 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoMMI: Learning Whole-Body Mobile Manipulation from Human Demonstrations
Mar 03, 2026We present Whole-Body Mobile Manipulation Interface (HoMMI), a data collection and policy learning framework that learns whole-body mobile manipulation directly from robot-free human demonstrations. We augment UMI interfaces with egocentric sensing to capture the global context required for mobile manipulation, enabling portable, robot-free, and scalable data collection. However, naively incorporating egocentric sensing introduces a larger human-to-robot embodiment gap in both observation and action spaces, making policy transfer difficult. We explicitly bridge this gap with a cross-embodiment hand-eye policy design, including an embodiment agnostic visual representation; a relaxed head action representation; and a whole-body controller that realizes hand-eye trajectories through coordinated whole-body motion under robot-specific physical constraints. Together, these enable long-horizon mobile manipulation tasks requiring bimanual and whole-body coordination, navigation, and active perception. Results are best viewed on: https://hommi-robot.github.io
In-the-Wild Compliant Manipulation with UMI-FT
Jan 15, 2026Many manipulation tasks require careful force modulation. With insufficient force the task may fail, while excessive force could cause damage. The high cost, bulky size and fragility of commercial force/torque (F/T) sensors have limited large-scale, force-aware policy learning. We introduce UMI-FT, a handheld data-collection platform that mounts compact, six-axis force/torque sensors on each finger, enabling finger-level wrench measurements alongside RGB, depth, and pose. Using the multimodal data collected from this device, we train an adaptive compliance policy that predicts position targets, grasp force, and stiffness for execution on standard compliance controllers. In evaluations on three contact-rich, force-sensitive tasks (whiteboard wiping, skewering zucchini, and lightbulb insertion), UMI-FT enables policies that reliably regulate external contact forces and internal grasp forces, outperforming baselines that lack compliance or force sensing. UMI-FT offers a scalable path to learning compliant manipulation from in-the-wild demonstrations. We open-source the hardware and software to facilitate broader adoption at:https://umi-ft.github.io/.
Vision in Action: Learning Active Perception from Human Demonstrations
Jun 18, 2025We present Vision in Action (ViA), an active perception system for bimanual robot manipulation. ViA learns task-relevant active perceptual strategies (e.g., searching, tracking, and focusing) directly from human demonstrations. On the hardware side, ViA employs a simple yet effective 6-DoF robotic neck to enable flexible, human-like head movements. To capture human active perception strategies, we design a VR-based teleoperation interface that creates a shared observation space between the robot and the human operator. To mitigate VR motion sickness caused by latency in the robot's physical movements, the interface uses an intermediate 3D scene representation, enabling real-time view rendering on the operator side while asynchronously updating the scene with the robot's latest observations. Together, these design elements enable the learning of robust visuomotor policies for three complex, multi-stage bimanual manipulation tasks involving visual occlusions, significantly outperforming baseline systems.
RoboPanoptes: The All-seeing Robot with Whole-body Dexterity
Jan 09, 2025We present RoboPanoptes, a capable yet practical robot system that achieves whole-body dexterity through whole-body vision. Its whole-body dexterity allows the robot to utilize its entire body surface for manipulation, such as leveraging multiple contact points or navigating constrained spaces. Meanwhile, whole-body vision uses a camera system distributed over the robot's surface to provide comprehensive, multi-perspective visual feedback of its own and the environment's state. At its core, RoboPanoptes uses a whole-body visuomotor policy that learns complex manipulation skills directly from human demonstrations, efficiently aggregating information from the distributed cameras while maintaining resilience to sensor failures. Together, these design aspects unlock new capabilities and tasks, allowing RoboPanoptes to unbox in narrow spaces, sweep multiple or oversized objects, and succeed in multi-step stowing in cluttered environments, outperforming baselines in adaptability and efficiency. Results are best viewed on https://robopanoptes.github.io.
MAiDE-up: Multilingual Deception Detection of GPT-generated Hotel Reviews
Apr 19, 2024Deceptive reviews are becoming increasingly common, especially given the increase in performance and the prevalence of LLMs. While work to date has addressed the development of models to differentiate between truthful and deceptive human reviews, much less is known about the distinction between real reviews and AI-authored fake reviews. Moreover, most of the research so far has focused primarily on English, with very little work dedicated to other languages. In this paper, we compile and make publicly available the MAiDE-up dataset, consisting of 10,000 real and 10,000 AI-generated fake hotel reviews, balanced across ten languages. Using this dataset, we conduct extensive linguistic analyses to (1) compare the AI fake hotel reviews to real hotel reviews, and (2) identify the factors that influence the deception detection model performance. We explore the effectiveness of several models for deception detection in hotel reviews across three main dimensions: sentiment, location, and language. We find that these dimensions influence how well we can detect AI-generated fake reviews.
