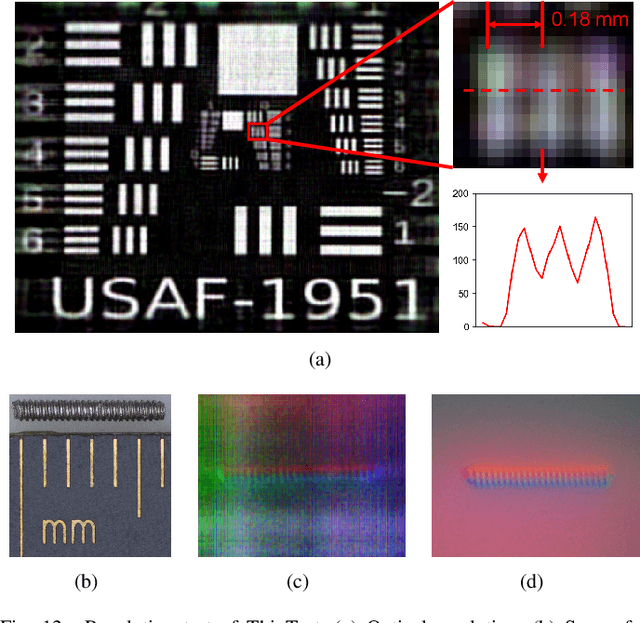
Vision-based tactile sensors have drawn increasing interest in the robotics community. However, traditional lens-based designs impose minimum thickness constraints on these sensors, limiting their applicability in space-restricted settings. In this paper, we propose ThinTact, a novel lensless vision-based tactile sensor with a sensing field of over 200 mm2 and a thickness of less than 10 mm.ThinTact utilizes the mask-based lensless imaging technique to map the contact information to CMOS signals. To ensure real-time tactile sensing, we propose a real-time lensless reconstruction algorithm that leverages a frequency-spatial-domain joint filter based on discrete cosine transform (DCT). This algorithm achieves computation significantly faster than existing optimization-based methods. Additionally, to improve the sensing quality, we develop a mask optimization method based on the generic algorithm and the corresponding system matrix calibration algorithm.We evaluate the performance of our proposed lensless reconstruction and tactile sensing through qualitative and quantitative experiments. Furthermore, we demonstrate ThinTact's practical applicability in diverse applications, including texture recognition and contact-rich object manipulation. The paper will appear in the IEEE Transactions on Robotics: https://ieeexplore.ieee.org/document/10842357. Video: https://youtu.be/YrOO9BDMAHo
Optimizing Personalized Federated Learning through Adaptive Layer-Wise Learning
Dec 10, 2024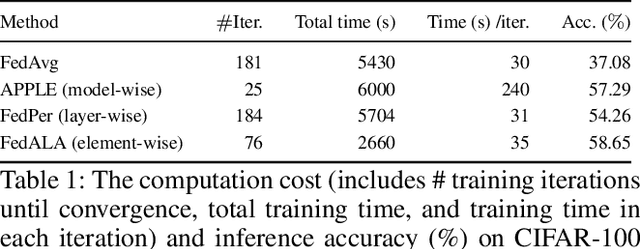
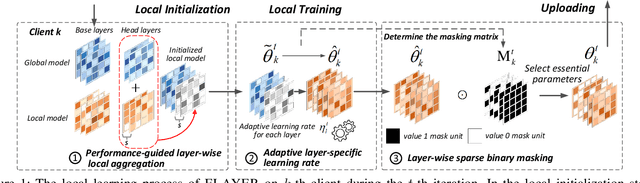
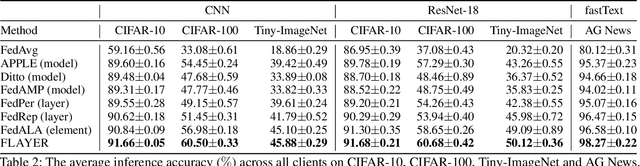
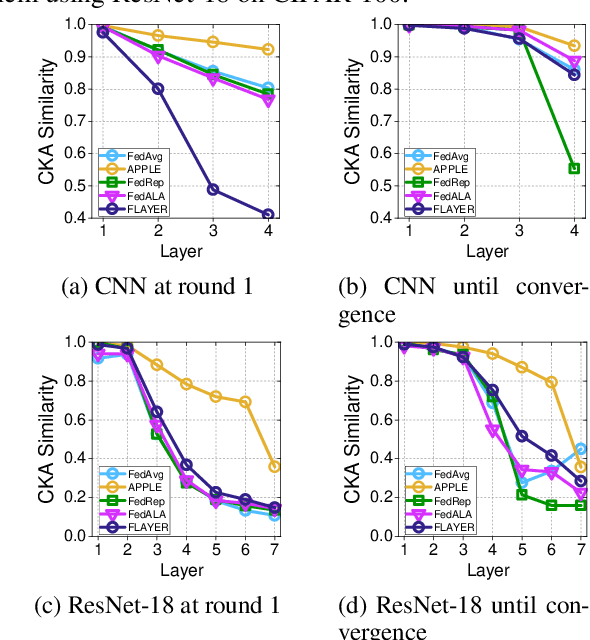
Real-life deployment of federated Learning (FL) often faces non-IID data, which leads to poor accuracy and slow convergence. Personalized FL (pFL) tackles these issues by tailoring local models to individual data sources and using weighted aggregation methods for client-specific learning. However, existing pFL methods often fail to provide each local model with global knowledge on demand while maintaining low computational overhead. Additionally, local models tend to over-personalize their data during the training process, potentially dropping previously acquired global information. We propose FLAYER, a novel layer-wise learning method for pFL that optimizes local model personalization performance. FLAYER considers the