 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegative-Aware Diffusion Process for Temporal Knowledge Graph Extrapolation
Feb 09, 2026Temporal Knowledge Graph (TKG) reasoning seeks to predict future missing facts from historical evidence. While diffusion models (DM) have recently gained attention for their ability to capture complex predictive distributions, two gaps remain: (i) the generative path is conditioned only on positive evidence, overlooking informative negative context, and (ii) training objectives are dominated by cross-entropy ranking, which improves candidate ordering but provides little supervision over the calibration of the denoised embedding. To bridge this gap, we introduce Negative-Aware Diffusion model for TKG Extrapolation (NADEx). Specifically, NADEx encodes subject-centric histories of entities, relations and temporal intervals into sequential embeddings. NADEx perturbs the query object in the forward process and reconstructs it in reverse with a Transformer denoiser conditioned on the temporal-relational context. We further derive a cosine-alignment regularizer derived from batch-wise negative prototypes, which tightens the decision boundary against implausible candidates. Comprehensive experiments on four public TKG benchmarks demonstrate that NADEx delivers state-of-the-art performance.
Exploiting Inter-Session Information with Frequency-enhanced Dual-Path Networks for Sequential Recommendation
Nov 14, 2025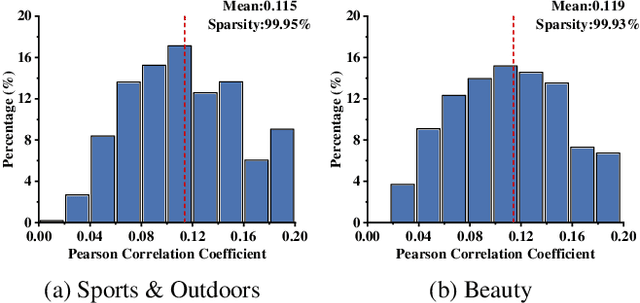
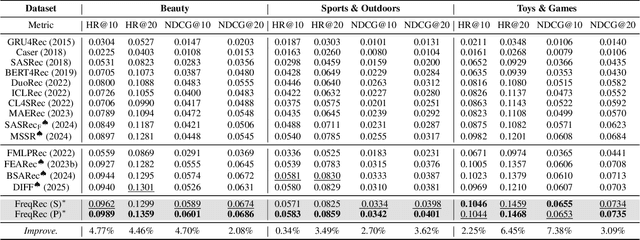
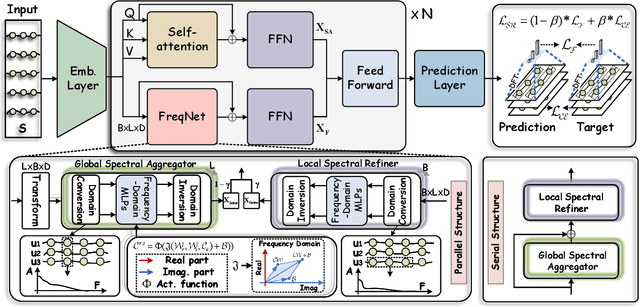
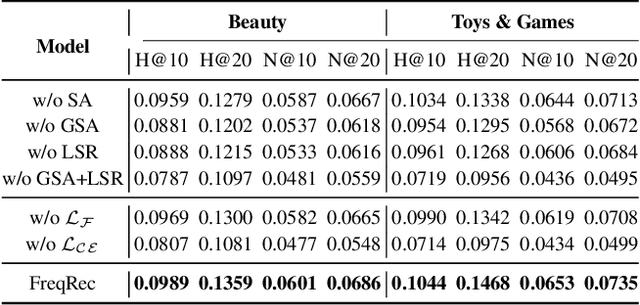
Sequential recommendation (SR) aims to predict a user's next item preference by modeling historical interaction sequences. Recent advances often integrate frequency-domain modules to compensate for self-attention's low-pass nature by restoring the high-frequency signals critical for personalized recommendations. Nevertheless, existing frequency-aware solutions process each session in isolation and optimize exclusively with time-domain objectives. Consequently, they overlook cross-session spectral dependencies and fail to enforce alignment between predicted and actual spectral signatures, leaving valuable frequency information under-exploited. To this end, we propose FreqRec, a Frequency-Enhanced Dual-Path Network for sequential Recommendation that jointly captures inter-session and intra-session behaviors via a learnable Frequency-domain Multi-layer Perceptrons. Moreover, FreqRec is optimized under a composite objective that combines cross entropy with a frequency-domain consistency loss, explicitly aligning predicted and true spectral signatures. Extensive experiments on three benchmarks show that FreqRec surpasses strong baselines and remains robust under data sparsity and noisy-log conditions.
