 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFood Portion Estimation via 3D Object Scaling
Apr 18, 2024



Image-based methods to analyze food images have alleviated the user burden and biases associated with traditional methods. However, accurate portion estimation remains a major challenge due to the loss of 3D information in the 2D representation of foods captured by smartphone cameras or wearable devices. In this paper, we propose a new framework to estimate both food volume and energy from 2D images by leveraging the power of 3D food models and physical reference in the eating scene. Our method estimates the pose of the camera and the food object in the input image and recreates the eating occasion by rendering an image of a 3D model of the food with the estimated poses. We also introduce a new dataset, SimpleFood45, which contains 2D images of 45 food items and associated annotations including food volume, weight, and energy. Our method achieves an average error of 31.10 kCal (17.67%) on this dataset, outperforming existing portion estimation methods.
Anything in Any Scene: Photorealistic Video Object Insertion
Jan 30, 2024Realistic video simulation has shown significant potential across diverse applications, from virtual reality to film production. This is particularly true for scenarios where capturing videos in real-world settings is either impractical or expensive. Existing approaches in video simulation often fail to accurately model the lighting environment, represent the object geometry, or achieve high levels of photorealism. In this paper, we propose Anything in Any Scene, a novel and generic framework for realistic video simulation that seamlessly inserts any object into an existing dynamic video with a strong emphasis on physical realism. Our proposed general framework encompasses three key processes: 1) integrating a realistic object into a given scene video with proper placement to ensure geometric realism; 2) estimating the sky and environmental lighting distribution and simulating realistic shadows to enhance the light realism; 3) employing a style transfer network that refines the final video output to maximize photorealism. We experimentally demonstrate that Anything in Any Scene framework produces simulated videos of great geometric realism, lighting realism, and photorealism. By significantly mitigating the challenges associated with video data generation, our framework offers an efficient and cost-effective solution for acquiring high-quality videos. Furthermore, its applications extend well beyond video data augmentation, showing promising potential in virtual reality, video editing, and various other video-centric applications. Please check our project website https://anythinginanyscene.github.io for access to our project code and more high-resolution video results.
An End-to-end Food Portion Estimation Framework Based on Shape Reconstruction from Monocular Image
Aug 03, 2023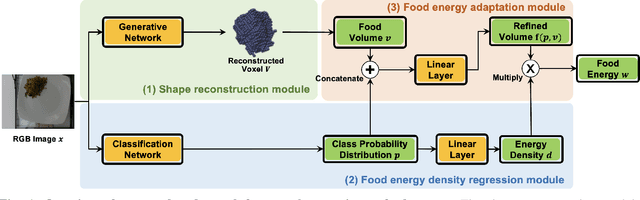
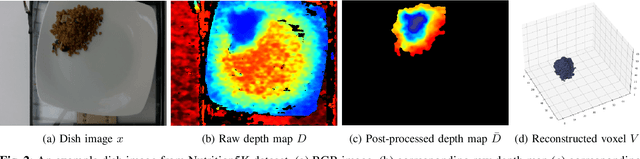
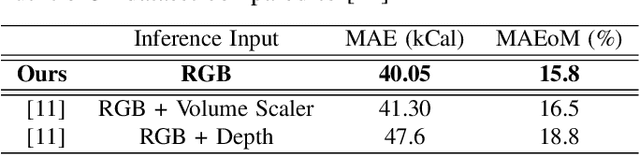