different roles and learning abilities of neural network layers of individual local models. It incorporates global information for each local model as needed to initialize the local model cost-effectively. It then dynamically adjusts learning rates for each layer during local training, optimizing the personalized learning process for each local model while preserving global knowledge. Additionally, to enhance global representation in pFL, FLAYER selectively uploads parameters for global aggregation in a layer-wise manner. We evaluate FLAYER on four representative datasets in computer vision and natural language processing domains. Compared to six state-of-the-art pFL methods, FLAYER improves the inference accuracy, on average, by 5.42% (up to 14.29%).
DexSim2Real$^{2}$: Building Explicit World Model for Precise Articulated Object Dexterous Manipulation
Sep 13, 2024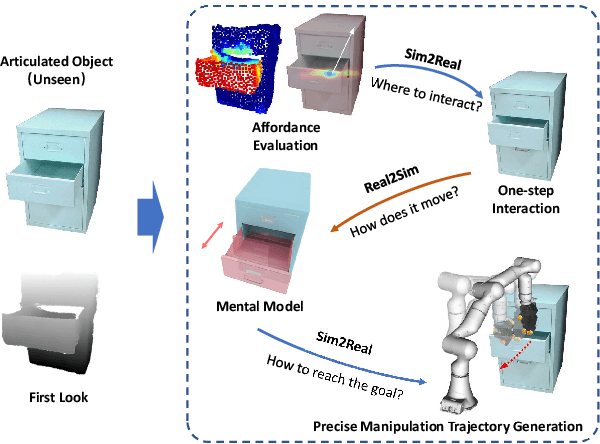

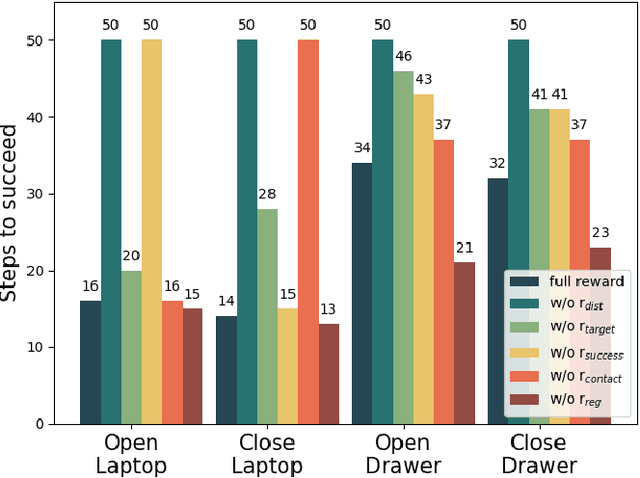
Articulated object manipulation is ubiquitous in daily life. In this paper, we present DexSim2Real$^{2}$, a novel robot learning framework for goal-conditioned articulated object manipulation using both two-finger grippers and multi-finger dexterous hands. The key of our framework is constructing an explicit world model of unseen articulated objects through active one-step interactions. This explicit world model enables sampling-based model predictive control to plan trajectories achieving different manipulation goals without needing human demonstrations or reinforcement learning. It first predicts an interaction motion using an affordance estimation network trained on self-supervised interaction data or videos of human manipulation from the internet. After executing this interaction on the real robot, the framework constructs a digital twin of the articulated object in simulation based on the two point clouds before and after the interaction. For dexterous multi-finger manipulation, we propose to utilize eigengrasp to reduce the high-dimensional action space, enabling more efficient trajectory searching. Extensive experiments validate the framework's effectiveness for precise articulated object manipulation in both simulation and the real world using a two-finger gripper and a 16-DoF dexterous hand. The robust generalizability of the explicit world model also enables advanced manipulation strategies, such as manipulating with different tools.
