 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DG-STFM: 3D Geometric Guided Student-Teacher Feature Matching
Jul 06, 2022
We tackle the essential task of finding dense visual correspondences between a pair of images. This is a challenging problem due to various factors such as poor texture, repetitive patterns, illumination variation, and motion blur in practical scenarios. In contrast to methods that use dense correspondence ground-truths as direct supervision for local feature matching training, we train 3DG-STFM: a multi-modal matching model (Teacher) to enforce the depth consistency under 3D dense correspondence supervision and transfer the knowledge to 2D unimodal matching model (Student). Both teacher and student models consist of two transformer-based matching modules that obtain dense correspondences in a coarse-to-fine manner. The teacher model guides the student model to learn RGB-induced depth information for the matching purpose on both coarse and fine branches. We also evaluate 3DG-STFM on a model compression task. To the best of our knowledge, 3DG-STFM is the first student-teacher learning method for the local feature matching task. The experiments show that our method outperforms state-of-the-art methods on indoor and outdoor camera pose estimations, and homography estimation problems. Code is available at: https://github.com/Ryan-prime/3DG-STFM.
An Integrated System for Mobile Image-Based Dietary Assessment
Oct 05, 2021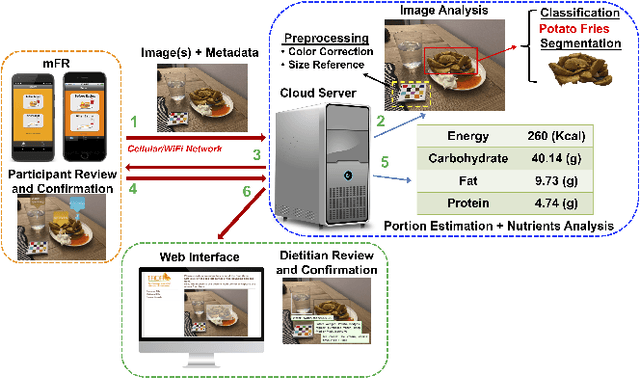
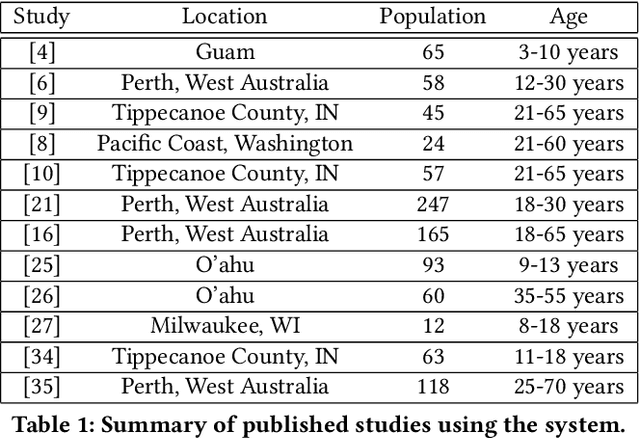
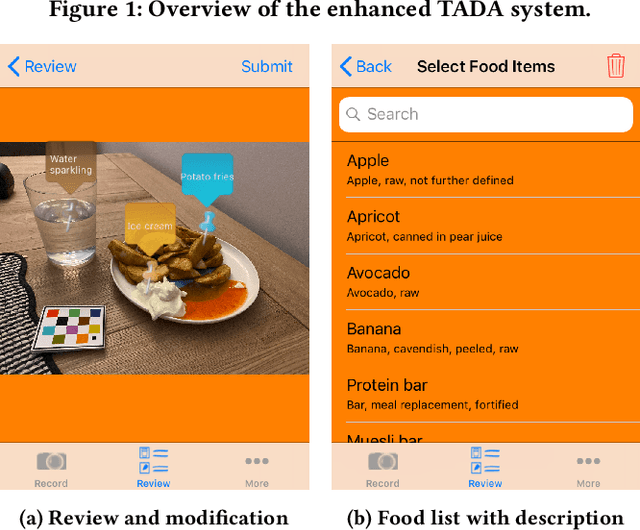

Accurate assessment of dietary intake requires improved tools to overcome limitations of current methods including user burden and measurement error. Emerging technologies such as image-based approaches using advanced machine learning techniques coupled with widely available mobile devices present new opportunities to improve the accuracy of dietary assessment that is cost-effective, convenient and timely. However, the quality and quantity of datasets are essential for achieving good performance for automated image analysis. Building a large image dataset with high quality groundtruth annotation is a challenging problem, especially for food images as the associated nutrition information needs to be provided or verified by trained dietitians with domain knowledge. In this paper, we present the design and development of a mobile, image-based dietary assessment system to capture and analyze dietary intake, which has been deployed in both controlled-feeding and community-dwelling dietary studies. Our system is capable of collecting high quality food images in naturalistic settings and provides groundtruth annotations for developing new computational approaches.