Dietary assessment is a key contributor to monitoring health status. Existing self-report methods are tedious and time-consuming with substantial biases and errors. Image-based food portion estimation aims to estimate food energy values directly from food images, showing great potential for automated dietary assessment solutions. Existing image-based methods either use a single-view image or incorporate multi-view images and depth information to estimate the food energy, which either has limited performance or creates user burdens. In this paper, we propose an end-to-end deep learning framework for food energy estimation from a monocular image through 3D shape reconstruction. We leverage a generative model to reconstruct the voxel representation of the food object from the input image to recover the missing 3D information. Our method is evaluated on a publicly available food image dataset Nutrition5k, resulting a Mean Absolute Error (MAE) of 40.05 kCal and Mean Absolute Percentage Error (MAPE) of 11.47% for food energy estimation. Our method uses RGB image as the only input at the inference stage and achieves competitive results compared to the existing method requiring both RGB and depth information.
Image Based Food Energy Estimation With Depth Domain Adaptation
Aug 25, 2022



Assessment of dietary intake has primarily relied on self-report instruments, which are prone to measurement errors. Dietary assessment methods have increasingly incorporated technological advances particularly mobile, image based approaches to address some of these limitations and further automation. Mobile, image-based methods can reduce user burden and bias by automatically estimating dietary intake from eating occasion images that are captured by mobile devices. In this paper, we propose an "Energy Density Map" which is a pixel-to-pixel mapping from the RGB image to the energy density of the food. We then incorporate the "Energy Density Map" with an associated depth map that is captured by a depth sensor to estimate the food energy. The proposed method is evaluated on the Nutrition5k dataset. Experimental results show improved results compared to baseline methods with an average error of 13.29 kCal and an average percentage error of 13.57% between the ground-truth and the estimated energy of the food.
Towards the Creation of a Nutrition and Food Group Based Image Database
Jun 05, 2022
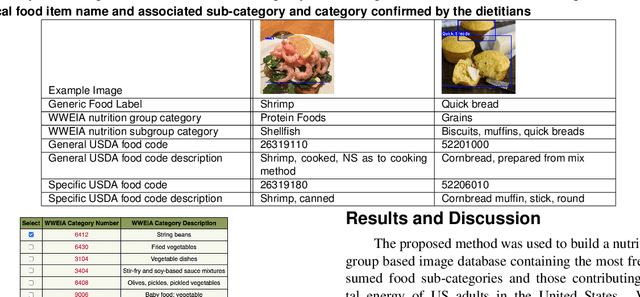


