 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Food Detection For Images From a Wearable Egocentric Camera
Jan 19, 2023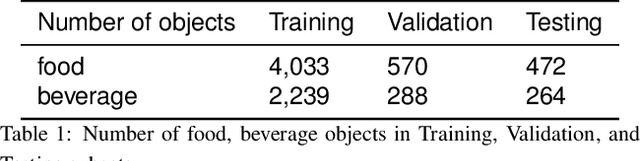
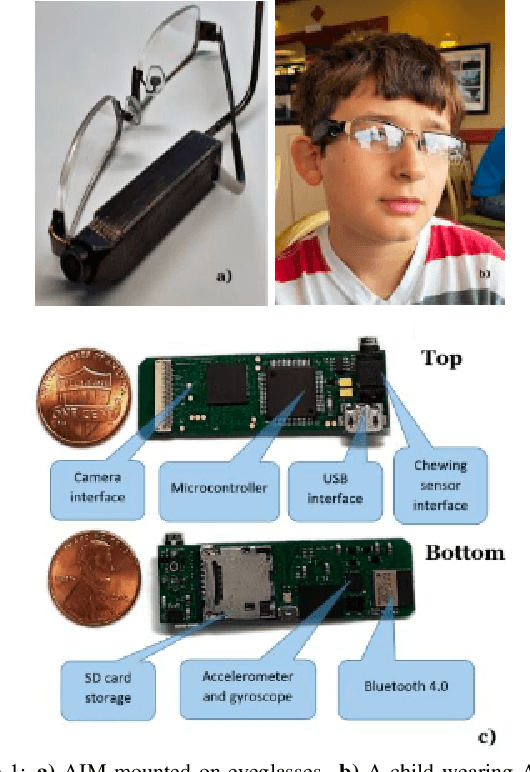

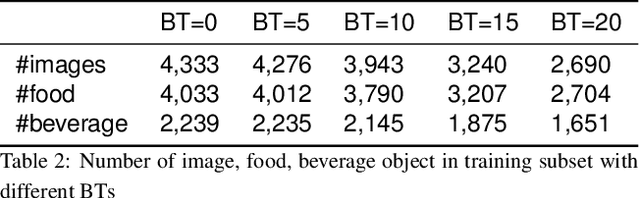
Diet is an important aspect of our health. Good dietary habits can contribute to the prevention of many diseases and improve the overall quality of life. To better understand the relationship between diet and health, image-based dietary assessment systems have been developed to collect dietary information. We introduce the Automatic Ingestion Monitor (AIM), a device that can be attached to one's eye glasses. It provides an automated hands-free approach to capture eating scene images. While AIM has several advantages, images captured by the AIM are sometimes blurry. Blurry images can significantly degrade the performance of food image analysis such as food detection. In this paper, we propose an approach to pre-process images collected by the AIM imaging sensor by rejecting extremely blurry images to improve the performance of food detection.
Splicing Detection and Localization In Satellite Imagery Using Conditional GANs
May 03, 2022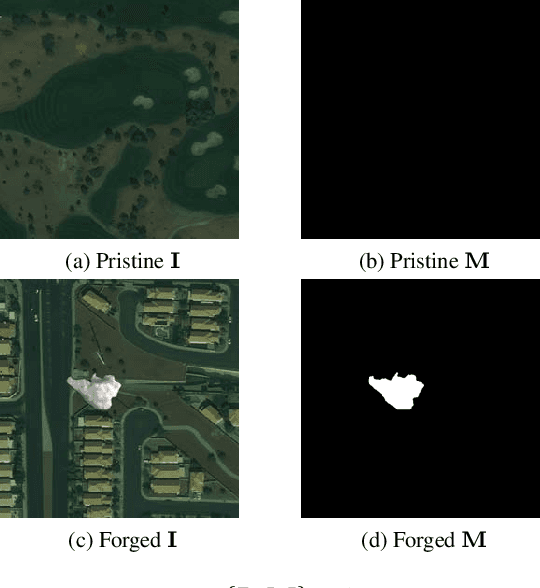


