 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCIE: Multimodal LLM-Driven Complex Instruction Image Editing with Spatial Guidance
Feb 08, 2026Recent advances in instruction-based image editing have shown remarkable progress. However, existing methods remain limited to relatively simple editing operations, hindering real-world applications that require complex and compositional instructions. In this work, we address these limitations from the perspectives of architectural design, data, and evaluation protocols. Specifically, we identify two key challenges in current models: insufficient instruction compliance and background inconsistency. To this end, we propose MCIE-E1, a Multimodal Large Language Model-Driven Complex Instruction Image Editing method that integrates two key modules: a spatial-aware cross-attention module and a background-consistent cross-attention module. The former enhances instruction-following capability by explicitly aligning semantic instructions with spatial regions through spatial guidance during the denoising process, while the latter preserves features in unedited regions to maintain background consistency. To enable effective training, we construct a dedicated data pipeline to mitigate the scarcity of complex instruction-based image editing datasets, combining fine-grained automatic filtering via a powerful MLLM with rigorous human validation. Finally, to comprehensively evaluate complex instruction-based image editing, we introduce CIE-Bench, a new benchmark with two new evaluation metrics. Experimental results on CIE-Bench demonstrate that MCIE-E1 consistently outperforms previous state-of-the-art methods in both quantitative and qualitative assessments, achieving a 23.96% improvement in instruction compliance.
An Improved Encoder-Decoder Framework for Food Energy Estimation
Sep 22, 2023



Dietary assessment is essential to maintaining a healthy lifestyle. Automatic image-based dietary assessment is a growing field of research due to the increasing prevalence of image capturing devices (e.g. mobile phones). In this work, we estimate food energy from a single monocular image, a difficult task due to the limited hard-to-extract amount of energy information present in an image. To do so, we employ an improved encoder-decoder framework for energy estimation; the encoder transforms the image into a representation embedded with food energy information in an easier-to-extract format, which the decoder then extracts the energy information from. To implement our method, we compile a high-quality food image dataset verified by registered dietitians containing eating scene images, food-item segmentation masks, and ground truth calorie values. Our method improves upon previous caloric estimation methods by over 10\% and 30 kCal in terms of MAPE and MAE respectively.
An Improved Upper Bound on the Rate-Distortion Function of Images
Sep 05, 2023



Recent work has shown that Variational Autoencoders (VAEs) can be used to upper-bound the information rate-distortion (R-D) function of images, i.e., the fundamental limit of lossy image compression. In this paper, we report an improved upper bound on the R-D function of images implemented by (1) introducing a new VAE model architecture, (2) applying variable-rate compression techniques, and (3) proposing a novel \ourfunction{} to stabilize training. We demonstrate that at least 30\% BD-rate reduction w.r.t. the intra prediction mode in VVC codec is achievable, suggesting that there is still great potential for improving lossy image compression. Code is made publicly available at https://github.com/duanzhiihao/lossy-vae.
Long-Tailed Continual Learning For Visual Food Recognition
Jul 01, 2023



Deep learning based food recognition has achieved remarkable progress in predicting food types given an eating occasion image. However, there are two major obstacles that hinder deployment in real world scenario. First, as new foods appear sequentially overtime, a trained model needs to learn the new classes continuously without causing catastrophic forgetting for already learned knowledge of existing food types. Second, the distribution of food images in real life is usually long-tailed as a small number of popular food types are consumed more frequently than others, which can vary in different populations. This requires the food recognition method to learn from class-imbalanced data by improving the generalization ability on instance-rare food classes. In this work, we focus on long-tailed continual learning and aim to address both aforementioned challenges. As existing long-tailed food image datasets only consider healthy people population, we introduce two new benchmark food image datasets, VFN-INSULIN and VFN-T2D, which exhibits on the real world food consumption for insulin takers and individuals with type 2 diabetes without taking insulin, respectively. We propose a novel end-to-end framework for long-tailed continual learning, which effectively addresses the catastrophic forgetting by applying an additional predictor for knowledge distillation to avoid misalignment of representation during continual learning. We also introduce a novel data augmentation technique by integrating class-activation-map (CAM) and CutMix, which significantly improves the generalization ability for instance-rare food classes to address the class-imbalance issue. The proposed method show promising performance with large margin improvements compared with existing methods.
QARV: Quantization-Aware ResNet VAE for Lossy Image Compression
Feb 16, 2023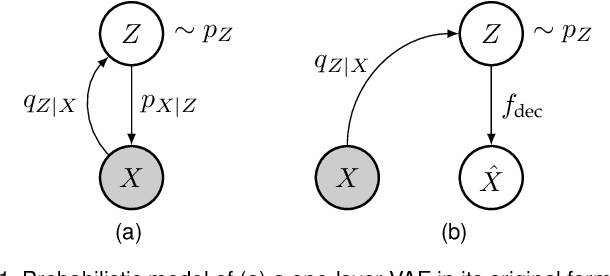
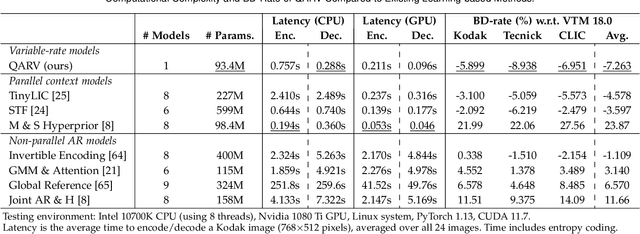
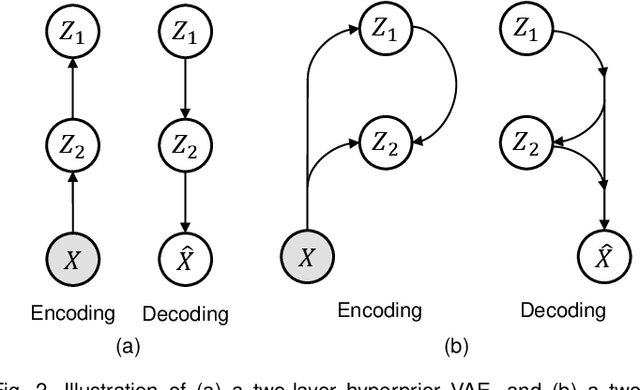
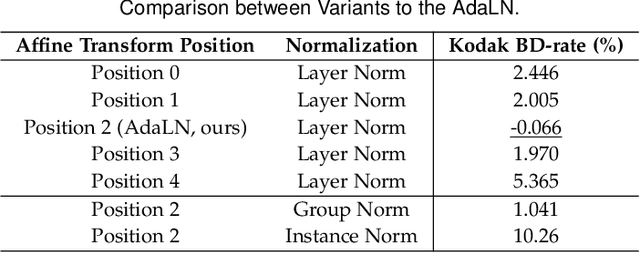
We consider the problem of lossy image compression, a fundamental problem in both information theory and many real-world applications. We begin by reviewing the relationship between variational autoencoders (VAEs), a powerful class of deep generative models, and rate-distortion theory, the theoretical foundation for lossy compression. By combining the ResNet VAE architecture and techniques including test-time quantization and quantization-aware training, we present a quantization-aware ResNet VAE (QARV) framework for lossy image compression. For sake of practical usage, we propose a new neural network architecture for fast decoding, and we introduce an adaptive normalization operation for variable-rate coding. QARV employs a hierarchical progressive coding structure, supports continuously variable-rate compression with fast entropy coding, and gives a better rate-distortion efficiency than existing baseline methods. Code is made publicly available at https://github.com/duanzhiihao/lossy-vae