Food classification is critical to the analysis of nutrients comprising foods reported in dietary assessment. Advances in mobile and wearable sensors, combined with new image based methods, particularly deep learning based approaches, have shown great promise to improve the accuracy of food classification to assess dietary intake. However, these approaches are data-hungry and their performances are heavily reliant on the quantity and quality of the available datasets for training the food classification model. Existing food image datasets are not suitable for fine-grained food classification and the following nutrition analysis as they lack fine-grained and transparently derived food group based identification which are often provided by trained dietitians with expert domain knowledge. In this paper, we propose a framework to create a nutrition and food group based image database that contains both visual and hierarchical food categorization information to enhance links to the nutrient profile of each food. We design a protocol for linking food group based food codes in the U.S. Department of Agriculture's (USDA) Food and Nutrient Database for Dietary Studies (FNDDS) to a food image dataset, and implement a web-based annotation tool for efficient deployment of this protocol.Our proposed method is used to build a nutrition and food group based image database including 16,114 food images representing the 74 most frequently consumed What We Eat in America (WWEIA) food sub-categories in the United States with 1,865 USDA food code matched to a nutrient database, the USDA FNDDS nutrient database.
An Integrated System for Mobile Image-Based Dietary Assessment
Oct 05, 2021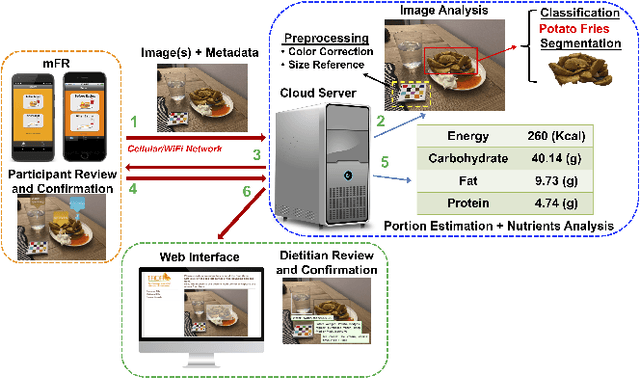
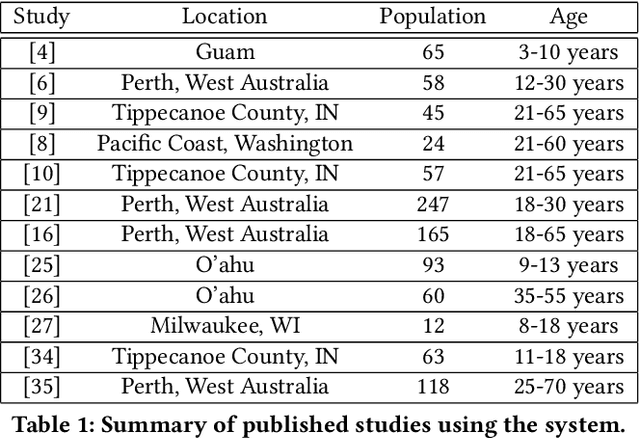
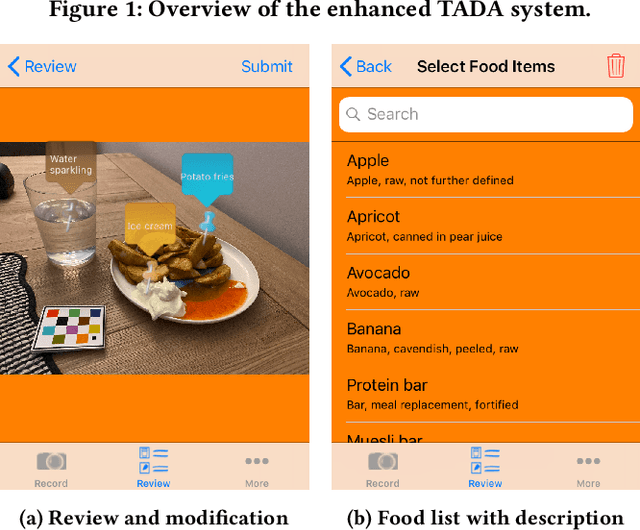

Accurate assessment of dietary intake requires improved tools to overcome limitations of current methods including user burden and measurement error. Emerging technologies such as image-based approaches using advanced machine learning techniques coupled with widely available mobile devices present new opportunities to improve the accuracy of dietary assessment that is cost-effective, convenient and timely. However, the quality and quantity of datasets are essential for achieving good performance for automated image analysis. Building a large image dataset with high quality groundtruth annotation is a challenging problem, especially for food images as the associated nutrition information needs to be provided or verified by trained dietitians with domain knowledge. In this paper, we present the design and development of a mobile, image-based dietary assessment system to capture and analyze dietary intake, which has been deployed in both controlled-feeding and community-dwelling dietary studies. Our system is capable of collecting high quality food images in naturalistic settings and provides groundtruth annotations for developing new computational approaches.
Improving Dietary Assessment Via Integrated Hierarchy Food Classification
Sep 06, 2021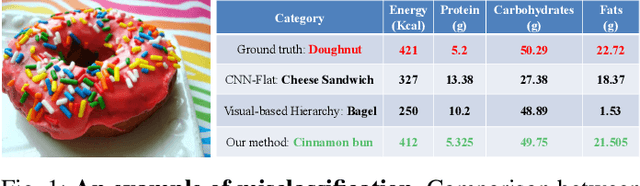
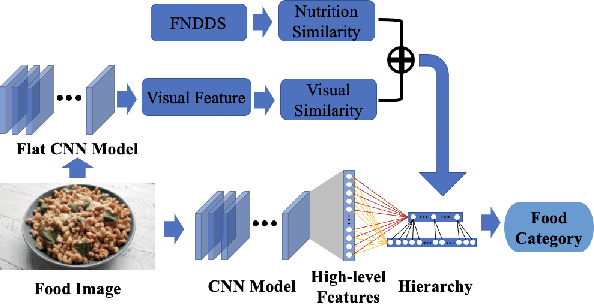
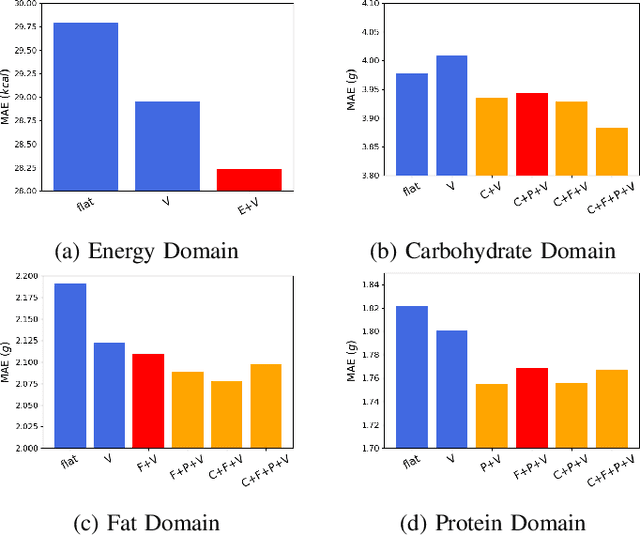