Class Incremental Learning with Task-Specific Batch Normalization and Out-of-Distribution Detection
Nov 01, 2024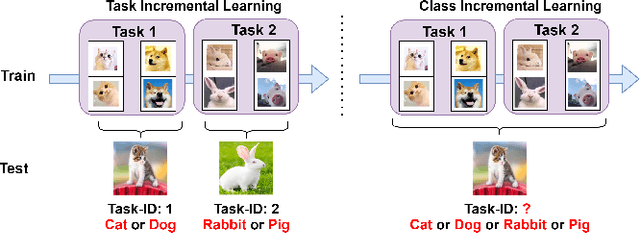
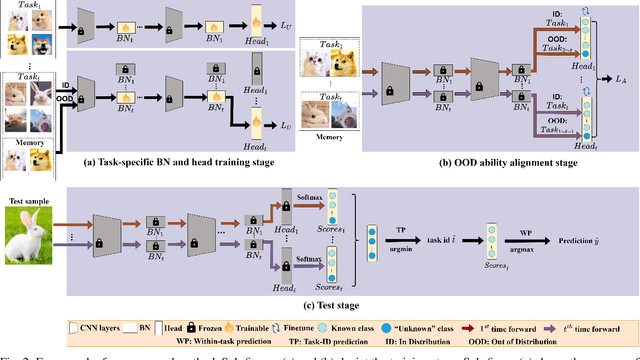
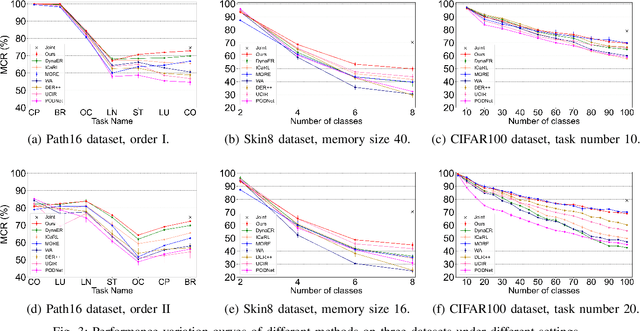
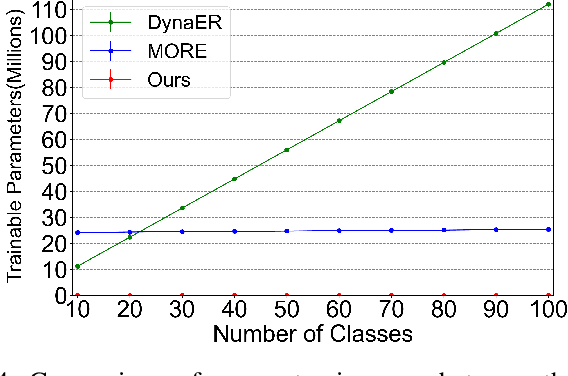
This study focuses on incremental learning for image classification, exploring how to reduce catastrophic forgetting of all learned knowledge when access to old data is restricted due to memory or privacy constraints. The challenge of incremental learning lies in achieving an optimal balance between plasticity, the ability to learn new knowledge, and stability, the ability to retain old knowledge. Based on whether the task identifier (task-ID) of an image can be obtained during the test stage, incremental learning for image classifcation is divided into two main paradigms, which are task incremental learning (TIL) and class incremental learning (CIL). The TIL paradigm has access to the task-ID, allowing it to use multiple task-specific classification heads selected based on the task-ID. Consequently, in CIL, where the task-ID is unavailable, TIL methods must predict the task-ID to extend their application to the CIL paradigm. Our previous method for TIL adds task-specific batch normalization and classification heads incrementally. This work extends the method by predicting task-ID through an "unknown" class added to each classification head. The head with the lowest "unknown" probability is selected, enabling task-ID prediction and making the method applicable to CIL. The task-specific batch normalization (BN) modules effectively adjust the distribution of output feature maps across different tasks, enhancing the model's plasticity.Moreover, since BN has much fewer parameters compared to convolutional kernels, by only modifying the BN layers as new tasks arrive, the model can effectively manage parameter growth while ensuring stability across tasks. The innovation of this study lies in the first-time introduction of task-specific BN into CIL and verifying the feasibility of extending TIL methods to CIL through task-ID prediction with state-of-the-art performance on multiple datasets.
DiffuTraj: A Stochastic Vessel Trajectory Prediction Approach via Guided Diffusion Process
Oct 12, 2024Maritime vessel maneuvers, characterized by their inherent complexity and indeterminacy, requires vessel trajectory prediction system capable of modeling the multi-modality nature of future motion states. Conventional stochastic trajectory prediction methods utilize latent variables to represent the multi-modality of vessel motion, however, tends to overlook the complexity and dynamics inherent in maritime behavior. In contrast, we explicitly simulate the transition of vessel motion from uncertainty towards a state of certainty, effectively handling future indeterminacy in dynamic scenes. In this paper, we present a novel framework (\textit{DiffuTraj}) to conceptualize the trajectory prediction task as a guided reverse process of motion pattern uncertainty diffusion, in which we progressively remove uncertainty from maritime regions to delineate the intended trajectory. Specifically, we encode the previous states of the target vessel, vessel-vessel interactions, and the environment context as guiding factors for trajectory generation. Subsequently, we devise a transformer-based conditional denoiser to capture spatio-temporal dependencies, enabling the generation of trajectories better aligned for particular maritime environment. Comprehensive experiments on vessel trajectory prediction benchmarks demonstrate the superiority of our method.
Synergistic Anchored Contrastive Pre-training for Few-Shot Relation Extraction
Dec 24, 2023



Few-shot Relation Extraction (FSRE) aims to extract relational facts from a sparse set of labeled corpora. Recent studies have shown promising results in FSRE by employing Pre-trained Language Models (PLMs) within the framework of supervised contrastive learning, which considers both instances and label facts. However, how to effectively harness massive instance-label pairs to encompass the learned representation with semantic richness in this learning paradigm is not fully explored. To address this gap, we introduce a novel synergistic anchored contrastive pre-training framework. This framework is motivated by the insight that the diverse viewpoints conveyed through instance-label pairs capture incomplete yet complementary intrinsic textual semantics. Specifically, our framework involves a symmetrical contrastive objective that encompasses both sentence-anchored and label-anchored contrastive losses. By combining these two losses, the model establishes a robust and uniform representation space. This space effectively captures the reciprocal alignment of feature distributions among instances and relational facts, simultaneously enhancing the maximization of mutual information across diverse perspectives within the same relation. Experimental results demonstrate that our framework achieves significant performance enhancements compared to baseline models in downstream FSRE tasks. Furthermore, our approach exhibits superior adaptability to handle the challenges of domain shift and zero-shot relation extraction. Our code is available online at https://github.com/AONE-NLP/FSRE-SaCon.