TransTouch: Learning Transparent Objects Depth Sensing Through Sparse Touches
Sep 18, 2023Transparent objects are common in daily life. However, depth sensing for transparent objects remains a challenging problem. While learning-based methods can leverage shape priors to improve the sensing quality, the labor-intensive data collection in the real world and the sim-to-real domain gap restrict these methods' scalability. In this paper, we propose a method to finetune a stereo network with sparse depth labels automatically collected using a probing system with tactile feedback. We present a novel utility function to evaluate the benefit of touches. By approximating and optimizing the utility function, we can optimize the probing locations given a fixed touching budget to better improve the network's performance on real objects. We further combine tactile depth supervision with a confidence-based regularization to prevent over-fitting during finetuning. To evaluate the effectiveness of our method, we construct a real-world dataset including both diffuse and transparent objects. Experimental results on this dataset show that our method can significantly improve real-world depth sensing accuracy, especially for transparent objects.
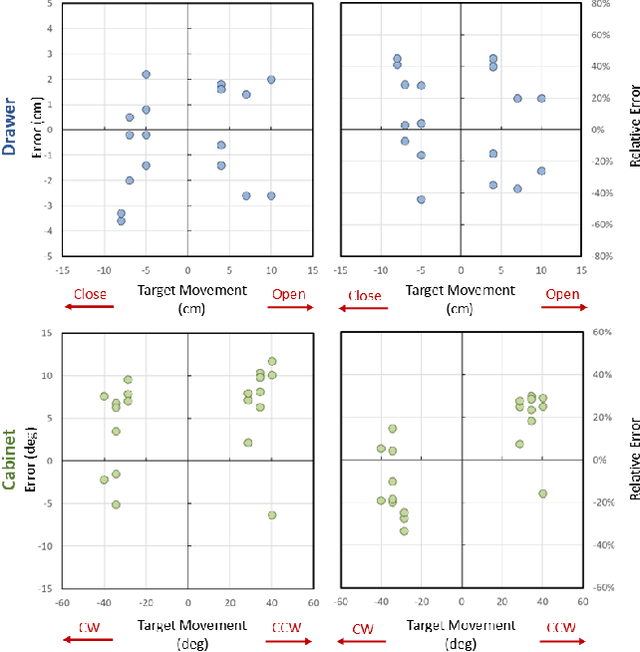
Sim2Real$^2$: Actively Building Explicit Physics Model for Precise Articulated Object Manipulation
Feb 21, 2023Accurately manipulating articulated objects is a challenging yet important task for real robot applications. In this paper, we present a novel framework called Sim2Real$^2$ to enable the robot to manipulate an unseen articulated object to the desired state precisely in the real world with no human demonstrations. We leverage recent advances in physics simulation and learning-based perception to build the interactive explicit physics model of the object and use it to plan a long-horizon manipulation trajectory to accomplish the task. However, the interactive model cannot be correctly estimated from a static observation. Therefore, we learn to predict the object affordance from a single-frame point cloud, control the robot to actively interact with the object with a one-step action, and capture another point cloud. Further, the physics model is constructed from the two point clouds. Experimental results show that our framework achieves about 70% manipulations with <30% relative error for common articulated objects, and 30% manipulations for difficult objects. Our proposed framework also enables advanced manipulation strategies, such as manipulating with different tools. Code and videos are available on our project webpage: https://ttimelord.github.io/Sim2Real2-site/
Enhancing Generalizable 6D Pose Tracking of an In-Hand Object with Tactile Sensing
Oct 08, 2022
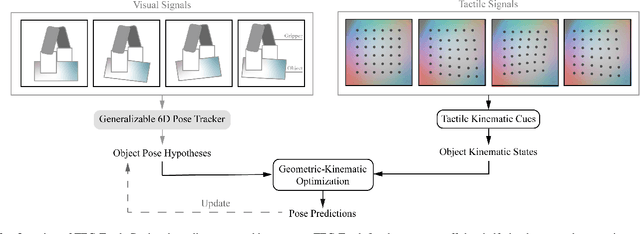


While holding and manipulating an object, humans track the object states through vision and touch so as to achieve complex tasks. However, nowadays the majority of robot research perceives object states just from visual signals, hugely limiting the robotic manipulation abilities. This work presents a tactile-enhanced generalizable 6D pose tracking design named TEG-Track to track previously unseen in-hand objects. TEG-Track extracts tactile kinematic cues of an in-hand object from consecutive tactile sensing signals. Such cues are incorporated into a geometric-kinematic optimization scheme to enhance existing generalizable visual trackers. To test our method in real scenarios and enable future studies on generalizable visual-tactile tracking, we collect a real visual-tactile in-hand object pose tracking dataset. Experiments show that TEG-Track significantly improves state-of-the-art generalizable 6D pose trackers in both synthetic and real cases.