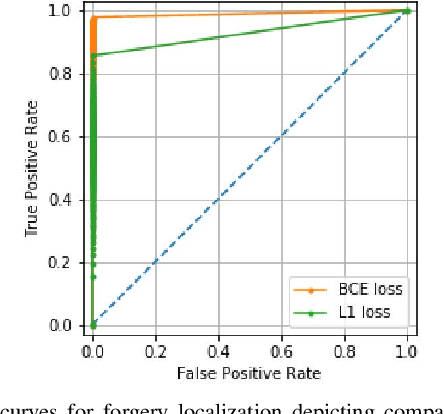
The widespread availability of image editing tools and improvements in image processing techniques allow image manipulation to be very easy. Oftentimes, easy-to-use yet sophisticated image manipulation tools yields distortions/changes imperceptible to the human observer. Distribution of forged images can have drastic ramifications, especially when coupled with the speed and vastness of the Internet. Therefore, verifying image integrity poses an immense and important challenge to the digital forensic community. Satellite images specifically can be modified in a number of ways, including the insertion of objects to hide existing scenes and structures. In this paper, we describe the use of a Conditional Generative Adversarial Network (cGAN) to identify the presence of such spliced forgeries within satellite images. Additionally, we identify their locations and shapes. Trained on pristine and falsified images, our method achieves high success on these detection and localization objectives.
* Accepted to the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR)
Saliency-Aware Class-Agnostic Food Image Segmentation
Feb 13, 2021
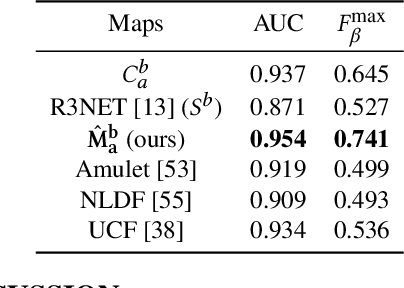
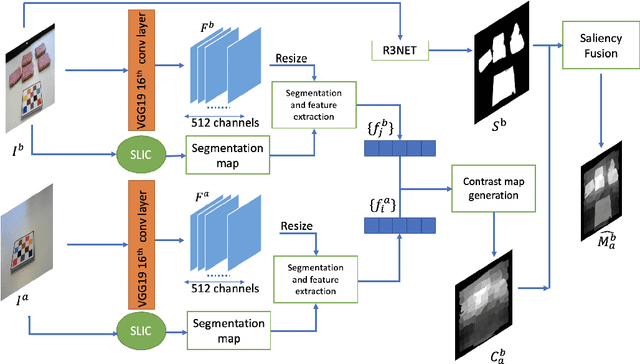
Advances in image-based dietary assessment methods have allowed nutrition professionals and researchers to improve the accuracy of dietary assessment, where images of food consumed are captured using smartphones or wearable devices. These images are then analyzed using computer vision methods to estimate energy and nutrition content of the foods. Food image segmentation, which determines the regions in an image where foods are located, plays an important role in this process. Current methods are data dependent, thus cannot generalize well for different food types. To address this problem, we propose a class-agnostic food image segmentation method. Our method uses a pair of eating scene images, one before start eating and one after eating is completed. Using information from both the before and after eating images, we can segment food images by finding the salient missing objects without any prior information about the food class. We model a paradigm of top down saliency which guides the attention of the human visual system (HVS) based on a task to find the salient missing objects in a pair of images. Our method is validated on food images collected from a dietary study which showed promising results.
Visual Aware Hierarchy Based Food Recognition
Dec 06, 2020
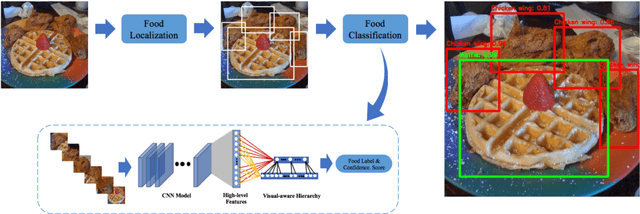

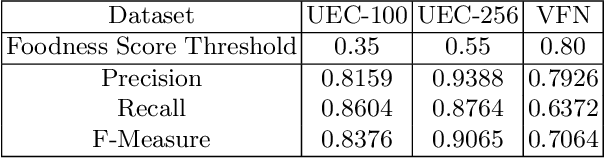
Food recognition is one of the most important components in image-based dietary assessment. However, due to the different complexity level of food images and inter-class similarity of food categories, it is challenging for an image-based food recognition system to achieve high accuracy for a variety of publicly available datasets. In this work, we propose a new two-step food recognition system that includes food localization and hierarchical food classification using Convolutional Neural Networks (CNNs) as the backbone architecture. The food localization step is based on an implementation of the Faster R-CNN method to identify food regions. In the food classification step, visually similar food categories can be clustered together automatically to generate a hierarchical structure that represents the semantic visual relations among food categories, then a multi-task CNN model is proposed to perform the classification task based on the visual aware hierarchical structure. Since the size and quality of dataset is a key component of data driven methods, we introduce a new food image dataset, VIPER-FoodNet (VFN) dataset, consists of 82 food categories with 15k images based on the most commonly consumed foods in the United States. A semi-automatic crowdsourcing tool is used to provide the ground-truth information for this dataset including food object bounding boxes and food object labels. Experimental results demonstrate that our system can significantly improve both classification and recognition performance on 4 publicly available datasets and the new VFN dataset.
Learning eating environments through scene clustering
Nov 10, 2019
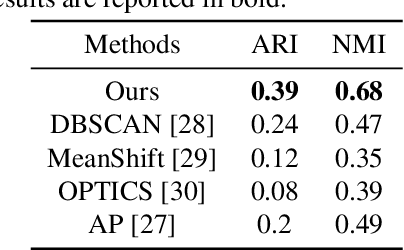