Dynamics-Guided Diffusion Model for Robot Manipulator Design
Feb 23, 2024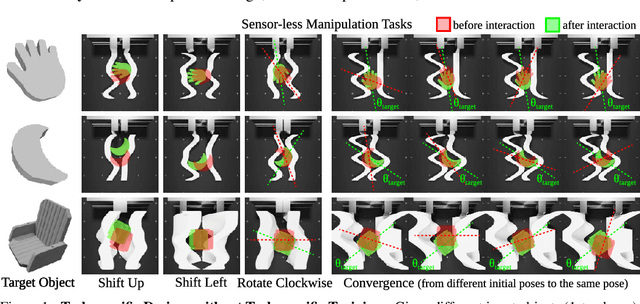
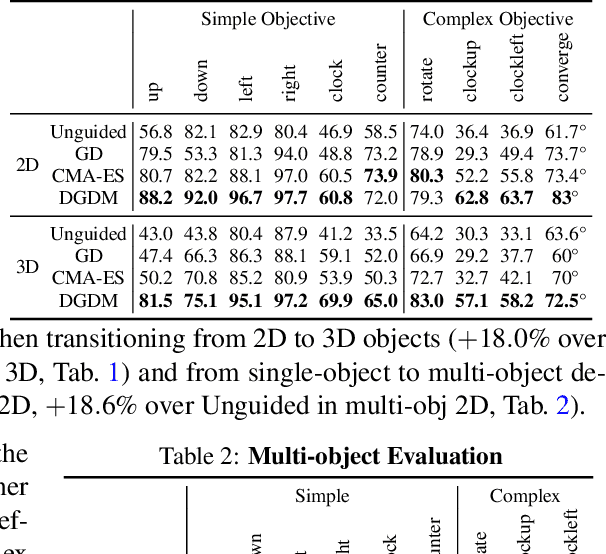
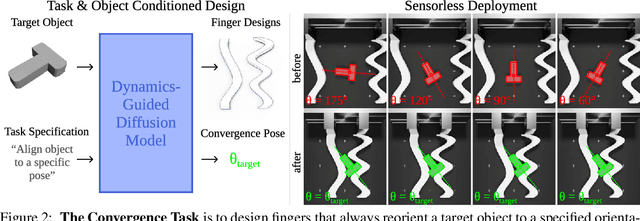

We present Dynamics-Guided Diffusion Model, a data-driven framework for generating manipulator geometry designs for a given manipulation task. Instead of training different design models for each task, our approach employs a learned dynamics network shared across tasks. For a new manipulation task, we first decompose it into a collection of individual motion targets which we call target interaction profile, where each individual motion can be modeled by the shared dynamics network. The design objective constructed from the target and predicted interaction profiles provides a gradient to guide the refinement of finger geometry for the task. This refinement process is executed as a classifier-guided diffusion process, where the design objective acts as the classifier guidance. We evaluate our framework on various manipulation tasks, under the sensor-less setting using only an open-loop parallel jaw motion. Our generated designs outperform optimization-based and unguided diffusion baselines relatively by 31.5% and 45.3% on average manipulation success rate. With the ability to generate a design within 0.8 seconds, our framework could facilitate rapid design iteration and enhance the adoption of data-driven approaches for robotic mechanism design.
JacobiNeRF: NeRF Shaping with Mutual Information Gradients
Apr 01, 2023We propose a method that trains a neural radiance field (NeRF) to encode not only the appearance of the scene but also semantic correlations between scene points, regions, or entities -- aiming to capture their mutual co-variation patterns. In contrast to the traditional first-order photometric reconstruction objective, our method explicitly regularizes the learning dynamics to align the Jacobians of highly-correlated entities, which proves to maximize the mutual information between them under random scene perturbations. By paying attention to this second-order information, we can shape a NeRF to express semantically meaningful synergies when the network weights are changed by a delta along the gradient of a single entity, region, or even a point. To demonstrate the merit of this mutual information modeling, we leverage the coordinated behavior of scene entities that emerges from our shaping to perform label propagation for semantic and instance segmentation. Our experiments show that a JacobiNeRF is more efficient in propagating annotations among 2D pixels and 3D points compared to NeRFs without mutual information shaping, especially in extremely sparse label regimes -- thus reducing annotation burden. The same machinery can further be used for entity selection or scene modifications.
