 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTakeAD: Preference-based Post-optimization for End-to-end Autonomous Driving with Expert Takeover Data
Dec 22, 2025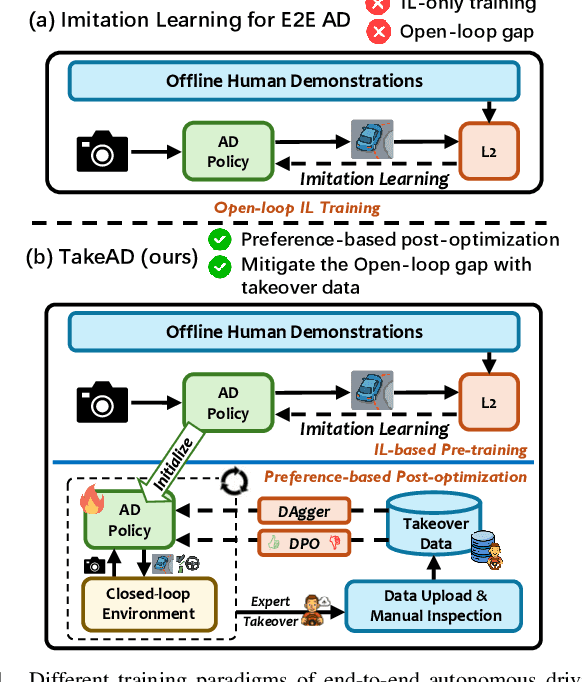
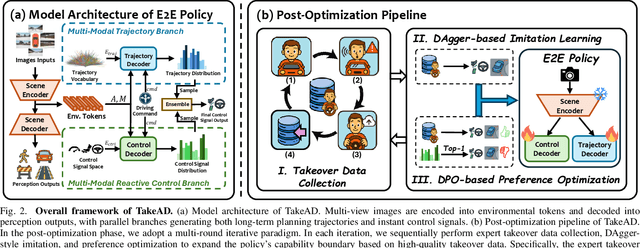
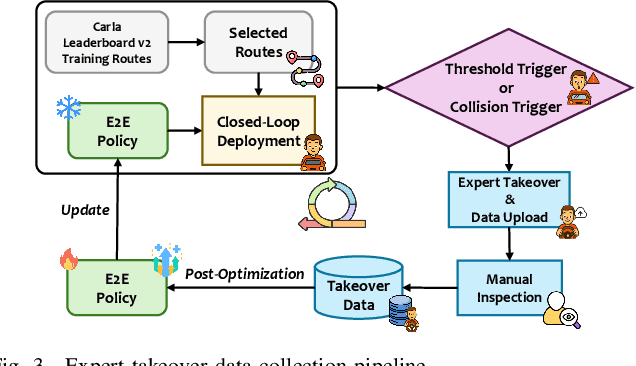
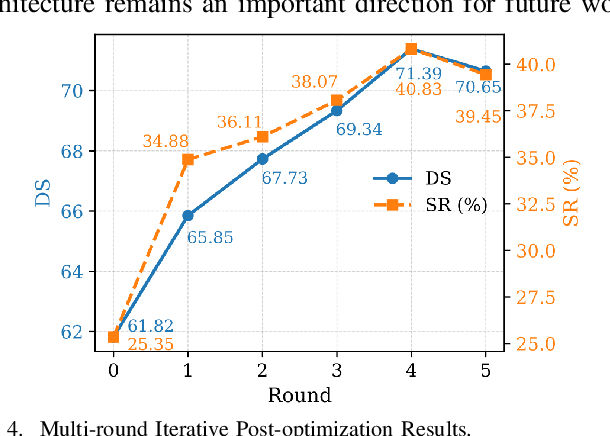
Existing end-to-end autonomous driving methods typically rely on imitation learning (IL) but face a key challenge: the misalignment between open-loop training and closed-loop deployment. This misalignment often triggers driver-initiated takeovers and system disengagements during closed-loop execution. How to leverage those expert takeover data from disengagement scenarios and effectively expand the IL policy's capability presents a valuable yet unexplored challenge. In this paper, we propose TakeAD, a novel preference-based post-optimization framework that fine-tunes the pre-trained IL policy with this disengagement data to enhance the closed-loop driving performance. First, we design an efficient expert takeover data collection pipeline inspired by human takeover mechanisms in real-world autonomous driving systems. Then, this post optimization framework integrates iterative Dataset Aggregation (DAgger) for imitation learning with Direct Preference Optimization (DPO) for preference alignment. The DAgger stage equips the policy with fundamental capabilities to handle disengagement states through direct imitation of expert interventions. Subsequently, the DPO stage refines the policy's behavior to better align with expert preferences in disengagement scenarios. Through multiple iterations, the policy progressively learns recovery strategies for disengagement states, thereby mitigating the open-loop gap. Experiments on the closed-loop Bench2Drive benchmark demonstrate our method's effectiveness compared with pure IL methods, with comprehensive ablations confirming the contribution of each component.