Motion Artifact Reduction In Photoplethysmography For Reliable Signal Selection
Sep 06, 2021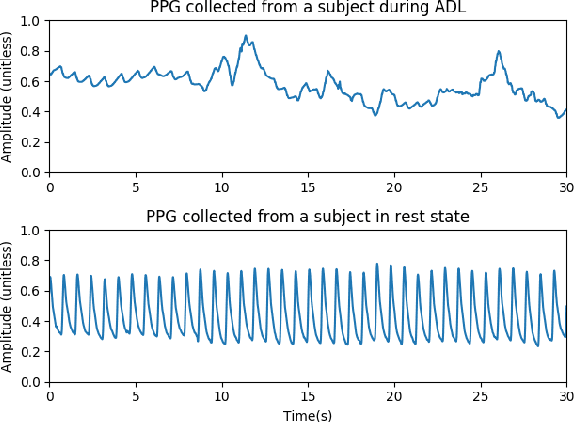
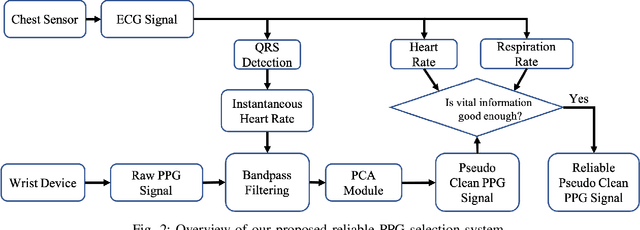
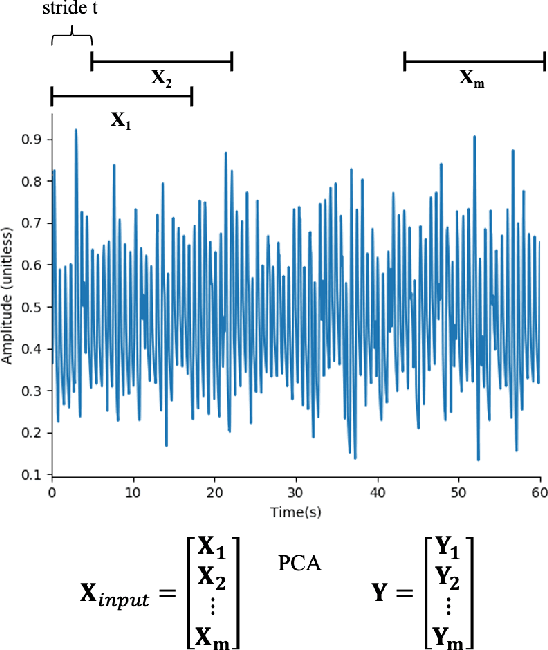
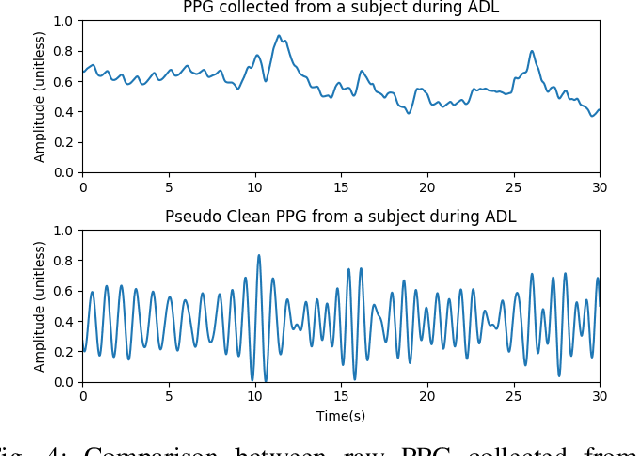
Photoplethysmography (PPG) is a non-invasive and economical technique to extract vital signs of the human body. Although it has been widely used in consumer and research grade wrist devices to track a user's physiology, the PPG signal is very sensitive to motion which can corrupt the signal's quality. Existing Motion Artifact (MA) reduction techniques have been developed and evaluated using either synthetic noisy signals or signals collected during high-intensity activities - both of which are difficult to generalize for real-life scenarios. Therefore, it is valuable to collect realistic PPG signals while performing Activities of Daily Living (ADL) to develop practical signal denoising and analysis methods. In this work, we propose an automatic pseudo clean PPG generation process for reliable PPG signal selection. For each noisy PPG segment, the corresponding pseudo clean PPG reduces the MAs and contains rich temporal details depicting cardiac features. Our experimental results show that 71% of the pseudo clean PPG collected from ADL can be considered as high quality segment where the derived MAE of heart rate and respiration rate are 1.46 BPM and 3.93 BrPM, respectively. Therefore, our proposed method can determine the reliability of the raw noisy PPG by considering quality of the corresponding pseudo clean PPG signal.