Image-based dietary assessment refers to the process of determining what someone eats and how much energy and nutrients are consumed from visual data. Food classification is the first and most crucial step. Existing methods focus on improving accuracy measured by the rate of correct classification based on visual information alone, which is very challenging due to the high complexity and inter-class similarity of foods. Further, accuracy in food classification is conceptual as description of a food can always be improved. In this work, we introduce a new food classification framework to improve the quality of predictions by integrating the information from multiple domains while maintaining the classification accuracy. We apply a multi-task network based on a hierarchical structure that uses both visual and nutrition domain specific information to cluster similar foods. Our method is validated on the modified VIPER-FoodNet (VFN) food image dataset by including associated energy and nutrient information. We achieve comparable classification accuracy with existing methods that use visual information only, but with less error in terms of energy and nutrient values for the wrong predictions.
Towards Learning Food Portion From Monocular Images With Cross-Domain Feature Adaptation
Mar 12, 2021
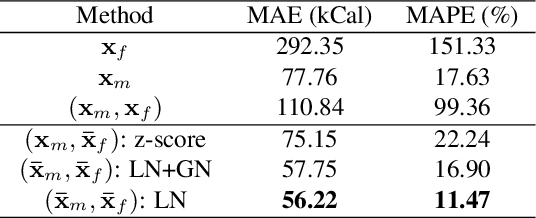
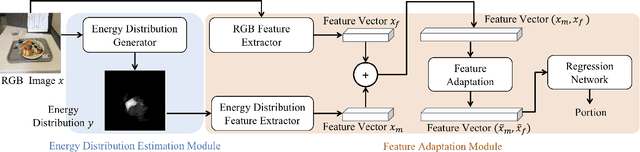