ReasonPlan: Unified Scene Prediction and Decision Reasoning for Closed-loop Autonomous Driving
May 26, 2025Due to the powerful vision-language reasoning and generalization abilities, multimodal large language models (MLLMs) have garnered significant attention in the field of end-to-end (E2E) autonomous driving. However, their application to closed-loop systems remains underexplored, and current MLLM-based methods have not shown clear superiority to mainstream E2E imitation learning approaches. In this work, we propose ReasonPlan, a novel MLLM fine-tuning framework designed for closed-loop driving through holistic reasoning with a self-supervised Next Scene Prediction task and supervised Decision Chain-of-Thought process. This dual mechanism encourages the model to align visual representations with actionable driving context, while promoting interpretable and causally grounded decision making. We curate a planning-oriented decision reasoning dataset, namely PDR, comprising 210k diverse and high-quality samples. Our method outperforms the mainstream E2E imitation learning method by a large margin of 19% L2 and 16.1 driving score on Bench2Drive benchmark. Furthermore, ReasonPlan demonstrates strong zero-shot generalization on unseen DOS benchmark, highlighting its adaptability in handling zero-shot corner cases. Code and dataset will be found in https://github.com/Liuxueyi/ReasonPlan.
DexTrack: Towards Generalizable Neural Tracking Control for Dexterous Manipulation from Human References
Feb 13, 2025We address the challenge of developing a generalizable neural tracking controller for dexterous manipulation from human references. This controller aims to manage a dexterous robot hand to manipulate diverse objects for various purposes defined by kinematic human-object interactions. Developing such a controller is complicated by the intricate contact dynamics of dexterous manipulation and the need for adaptivity, generalizability, and robustness. Current reinforcement learning and trajectory optimization methods often fall short due to their dependence on task-specific rewards or precise system models. We introduce an approach that curates large-scale successful robot tracking demonstrations, comprising pairs of human references and robot actions, to train a neural controller. Utilizing a data flywheel, we iteratively enhance the controller's performance, as well as the number and quality of successful tracking demonstrations. We exploit available tracking demonstrations and carefully integrate reinforcement learning and imitation learning to boost the controller's performance in dynamic environments. At the same time, to obtain high-quality tracking demonstrations, we individually optimize per-trajectory tracking by leveraging the learned tracking controller in a homotopy optimization method. The homotopy optimization, mimicking chain-of-thought, aids in solving challenging trajectory tracking problems to increase demonstration diversity. We showcase our success by training a generalizable neural controller and evaluating it in both simulation and real world. Our method achieves over a 10% improvement in success rates compared to leading baselines. The project website with animated results is available at https://meowuu7.github.io/DexTrack/.
MobileH2R: Learning Generalizable Human to Mobile Robot Handover Exclusively from Scalable and Diverse Synthetic Data
Jan 08, 2025



This paper introduces MobileH2R, a framework for learning generalizable vision-based human-to-mobile-robot (H2MR) handover skills. Unlike traditional fixed-base handovers, this task requires a mobile robot to reliably receive objects in a large workspace enabled by its mobility. Our key insight is that generalizable handover skills can be developed in simulators using high-quality synthetic data, without the need for real-world demonstrations. To achieve this, we propose a scalable pipeline for generating diverse synthetic full-body human motion data, an automated method for creating safe and imitation-friendly demonstrations, and an efficient 4D imitation learning method for distilling large-scale demonstrations into closed-loop policies with base-arm coordination. Experimental evaluations in both simulators and the real world show significant improvements (at least +15% success rate) over baseline methods in all cases. Experiments also validate that large-scale and diverse synthetic data greatly enhances robot learning, highlighting our scalable framework.
