 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIVE: Scene Text Replacement In Videos
Sep 06, 2021
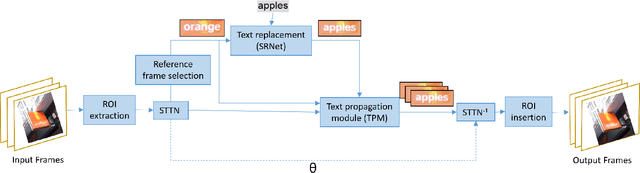
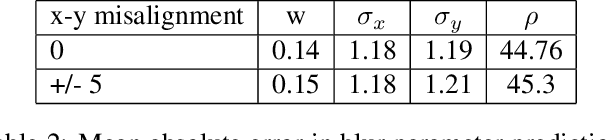
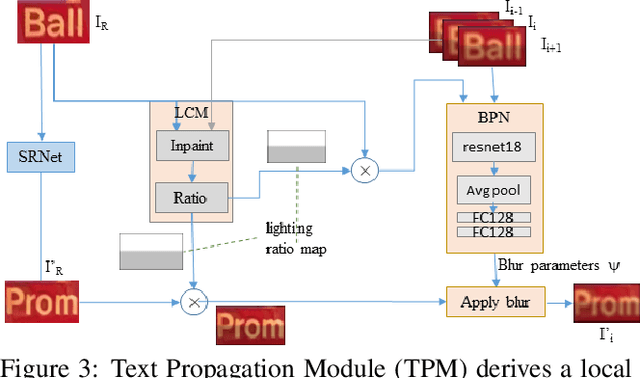
We propose replacing scene text in videos using deep style transfer and learned photometric transformations.Building on recent progress on still image text replacement,we present extensions that alter text while preserving the appearance and motion characteristics of the original video.Compared to the problem of still image text replacement,our method addresses additional challenges introduced by video, namely effects induced by changing lighting, motion blur, diverse variations in camera-object pose over time,and preservation of temporal consistency. We parse the problem into three steps. First, the text in all frames is normalized to a frontal pose using a spatio-temporal trans-former network. Second, the text is replaced in a single reference frame using a state-of-art still-image text replacement method. Finally, the new text is transferred from the reference to remaining frames using a novel learned image transformation network that captures lighting and blur effects in a temporally consistent manner. Results on synthetic and challenging real videos show realistic text trans-fer, competitive quantitative and qualitative performance,and superior inference speed relative to alternatives. We introduce new synthetic and real-world datasets with paired text objects. To the best of our knowledge this is the first attempt at deep video text replacement.
Cooperative neural networks (CoNN): Exploiting prior independence structure for improved classification
Jun 01, 2019
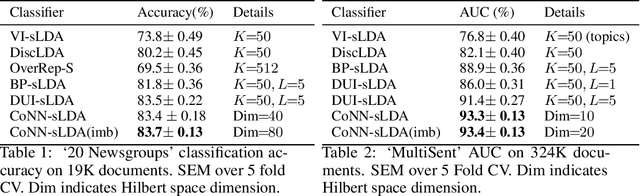
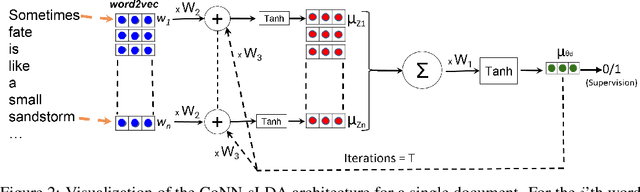
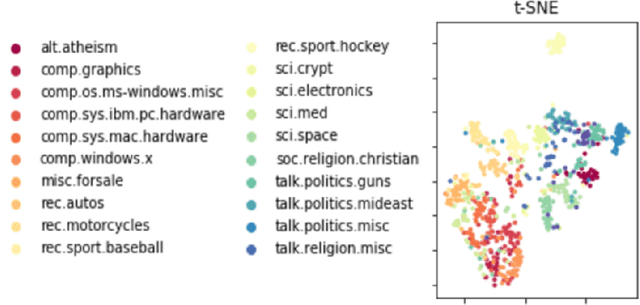
We propose a new approach, called cooperative neural networks (CoNN), which uses a set of cooperatively trained neural networks to capture latent representations that exploit prior given independence structure. The model is more flexible than traditional graphical models based on exponential family distributions, but incorporates more domain specific prior structure than traditional deep networks or variational autoencoders. The framework is very general and can be used to exploit the independence structure of any graphical model. We illustrate the technique by showing that we can transfer the independence structure of the popular Latent Dirichlet Allocation (LDA) model to a cooperative neural network, CoNN-sLDA. Empirical evaluation of CoNN-sLDA on supervised text classification tasks demonstrates that the theoretical advantages of prior independence structure can be realized in practice -we demonstrate a 23\% reduction in error on the challenging MultiSent data set compared to state-of-the-art.