 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIVE: Scene Text Replacement In Videos
Sep 06, 2021
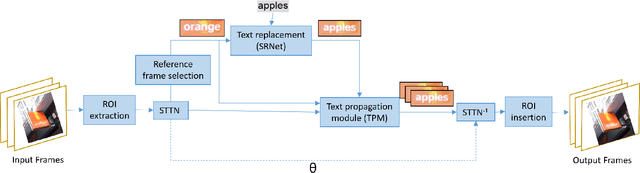
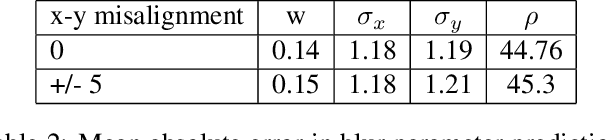
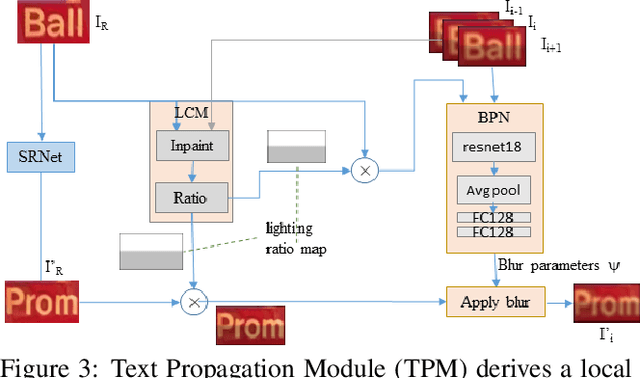
We propose replacing scene text in videos using deep style transfer and learned photometric transformations.Building on recent progress on still image text replacement,we present extensions that alter text while preserving the appearance and motion characteristics of the original video.Compared to the problem of still image text replacement,our method addresses additional challenges introduced by video, namely effects induced by changing lighting, motion blur, diverse variations in camera-object pose over time,and preservation of temporal consistency. We parse the problem into three steps. First, the text in all frames is normalized to a frontal pose using a spatio-temporal trans-former network. Second, the text is replaced in a single reference frame using a state-of-art still-image text replacement method. Finally, the new text is transferred from the reference to remaining frames using a novel learned image transformation network that captures lighting and blur effects in a temporally consistent manner. Results on synthetic and challenging real videos show realistic text trans-fer, competitive quantitative and qualitative performance,and superior inference speed relative to alternatives. We introduce new synthetic and real-world datasets with paired text objects. To the best of our knowledge this is the first attempt at deep video text replacement.
Towards Learning Food Portion From Monocular Images With Cross-Domain Feature Adaptation
Mar 12, 2021
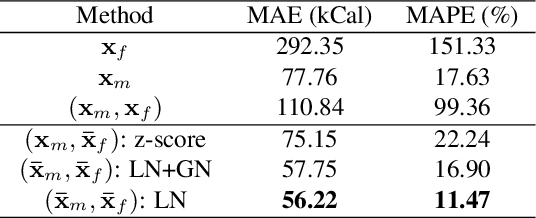
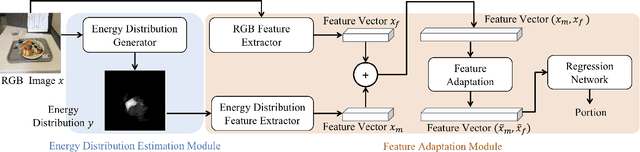

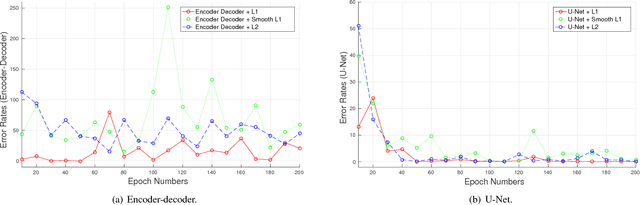
We aim to estimate food portion size, a property that is strongly related to the presence of food object in 3D space, from single monocular images under real life setting. Specifically, we are interested in end-to-end estimation of food portion size, which has great potential in the field of personal health management. Unlike image segmentation or object recognition where annotation can be obtained through large scale crowd sourcing, it is much more challenging to collect datasets for portion size estimation since human cannot accurately estimate the size of an object in an arbitrary 2D image without expert knowledge. To address such challenge, we introduce a real life food image dataset collected from a nutrition study where the groundtruth food energy (calorie) is provided by registered dietitians, and will be made available to the research community. We propose a deep regression process for portion size estimation by combining features estimated from both RGB and learned energy distribution domains. Our estimates of food energy achieved state-of-the-art with a MAPE of 11.47%, significantly outperforms non-expert human estimates by 27.56%.
Single-View Food Portion Estimation: Learning Image-to-Energy Mappings Using Generative Adversarial Networks
May 23, 2018
Due to the growing concern of chronic diseases and other health problems related to diet, there is a need to develop accurate methods to estimate an individual's food and energy intake. Measuring accurate dietary intake is an open research problem. In particular, accurate food portion estimation is challenging since the process of food preparation and consumption impose large variations on food shapes and appearances. In this paper, we present a food portion estimation method to estimate food energy (kilocalories) from food images using Generative Adversarial Networks (GAN). We introduce the concept of an "energy distribution" for each food image. To train the GAN, we design a food image dataset based on ground truth food labels and segmentation masks for each food image as well as energy information associated with the food image. Our goal is to learn the mapping of the food image to the food energy. We can then estimate food energy based on the energy distribution. We show that an average energy estimation error rate of 10.89% can be obtained by learning the image-to-energy mapping.