Improving Dietary Assessment Via Integrated Hierarchy Food Classification
Sep 06, 2021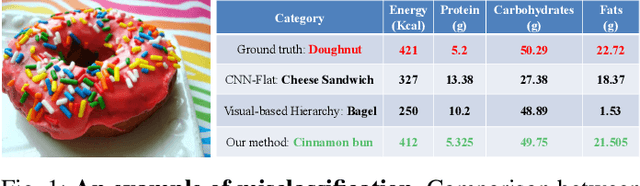
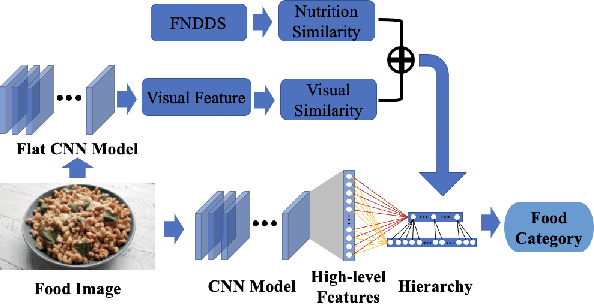
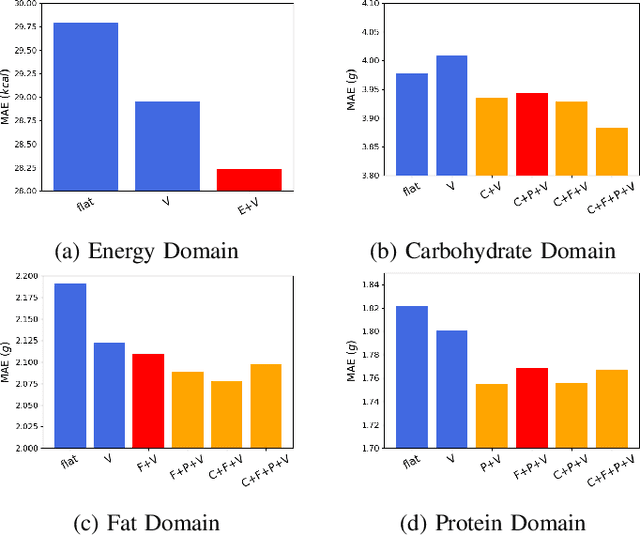

Image-based dietary assessment refers to the process of determining what someone eats and how much energy and nutrients are consumed from visual data. Food classification is the first and most crucial step. Existing methods focus on improving accuracy measured by the rate of correct classification based on visual information alone, which is very challenging due to the high complexity and inter-class similarity of foods. Further, accuracy in food classification is conceptual as description of a food can always be improved. In this work, we introduce a new food classification framework to improve the quality of predictions by integrating the information from multiple domains while maintaining the classification accuracy. We apply a multi-task network based on a hierarchical structure that uses both visual and nutrition domain specific information to cluster similar foods. Our method is validated on the modified VIPER-FoodNet (VFN) food image dataset by including associated energy and nutrient information. We achieve comparable classification accuracy with existing methods that use visual information only, but with less error in terms of energy and nutrient values for the wrong predictions.