Enhancing Generalizable 6D Pose Tracking of an In-Hand Object with Tactile Sensing
Oct 08, 2022
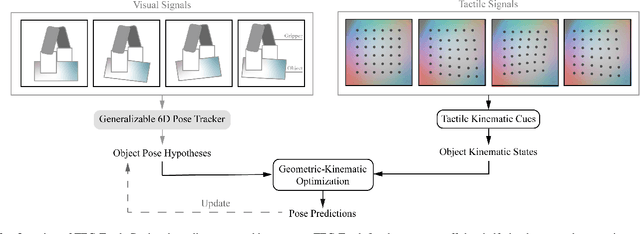


While holding and manipulating an object, humans track the object states through vision and touch so as to achieve complex tasks. However, nowadays the majority of robot research perceives object states just from visual signals, hugely limiting the robotic manipulation abilities. This work presents a tactile-enhanced generalizable 6D pose tracking design named TEG-Track to track previously unseen in-hand objects. TEG-Track extracts tactile kinematic cues of an in-hand object from consecutive tactile sensing signals. Such cues are incorporated into a geometric-kinematic optimization scheme to enhance existing generalizable visual trackers. To test our method in real scenarios and enable future studies on generalizable visual-tactile tracking, we collect a real visual-tactile in-hand object pose tracking dataset. Experiments show that TEG-Track significantly improves state-of-the-art generalizable 6D pose trackers in both synthetic and real cases.
AutoGPart: Intermediate Supervision Search for Generalizable 3D Part Segmentation
Mar 29, 2022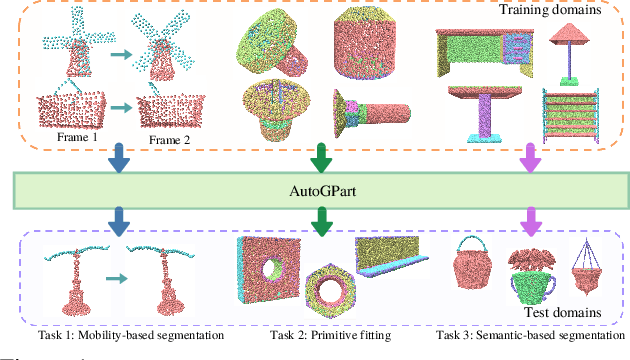
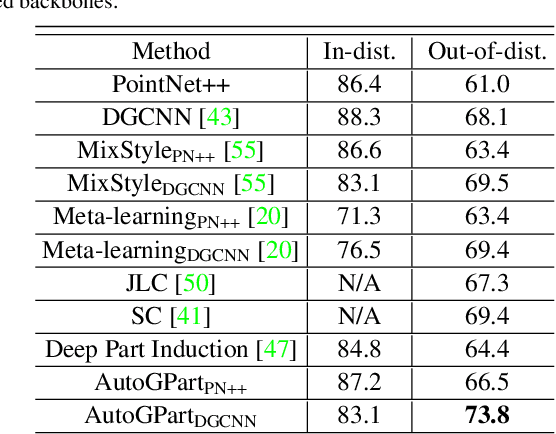
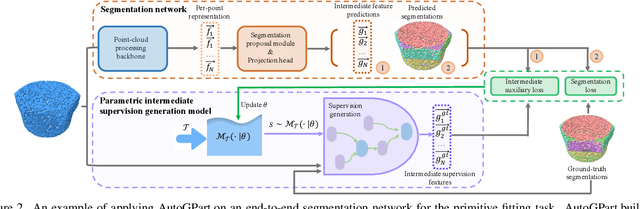

Training a generalizable 3D part segmentation network is quite challenging but of great importance in real-world applications. To tackle this problem, some works design task-specific solutions by translating human understanding of the task to machine's learning process, which faces the risk of missing the optimal strategy since machines do not necessarily understand in the exact human way. Others try to use conventional task-agnostic approaches designed for domain generalization problems with no task prior knowledge considered. To solve the above issues, we propose AutoGPart, a generic method enabling training generalizable 3D part segmentation networks with the task prior considered. AutoGPart builds a supervision space with geometric prior knowledge encoded, and lets the machine to search for the optimal supervisions from the space for a specific segmentation task automatically. Extensive experiments on three generalizable 3D part segmentation tasks are conducted to demonstrate the effectiveness and versatility of AutoGPart. We demonstrate that the performance of segmentation networks using simple backbones can be significantly improved when trained with supervisions searched by our method.