 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass Incremental Learning with Task-Specific Batch Normalization and Out-of-Distribution Detection
Nov 01, 2024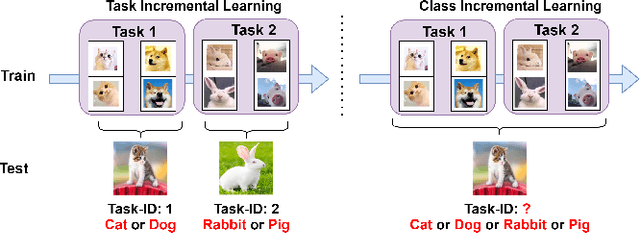
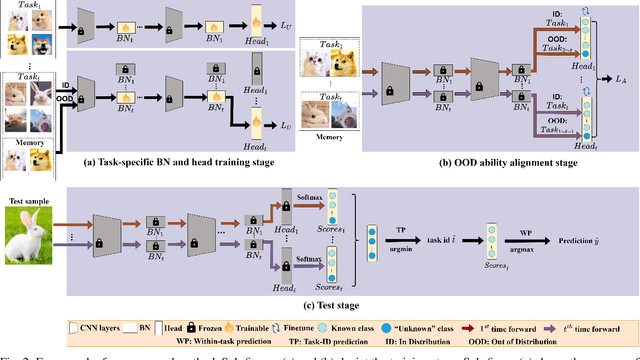
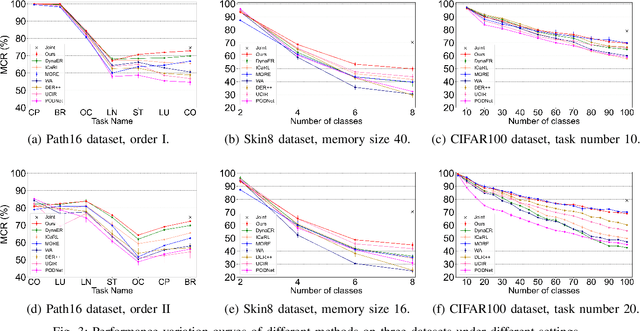
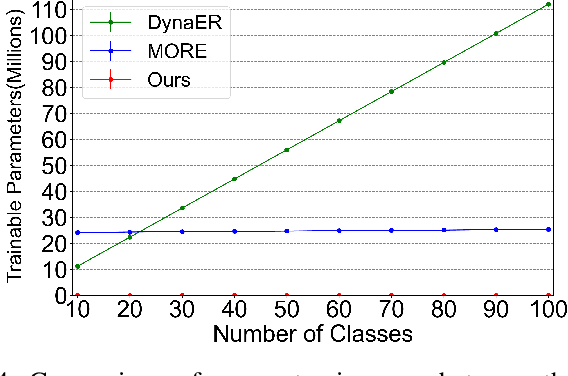
This study focuses on incremental learning for image classification, exploring how to reduce catastrophic forgetting of all learned knowledge when access to old data is restricted due to memory or privacy constraints. The challenge of incremental learning lies in achieving an optimal balance between plasticity, the ability to learn new knowledge, and stability, the ability to retain old knowledge. Based on whether the task identifier (task-ID) of an image can be obtained during the test stage, incremental learning for image classifcation is divided into two main paradigms, which are task incremental learning (TIL) and class incremental learning (CIL). The TIL paradigm has access to the task-ID, allowing it to use multiple task-specific classification heads selected based on the task-ID. Consequently, in CIL, where the task-ID is unavailable, TIL methods must predict the task-ID to extend their application to the CIL paradigm. Our previous method for TIL adds task-specific batch normalization and classification heads incrementally. This work extends the method by predicting task-ID through an "unknown" class added to each classification head. The head with the lowest "unknown" probability is selected, enabling task-ID prediction and making the method applicable to CIL. The task-specific batch normalization (BN) modules effectively adjust the distribution of output feature maps across different tasks, enhancing the model's plasticity.Moreover, since BN has much fewer parameters compared to convolutional kernels, by only modifying the BN layers as new tasks arrive, the model can effectively manage parameter growth while ensuring stability across tasks. The innovation of this study lies in the first-time introduction of task-specific BN into CIL and verifying the feasibility of extending TIL methods to CIL through task-ID prediction with state-of-the-art performance on multiple datasets.