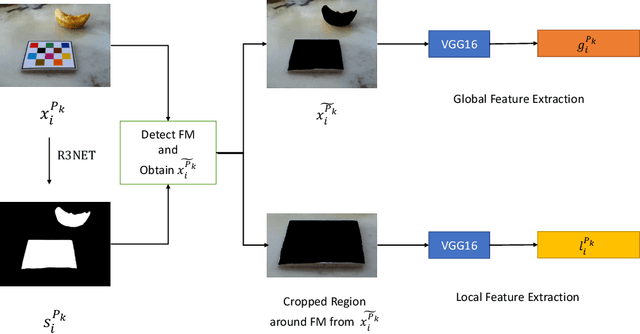
It is well known that dietary habits have a significant influence on health. While many studies have been conducted to understand this relationship, little is known about the relationship between eating environments and health. Yet researchers and health agencies around the world have recognized the eating environment as a promising context for improving diet and health. In this paper, we propose an image clustering method to automatically extract the eating environments from eating occasion images captured during a community dwelling dietary study. Specifically, we are interested in learning how many different environments an individual consumes food in. Our method clusters images by extracting features at both global and local scales using a deep neural network. The variation in the number of clusters and images captured by different individual makes this a very challenging problem. Experimental results show that our method performs significantly better compared to several existing clustering approaches.
A Reflectance Based Method For Shadow Detection and Removal
Jul 11, 2018

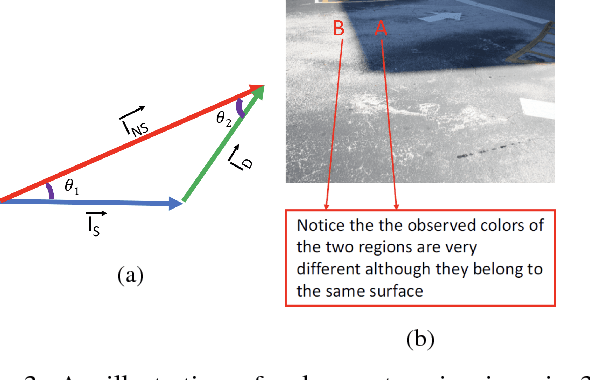
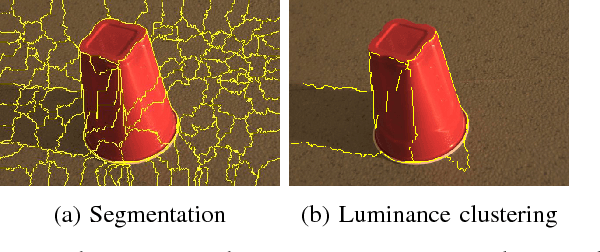
Shadows are common aspect of images and when left undetected can hinder scene understanding and visual processing. We propose a simple yet effective approach based on reflectance to detect shadows from single image. An image is first segmented and based on the reflectance, illumination and texture characteristics, segments pairs are identified as shadow and non-shadow pairs. The proposed method is tested on two publicly available and widely used datasets. Our method achieves higher accuracy in detecting shadows compared to previous reported methods despite requiring fewer parameters. We also show results of shadow-free images by relighting the pixels in the detected shadow regions.
Reliability Map Estimation For CNN-Based Camera Model Attribution
May 04, 2018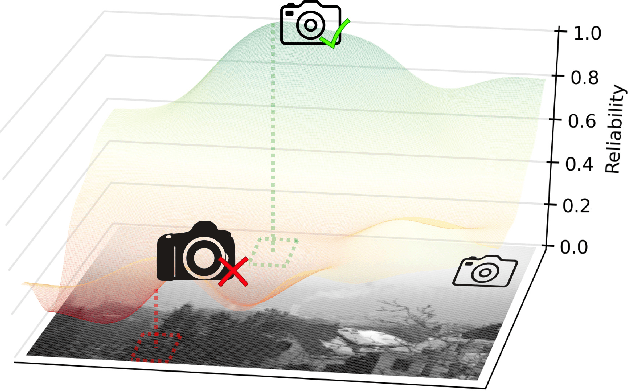
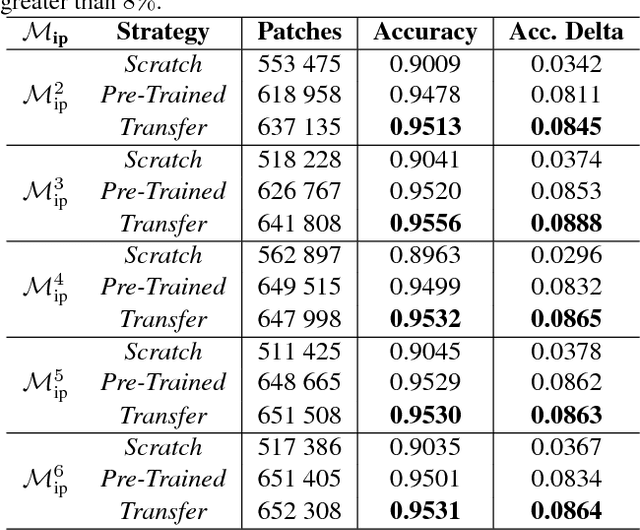