Towards Learning Food Portion From Monocular Images With Cross-Domain Feature Adaptation
Mar 12, 2021
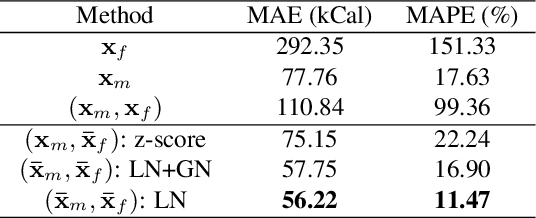
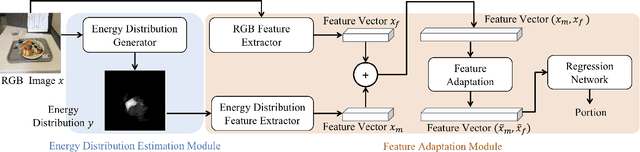

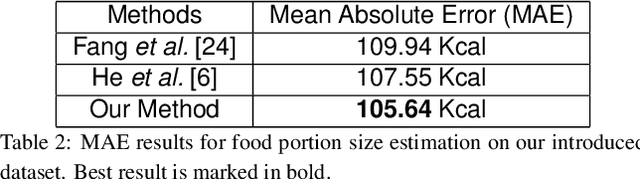
We aim to estimate food portion size, a property that is strongly related to the presence of food object in 3D space, from single monocular images under real life setting. Specifically, we are interested in end-to-end estimation of food portion size, which has great potential in the field of personal health management. Unlike image segmentation or object recognition where annotation can be obtained through large scale crowd sourcing, it is much more challenging to collect datasets for portion size estimation since human cannot accurately estimate the size of an object in an arbitrary 2D image without expert knowledge. To address such challenge, we introduce a real life food image dataset collected from a nutrition study where the groundtruth food energy (calorie) is provided by registered dietitians, and will be made available to the research community. We propose a deep regression process for portion size estimation by combining features estimated from both RGB and learned energy distribution domains. Our estimates of food energy achieved state-of-the-art with a MAPE of 11.47%, significantly outperforms non-expert human estimates by 27.56%.
An End-to-End Food Image Analysis System
Feb 01, 2021
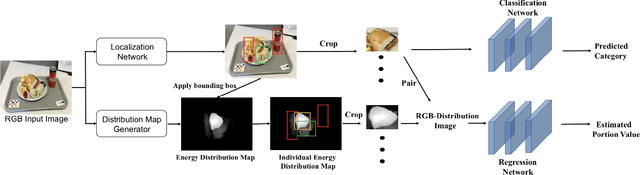

Modern deep learning techniques have enabled advances in image-based dietary assessment such as food recognition and food portion size estimation. Valuable information on the types of foods and the amount consumed are crucial for prevention of many chronic diseases. However, existing methods for automated image-based food analysis are neither end-to-end nor are capable of processing multiple tasks (e.g., recognition and portion estimation) together, making it difficult to apply to real life applications. In this paper, we propose an image-based food analysis framework that integrates food localization, classification and portion size estimation. Our proposed framework is end-to-end, i.e., the input can be an arbitrary food image containing multiple food items and our system can localize each single food item with its corresponding predicted food type and portion size. We also improve the single food portion estimation by consolidating localization results with a food energy distribution map obtained by conditional GAN to generate a four-channel RGB-Distribution image. Our end-to-end framework is evaluated on a real life food image dataset collected from a nutrition feeding study.
Visual Aware Hierarchy Based Food Recognition
Dec 06, 2020
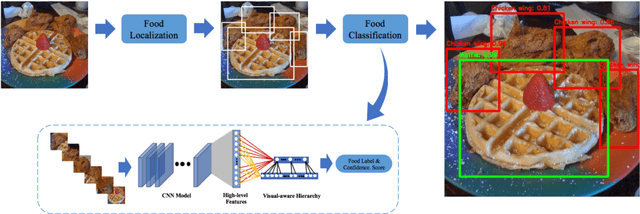

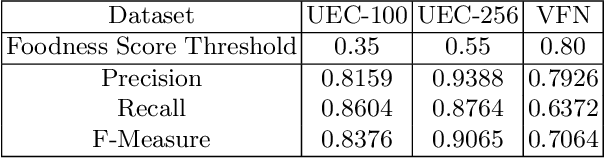
Food recognition is one of the most important components in image-based dietary assessment. However, due to the different complexity level of food images and inter-class similarity of food categories, it is challenging for an image-based food recognition system to achieve high accuracy for a variety of publicly available datasets. In this work, we propose a new two-step food recognition system that includes food localization and hierarchical food classification using Convolutional Neural Networks (CNNs) as the backbone architecture. The food localization step is based on an implementation of the Faster R-CNN method to identify food regions. In the food classification step, visually similar food categories can be clustered together automatically to generate a hierarchical structure that represents the semantic visual relations among food categories, then a multi-task CNN model is proposed to perform the classification task based on the visual aware hierarchical structure. Since the size and quality of dataset is a key component of data driven methods, we introduce a new food image dataset, VIPER-FoodNet (VFN) dataset, consists of 82 food categories with 15k images based on the most commonly consumed foods in the United States. A semi-automatic crowdsourcing tool is used to provide the ground-truth information for this dataset including food object bounding boxes and food object labels. Experimental results demonstrate that our system can significantly improve both classification and recognition performance on 4 publicly available datasets and the new VFN dataset.