Anything in Any Scene: Photorealistic Video Object Insertion
Jan 30, 2024Realistic video simulation has shown significant potential across diverse applications, from virtual reality to film production. This is particularly true for scenarios where capturing videos in real-world settings is either impractical or expensive. Existing approaches in video simulation often fail to accurately model the lighting environment, represent the object geometry, or achieve high levels of photorealism. In this paper, we propose Anything in Any Scene, a novel and generic framework for realistic video simulation that seamlessly inserts any object into an existing dynamic video with a strong emphasis on physical realism. Our proposed general framework encompasses three key processes: 1) integrating a realistic object into a given scene video with proper placement to ensure geometric realism; 2) estimating the sky and environmental lighting distribution and simulating realistic shadows to enhance the light realism; 3) employing a style transfer network that refines the final video output to maximize photorealism. We experimentally demonstrate that Anything in Any Scene framework produces simulated videos of great geometric realism, lighting realism, and photorealism. By significantly mitigating the challenges associated with video data generation, our framework offers an efficient and cost-effective solution for acquiring high-quality videos. Furthermore, its applications extend well beyond video data augmentation, showing promising potential in virtual reality, video editing, and various other video-centric applications. Please check our project website https://anythinginanyscene.github.io for access to our project code and more high-resolution video results.
Classifier-head Informed Feature Masking and Prototype-based Logit Smoothing for Out-of-Distribution Detection
Oct 27, 2023Out-of-distribution (OOD) detection is essential when deploying neural networks in the real world. One main challenge is that neural networks often make overconfident predictions on OOD data. In this study, we propose an effective post-hoc OOD detection method based on a new feature masking strategy and a novel logit smoothing strategy. Feature masking determines the important features at the penultimate layer for each in-distribution (ID) class based on the weights of the ID class in the classifier head and masks the rest features. Logit smoothing computes the cosine similarity between the feature vector of the test sample and the prototype of the predicted ID class at the penultimate layer and uses the similarity as an adaptive temperature factor on the logit to alleviate the network's overconfidence prediction for OOD data. With these strategies, we can reduce feature activation of OOD data and enlarge the gap in OOD score between ID and OOD data. Extensive experiments on multiple standard OOD detection benchmarks demonstrate the effectiveness of our method and its compatibility with existing methods, with new state-of-the-art performance achieved from our method. The source code will be released publicly.