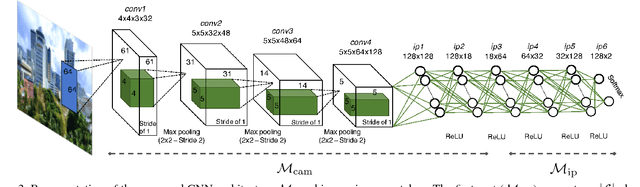
Among the image forensic issues investigated in the last few years, great attention has been devoted to blind camera model attribution. This refers to the problem of detecting which camera model has been used to acquire an image by only exploiting pixel information. Solving this problem has great impact on image integrity assessment as well as on authenticity verification. Recent advancements that use convolutional neural networks (CNNs) in the media forensic field have enabled camera model attribution methods to work well even on small image patches. These improvements are also important for determining forgery localization. Some patches of an image may not contain enough information related to the camera model (e.g., saturated patches). In this paper, we propose a CNN-based solution to estimate the camera model attribution reliability of a given image patch. We show that we can estimate a reliability-map indicating which portions of the image contain reliable camera traces. Testing using a well known dataset confirms that by using this information, it is possible to increase small patch camera model attribution accuracy by more than 8% on a single patch.
Satellite Image Forgery Detection and Localization Using GAN and One-Class Classifier
Feb 13, 2018
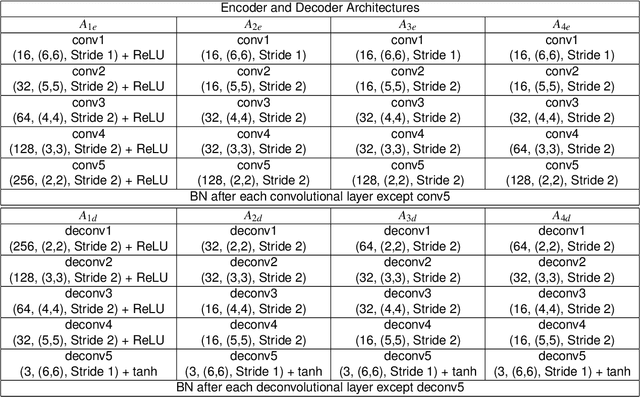
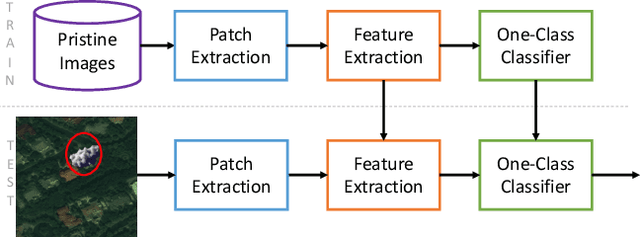

Current satellite imaging technology enables shooting high-resolution pictures of the ground. As any other kind of digital images, overhead pictures can also be easily forged. However, common image forensic techniques are often developed for consumer camera images, which strongly differ in their nature from satellite ones (e.g., compression schemes, post-processing, sensors, etc.). Therefore, many accurate state-of-the-art forensic algorithms are bound to fail if blindly applied to overhead image analysis. Development of novel forensic tools for satellite images is paramount to assess their authenticity and integrity. In this paper, we propose an algorithm for satellite image forgery detection and localization. Specifically, we consider the scenario in which pixels within a region of a satellite image are replaced to add or remove an object from the scene. Our algorithm works under the assumption that no forged images are available for training. Using a generative adversarial network (GAN), we learn a feature representation of pristine satellite images. A one-class support vector machine (SVM) is trained on these features to determine their distribution. Finally, image forgeries are detected as anomalies. The proposed algorithm is validated against different kinds of satellite images containing forgeries of different size and shape.