Unsupervised Cross-dataset Person Re-identification by Transfer Learning of Spatial-Temporal Patterns
Mar 20, 2018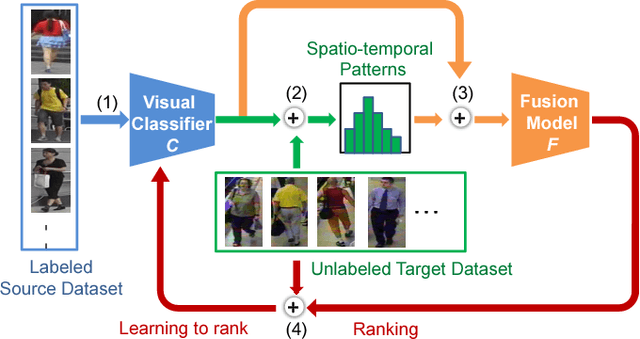
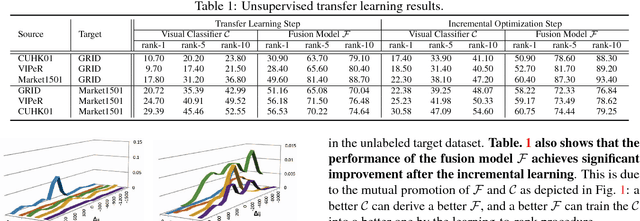
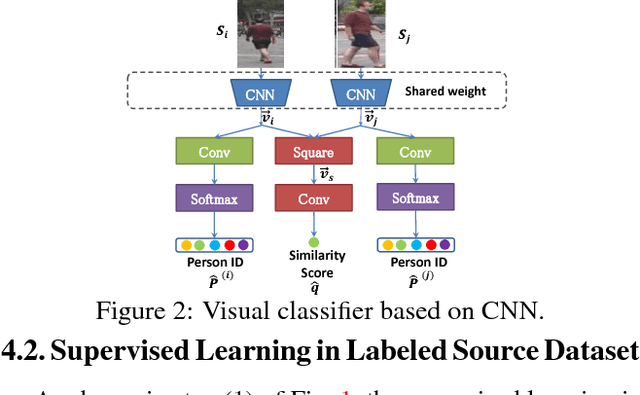
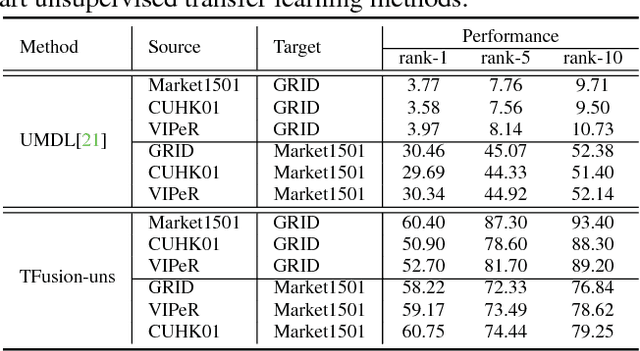
Most of the proposed person re-identification algorithms conduct supervised training and testing on single labeled datasets with small size, so directly deploying these trained models to a large-scale real-world camera network may lead to poor performance due to underfitting. It is challenging to incrementally optimize the models by using the abundant unlabeled data collected from the target domain. To address this challenge, we propose an unsupervised incremental learning algorithm, TFusion, which is aided by the transfer learning of the pedestrians' spatio-temporal patterns in the target domain. Specifically, the algorithm firstly transfers the visual classifier trained from small labeled source dataset to the unlabeled target dataset so as to learn the pedestrians' spatial-temporal patterns. Secondly, a Bayesian fusion model is proposed to combine the learned spatio-temporal patterns with visual features to achieve a significantly improved classifier. Finally, we propose a learning-to-rank based mutual promotion procedure to incrementally optimize the classifiers based on the unlabeled data in the target domain. Comprehensive experiments based on multiple real surveillance datasets are conducted, and the results show that our algorithm gains significant improvement compared with the state-of-art cross-dataset unsupervised person re-identification algorithms.