SATS: Self-Attention Transfer for Continual Semantic Segmentation
Mar 15, 2022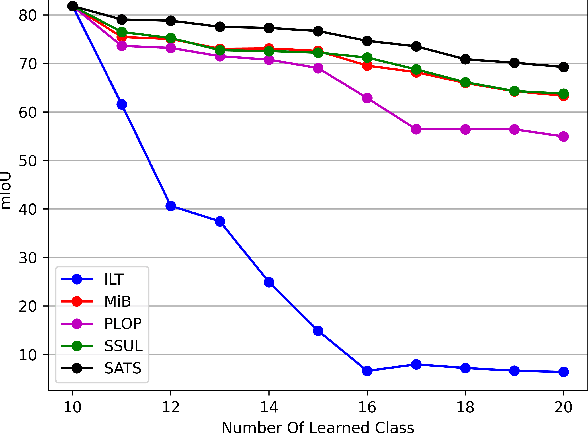
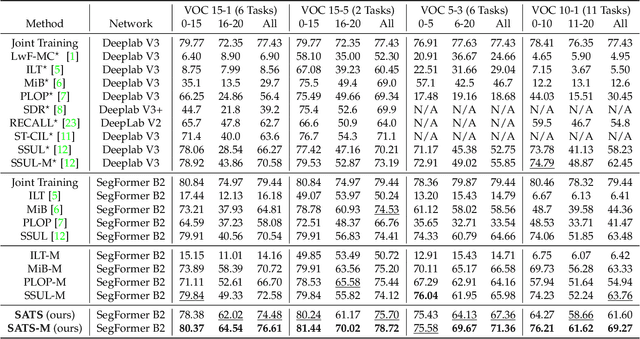
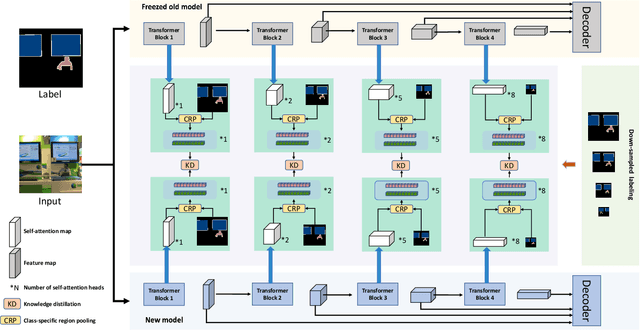
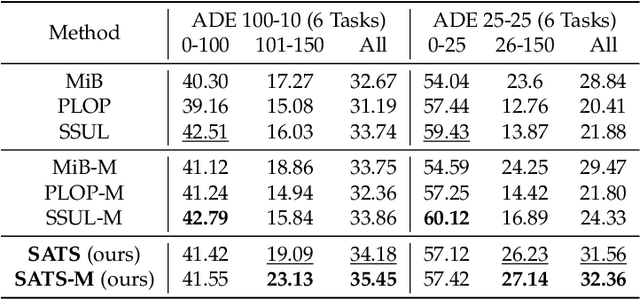
Continually learning to segment more and more types of image regions is a desired capability for many intelligent systems. However, such continual semantic segmentation suffers from the same catastrophic forgetting issue as in continual classification learning. While multiple knowledge distillation strategies originally for continual classification have been well adapted to continual semantic segmentation, they only consider transferring old knowledge based on the outputs from one or more layers of deep fully convolutional networks. Different from existing solutions, this study proposes to transfer a new type of information relevant to knowledge, i.e. the relationships between elements (Eg. pixels or small local regions) within each image which can capture both within-class and between-class knowledge. The relationship information can be effectively obtained from the self-attention maps in a Transformer-style segmentation model. Considering that pixels belonging to the same class in each image often share similar visual properties, a class-specific region pooling is applied to provide more efficient relationship information for knowledge transfer. Extensive evaluations on multiple public benchmarks support that the proposed self-attention transfer method can further effectively alleviate the catastrophic forgetting issue, and its flexible combination with one or more widely adopted strategies significantly outperforms state-of-the-art solu
Topic Driven Adaptive Network for Cross-Domain Sentiment Classification
Nov 28, 2021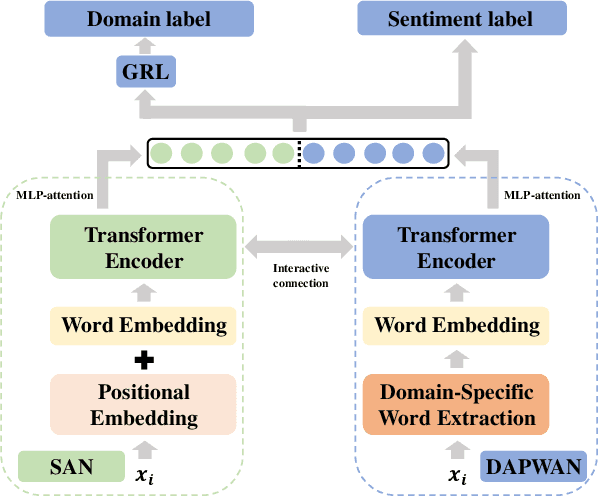
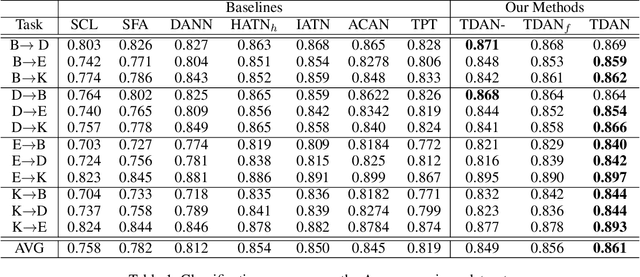
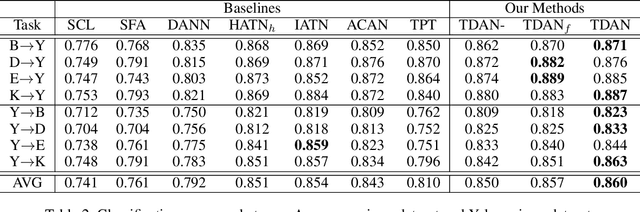

Cross-domain sentiment classification has been a hot spot these years, which aims to learn a reliable classifier using labeled data from the source domain and evaluate it on the target domain. In this vein, most approaches utilized domain adaptation that maps data from different domains into a common feature space. To further improve the model performance, several methods targeted to mine domain-specific information were proposed. However, most of them only utilized a limited part of domain-specific information. In this study, we first develop a method of extracting domain-specific words based on the topic information. Then, we propose a Topic Driven Adaptive Network (TDAN) for cross-domain sentiment classification. The network consists of two sub-networks: semantics attention network and domain-specific word attention network, the structures of which are based on transformers. These sub-networks take different forms of input and their outputs are fused as the feature vector. Experiments validate the effectiveness of our TDAN on sentiment classification across domains.