Incremental Learning In Online Scenario
Mar 30, 2020



Modern deep learning approaches have achieved great success in many vision applications by training a model using all available task-specific data. However, there are two major obstacles making it challenging to implement for real life applications: (1) Learning new classes makes the trained model quickly forget old classes knowledge, which is referred to as catastrophic forgetting. (2) As new observations of old classes come sequentially over time, the distribution may change in unforeseen way, making the performance degrade dramatically on future data, which is referred to as concept drift. Current state-of-the-art incremental learning methods require a long time to train the model whenever new classes are added and none of them takes into consideration the new observations of old classes. In this paper, we propose an incremental learning framework that can work in the challenging online learning scenario and handle both new classes data and new observations of old classes. We address problem (1) in online mode by introducing a modified cross-distillation loss together with a two-step learning technique. Our method outperforms the results obtained from current state-of-the-art offline incremental learning methods on the CIFAR-100 and ImageNet-1000 (ILSVRC 2012) datasets under the same experiment protocol but in online scenario. We also provide a simple yet effective method to mitigate problem (2) by updating exemplar set using the feature of each new observation of old classes and demonstrate a real life application of online food image classification based on our complete framework using the Food-101 dataset.
Semi-Automatic Crowdsourcing Tool for Online Food Image Collection and Annotation
Oct 14, 2019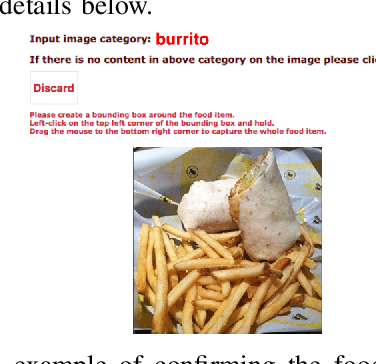

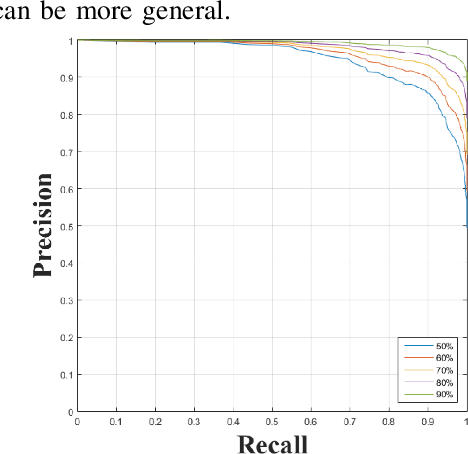
Assessing dietary intake accurately remains an open and challenging research problem. In recent years, image-based approaches have been developed to automatically estimate food intake by capturing eat occasions with mobile devices and wearable cameras. To build a reliable machine-learning models that can automatically map pixels to calories, successful image-based systems need large collections of food images with high quality groundtruth labels to improve the learned models. In this paper, we introduce a semi-automatic system for online food image collection and annotation. Our system consists of a web crawler, an automatic food detection method and a web-based crowdsoucing tool. The web crawler is used to download large sets of online food images based on the given food labels. Since not all retrieved images contain foods, we introduce an automatic food detection method to remove irrelevant images. We designed a web-based crowdsourcing tool to assist the crowd or human annotators to locate and label all the foods in the images. The proposed semi-automatic online food image collection system can be used to build large food image datasets with groundtruth labels efficiently from scratch.
Single-View Food Portion Estimation: Learning Image-to-Energy Mappings Using Generative Adversarial Networks
May 23, 2018
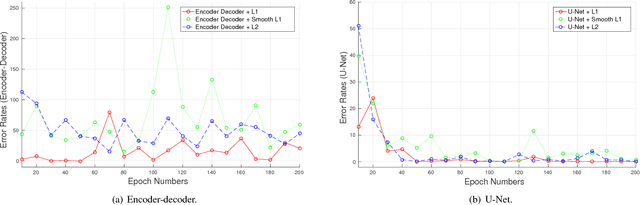
Due to the growing concern of chronic diseases and other health problems related to diet, there is a need to develop accurate methods to estimate an individual's food and energy intake. Measuring accurate dietary intake is an open research problem. In particular, accurate food portion estimation is challenging since the process of food preparation and consumption impose large variations on food shapes and appearances. In this paper, we present a food portion estimation method to estimate food energy (kilocalories) from food images using Generative Adversarial Networks (GAN). We introduce the concept of an "energy distribution" for each food image. To train the GAN, we design a food image dataset based on ground truth food labels and segmentation masks for each food image as well as energy information associated with the food image. Our goal is to learn the mapping of the food image to the food energy. We can then estimate food energy based on the energy distribution. We show that an average energy estimation error rate of 10.89% can be obtained by learning the image-to-energy mapping.