APS-LSTM: Exploiting Multi-Periodicity and Diverse Spatial Dependencies for Flood Forecasting
Dec 07, 2024Accurate flood prediction is crucial for disaster prevention and mitigation. Hydrological data exhibit highly nonlinear temporal patterns and encompass complex spatial relationships between rainfall and flow. Existing flood prediction models struggle to capture these intricate temporal features and spatial dependencies. This paper presents an adaptive periodic and spatial self-attention method based on LSTM (APS-LSTM) to address these challenges. The APS-LSTM learns temporal features from a multi-periodicity perspective and captures diverse spatial dependencies from different period divisions. The APS-LSTM consists of three main stages, (i) Multi-Period Division, that utilizes Fast Fourier Transform (FFT) to divide various periodic patterns; (ii) Spatio-Temporal Information Extraction, that performs periodic and spatial self-attention focusing on intra- and inter-periodic temporal patterns and spatial dependencies; (iii) Adaptive Aggregation, that relies on amplitude strength to aggregate the computational results from each periodic division. The abundant experiments on two real-world datasets demonstrate the superiority of APS-LSTM. The code is available: https://github.com/oopcmd/APS-LSTM.
DiffuTraj: A Stochastic Vessel Trajectory Prediction Approach via Guided Diffusion Process
Oct 12, 2024Maritime vessel maneuvers, characterized by their inherent complexity and indeterminacy, requires vessel trajectory prediction system capable of modeling the multi-modality nature of future motion states. Conventional stochastic trajectory prediction methods utilize latent variables to represent the multi-modality of vessel motion, however, tends to overlook the complexity and dynamics inherent in maritime behavior. In contrast, we explicitly simulate the transition of vessel motion from uncertainty towards a state of certainty, effectively handling future indeterminacy in dynamic scenes. In this paper, we present a novel framework (\textit{DiffuTraj}) to conceptualize the trajectory prediction task as a guided reverse process of motion pattern uncertainty diffusion, in which we progressively remove uncertainty from maritime regions to delineate the intended trajectory. Specifically, we encode the previous states of the target vessel, vessel-vessel interactions, and the environment context as guiding factors for trajectory generation. Subsequently, we devise a transformer-based conditional denoiser to capture spatio-temporal dependencies, enabling the generation of trajectories better aligned for particular maritime environment. Comprehensive experiments on vessel trajectory prediction benchmarks demonstrate the superiority of our method.
QuasiSim: Parameterized Quasi-Physical Simulators for Dexterous Manipulations Transfer
Apr 11, 2024We explore the dexterous manipulation transfer problem by designing simulators. The task wishes to transfer human manipulations to dexterous robot hand simulations and is inherently difficult due to its intricate, highly-constrained, and discontinuous dynamics and the need to control a dexterous hand with a DoF to accurately replicate human manipulations. Previous approaches that optimize in high-fidelity black-box simulators or a modified one with relaxed constraints only demonstrate limited capabilities or are restricted by insufficient simulation fidelity. We introduce parameterized quasi-physical simulators and a physics curriculum to overcome these limitations. The key ideas are 1) balancing between fidelity and optimizability of the simulation via a curriculum of parameterized simulators, and 2) solving the problem in each of the simulators from the curriculum, with properties ranging from high task optimizability to high fidelity. We successfully enable a dexterous hand to track complex and diverse manipulations in high-fidelity simulated environments, boosting the success rate by 11\%+ from the best-performed baseline. The project website is available at https://meowuu7.github.io/QuasiSim/.
GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion
Feb 22, 2024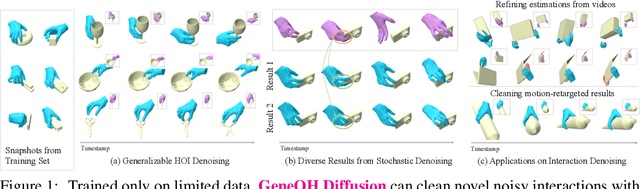
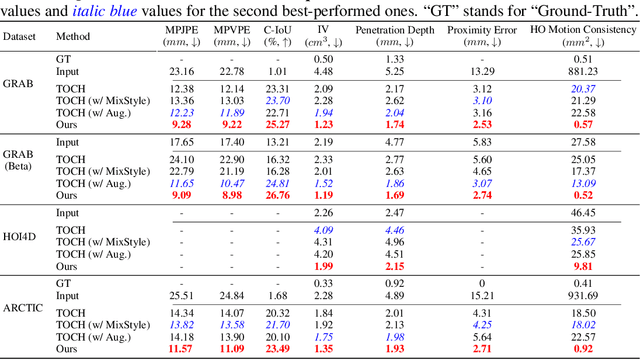
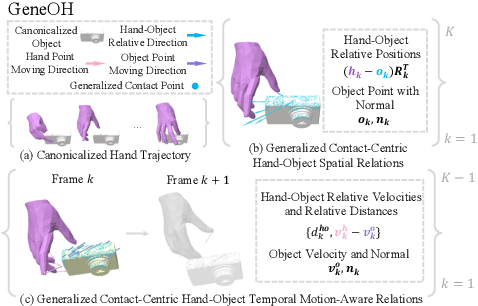

In this work, we tackle the challenging problem of denoising hand-object interactions (HOI). Given an erroneous interaction sequence, the objective is to refine the incorrect hand trajectory to remove interaction artifacts for a perceptually realistic sequence. This challenge involves intricate interaction noise, including unnatural hand poses and incorrect hand-object relations, alongside the necessity for robust generalization to new interactions and diverse noise patterns. We tackle those challenges through a novel approach, GeneOH Diffusion, incorporating two key designs: an innovative contact-centric HOI representation named GeneOH and a new domain-generalizable denoising scheme. The contact-centric representation GeneOH informatively parameterizes the HOI process, facilitating enhanced generalization across various HOI scenarios. The new denoising scheme consists of a canonical denoising model trained to project noisy data samples from a whitened noise space to a clean data manifold and a "denoising via diffusion" strategy which can handle input trajectories with various noise patterns by first diffusing them to align with the whitened noise space and cleaning via the canonical denoiser. Extensive experiments on four benchmarks with significant domain variations demonstrate the superior effectiveness of our method. GeneOH Diffusion also shows promise for various downstream applications. Project website: https://meowuu7.github.io/GeneOH-Diffusion/.
* Accepted to ICLR 2024. Project website: https://meowuu7.github.io/GeneOH-Diffusion/; Huggingface Demo: https://huggingface.co/spaces/xymeow7/gene-hoi-denoising; Code: https://github.com/Meowuu7/GeneOH-Diffusion
Aspect-oriented Opinion Alignment Network for Aspect-Based Sentiment Classification
Aug 22, 2023Aspect-based sentiment classification is a crucial problem in fine-grained sentiment analysis, which aims to predict the sentiment polarity of the given aspect according to its context. Previous works have made remarkable progress in leveraging attention mechanism to extract opinion words for different aspects. However, a persistent challenge is the effective management of semantic mismatches, which stem from attention mechanisms that fall short in adequately aligning opinions words with their corresponding aspect in multi-aspect sentences. To address this issue, we propose a novel Aspect-oriented Opinion Alignment Network (AOAN) to capture the contextual association between opinion words and the corresponding aspect. Specifically, we first introduce a neighboring span enhanced module which highlights various compositions of neighboring words and given aspects. In addition, we design a multi-perspective attention mechanism that align relevant opinion information with respect to the given aspect. Extensive experiments on three benchmark datasets demonstrate that our model achieves state-of-the-art results. The source code is available at https://github.com/AONE-NLP/ABSA-AOAN.
Few-Shot Physically-Aware Articulated Mesh Generation via Hierarchical Deformation
Aug 21, 2023We study the problem of few-shot physically-aware articulated mesh generation. By observing an articulated object dataset containing only a few examples, we wish to learn a model that can generate diverse meshes with high visual fidelity and physical validity. Previous mesh generative models either have difficulties in depicting a diverse data space from only a few examples or fail to ensure physical validity of their samples. Regarding the above challenges, we propose two key innovations, including 1) a hierarchical mesh deformation-based generative model based upon the divide-and-conquer philosophy to alleviate the few-shot challenge by borrowing transferrable deformation patterns from large scale rigid meshes and 2) a physics-aware deformation correction scheme to encourage physically plausible generations. We conduct extensive experiments on 6 articulated categories to demonstrate the superiority of our method in generating articulated meshes with better diversity, higher visual fidelity, and better physical validity over previous methods in the few-shot setting. Further, we validate solid contributions of our two innovations in the ablation study. Project page with code is available at https://meowuu7.github.io/few-arti-obj-gen.
* ICCV 2023. Project Page: https://meowuu7.github.io/few-arti-obj-gen