 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Tailed Continual Learning For Visual Food Recognition
Jul 01, 2023



Deep learning based food recognition has achieved remarkable progress in predicting food types given an eating occasion image. However, there are two major obstacles that hinder deployment in real world scenario. First, as new foods appear sequentially overtime, a trained model needs to learn the new classes continuously without causing catastrophic forgetting for already learned knowledge of existing food types. Second, the distribution of food images in real life is usually long-tailed as a small number of popular food types are consumed more frequently than others, which can vary in different populations. This requires the food recognition method to learn from class-imbalanced data by improving the generalization ability on instance-rare food classes. In this work, we focus on long-tailed continual learning and aim to address both aforementioned challenges. As existing long-tailed food image datasets only consider healthy people population, we introduce two new benchmark food image datasets, VFN-INSULIN and VFN-T2D, which exhibits on the real world food consumption for insulin takers and individuals with type 2 diabetes without taking insulin, respectively. We propose a novel end-to-end framework for long-tailed continual learning, which effectively addresses the catastrophic forgetting by applying an additional predictor for knowledge distillation to avoid misalignment of representation during continual learning. We also introduce a novel data augmentation technique by integrating class-activation-map (CAM) and CutMix, which significantly improves the generalization ability for instance-rare food classes to address the class-imbalance issue. The proposed method show promising performance with large margin improvements compared with existing methods.
Long-tailed Food Classification
Oct 26, 2022Food classification serves as the basic step of image-based dietary assessment to predict the types of foods in each input image. However, food image predictions in a real world scenario are usually long-tail distributed among different food classes, which cause heavy class-imbalance problems and a restricted performance. In addition, none of the existing long-tailed classification methods focus on food data, which can be more challenging due to the lower inter-class and higher intra-class similarity among foods. In this work, we first introduce two new benchmark datasets for long-tailed food classification including Food101-LT and VFN-LT where the number of samples in VFN-LT exhibits the real world long-tailed food distribution. Then we propose a novel 2-Phase framework to address the problem of class-imbalance by (1) undersampling the head classes to remove redundant samples along with maintaining the learned information through knowledge distillation, and (2) oversampling the tail classes by performing visual-aware data augmentation. We show the effectiveness of our method by comparing with existing state-of-the-art long-tailed classification methods and show improved performance on both Food101-LT and VFN-LT benchmarks. The results demonstrate the potential to apply our method to related real life applications.
Towards the Creation of a Nutrition and Food Group Based Image Database
Jun 05, 2022
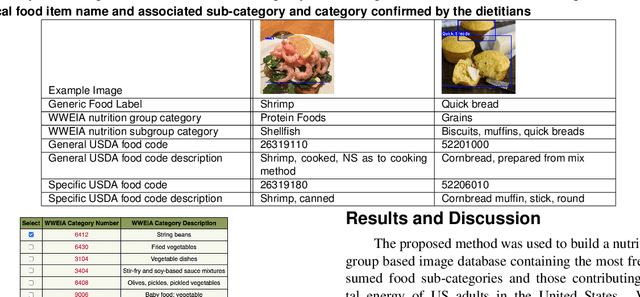


Food classification is critical to the analysis of nutrients comprising foods reported in dietary assessment. Advances in mobile and wearable sensors, combined with new image based methods, particularly deep learning based approaches, have shown great promise to improve the accuracy of food classification to assess dietary intake. However, these approaches are data-hungry and their performances are heavily reliant on the quantity and quality of the available datasets for training the food classification model. Existing food image datasets are not suitable for fine-grained food classification and the following nutrition analysis as they lack fine-grained and transparently derived food group based identification which are often provided by trained dietitians with expert domain knowledge. In this paper, we propose a framework to create a nutrition and food group based image database that contains both visual and hierarchical food categorization information to enhance links to the nutrient profile of each food. We design a protocol for linking food group based food codes in the U.S. Department of Agriculture's (USDA) Food and Nutrient Database for Dietary Studies (FNDDS) to a food image dataset, and implement a web-based annotation tool for efficient deployment of this protocol.Our proposed method is used to build a nutrition and food group based image database including 16,114 food images representing the 74 most frequently consumed What We Eat in America (WWEIA) food sub-categories in the United States with 1,865 USDA food code matched to a nutrient database, the USDA FNDDS nutrient database.
Improving Dietary Assessment Via Integrated Hierarchy Food Classification
Sep 06, 2021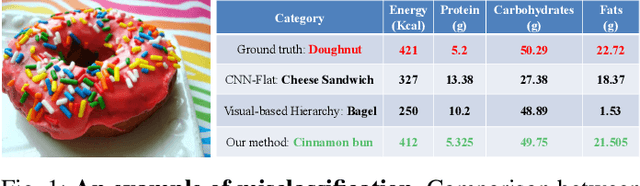
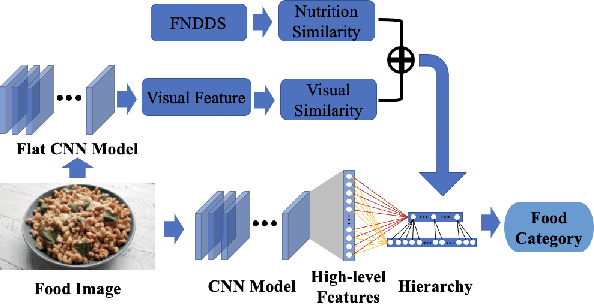
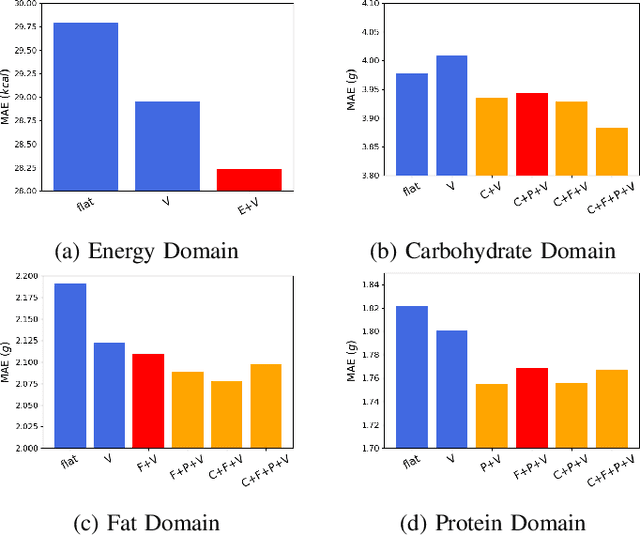

Image-based dietary assessment refers to the process of determining what someone eats and how much energy and nutrients are consumed from visual data. Food classification is the first and most crucial step. Existing methods focus on improving accuracy measured by the rate of correct classification based on visual information alone, which is very challenging due to the high complexity and inter-class similarity of foods. Further, accuracy in food classification is conceptual as description of a food can always be improved. In this work, we introduce a new food classification framework to improve the quality of predictions by integrating the information from multiple domains while maintaining the classification accuracy. We apply a multi-task network based on a hierarchical structure that uses both visual and nutrition domain specific information to cluster similar foods. Our method is validated on the modified VIPER-FoodNet (VFN) food image dataset by including associated energy and nutrient information. We achieve comparable classification accuracy with existing methods that use visual information only, but with less error in terms of energy and nutrient values for the wrong predictions.