We aim to estimate food portion size, a property that is strongly related to the presence of food object in 3D space, from single monocular images under real life setting. Specifically, we are interested in end-to-end estimation of food portion size, which has great potential in the field of personal health management. Unlike image segmentation or object recognition where annotation can be obtained through large scale crowd sourcing, it is much more challenging to collect datasets for portion size estimation since human cannot accurately estimate the size of an object in an arbitrary 2D image without expert knowledge. To address such challenge, we introduce a real life food image dataset collected from a nutrition study where the groundtruth food energy (calorie) is provided by registered dietitians, and will be made available to the research community. We propose a deep regression process for portion size estimation by combining features estimated from both RGB and learned energy distribution domains. Our estimates of food energy achieved state-of-the-art with a MAPE of 11.47%, significantly outperforms non-expert human estimates by 27.56%.
An End-to-End Food Image Analysis System
Feb 01, 2021
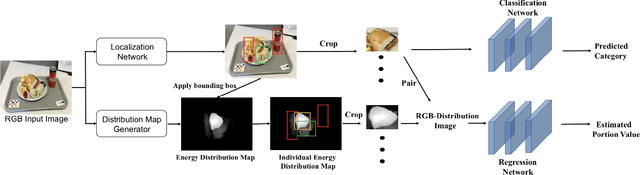
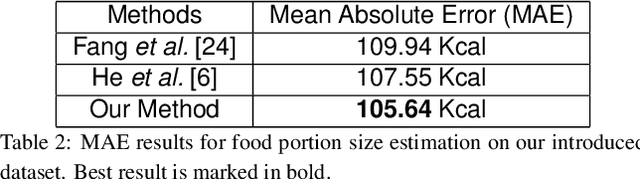

Modern deep learning techniques have enabled advances in image-based dietary assessment such as food recognition and food portion size estimation. Valuable information on the types of foods and the amount consumed are crucial for prevention of many chronic diseases. However, existing methods for automated image-based food analysis are neither end-to-end nor are capable of processing multiple tasks (e.g., recognition and portion estimation) together, making it difficult to apply to real life applications. In this paper, we propose an image-based food analysis framework that integrates food localization, classification and portion size estimation. Our proposed framework is end-to-end, i.e., the input can be an arbitrary food image containing multiple food items and our system can localize each single food item with its corresponding predicted food type and portion size. We also improve the single food portion estimation by consolidating localization results with a food energy distribution map obtained by conditional GAN to generate a four-channel RGB-Distribution image. Our end-to-end framework is evaluated on a real life food image dataset collected from a nutrition feeding study.
Visual Aware Hierarchy Based Food Recognition
Dec 06, 2020
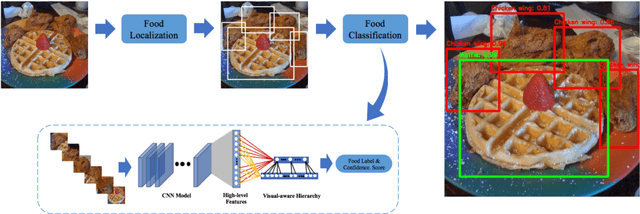

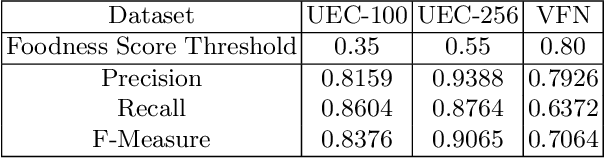
Food recognition is one of the most important components in image-based dietary assessment. However, due to the different complexity level of food images and inter-class similarity of food categories, it is challenging for an image-based food recognition system to achieve high accuracy for a variety of publicly available datasets. In this work, we propose a new two-step food recognition system that includes food localization and hierarchical food classification using Convolutional Neural Networks (CNNs) as the backbone architecture. The food localization step is based on an implementation of the Faster R-CNN method to identify food regions. In the food classification step, visually similar food categories can be clustered together automatically to generate a hierarchical structure that represents the semantic visual relations among food categories, then a multi-task CNN model is proposed to perform the classification task based on the visual aware hierarchical structure. Since the size and quality of dataset is a key component of data driven methods, we introduce a new food image dataset, VIPER-FoodNet (VFN) dataset, consists of 82 food categories with 15k images based on the most commonly consumed foods in the United States. A semi-automatic crowdsourcing tool is used to provide the ground-truth information for this dataset including food object bounding boxes and food object labels. Experimental results demonstrate that our system can significantly improve both classification and recognition performance on 4 publicly available datasets and the new VFN dataset.