 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Shift Localization Network
Jun 10, 2025



Feature shifts between data sources are present in many applications involving healthcare, biomedical, socioeconomic, financial, survey, and multi-sensor data, among others, where unharmonized heterogeneous data sources, noisy data measurements, or inconsistent processing and standardization pipelines can lead to erroneous features. Localizing shifted features is important to address the underlying cause of the shift and correct or filter the data to avoid degrading downstream analysis. While many techniques can detect distribution shifts, localizing the features originating them is still challenging, with current solutions being either inaccurate or not scalable to large and high-dimensional datasets. In this work, we introduce the Feature Shift Localization Network (FSL-Net), a neural network that can localize feature shifts in large and high-dimensional datasets in a fast and accurate manner. The network, trained with a large number of datasets, learns to extract the statistical properties of the datasets and can localize feature shifts from previously unseen datasets and shifts without the need for re-training. The code and ready-to-use trained model are available at https://github.com/AI-sandbox/FSL-Net.
HyperFast: Instant Classification for Tabular Data
Feb 22, 2024



Training deep learning models and performing hyperparameter tuning can be computationally demanding and time-consuming. Meanwhile, traditional machine learning methods like gradient-boosting algorithms remain the preferred choice for most tabular data applications, while neural network alternatives require extensive hyperparameter tuning or work only in toy datasets under limited settings. In this paper, we introduce HyperFast, a meta-trained hypernetwork designed for instant classification of tabular data in a single forward pass. HyperFast generates a task-specific neural network tailored to an unseen dataset that can be directly used for classification inference, removing the need for training a model. We report extensive experiments with OpenML and genomic data, comparing HyperFast to competing tabular data neural networks, traditional ML methods, AutoML systems, and boosting machines. HyperFast shows highly competitive results, while being significantly faster. Additionally, our approach demonstrates robust adaptability across a variety of classification tasks with little to no fine-tuning, positioning HyperFast as a strong solution for numerous applications and rapid model deployment. HyperFast introduces a promising paradigm for fast classification, with the potential to substantially decrease the computational burden of deep learning. Our code, which offers a scikit-learn-like interface, along with the trained HyperFast model, can be found at https://github.com/AI-sandbox/HyperFast.
Adversarial Learning for Feature Shift Detection and Correction
Dec 07, 2023



Data shift is a phenomenon present in many real-world applications, and while there are multiple methods attempting to detect shifts, the task of localizing and correcting the features originating such shifts has not been studied in depth. Feature shifts can occur in many datasets, including in multi-sensor data, where some sensors are malfunctioning, or in tabular and structured data, including biomedical, financial, and survey data, where faulty standardization and data processing pipelines can lead to erroneous features. In this work, we explore using the principles of adversarial learning, where the information from several discriminators trained to distinguish between two distributions is used to both detect the corrupted features and fix them in order to remove the distribution shift between datasets. We show that mainstream supervised classifiers, such as random forest or gradient boosting trees, combined with simple iterative heuristics, can localize and correct feature shifts, outperforming current statistical and neural network-based techniques. The code is available at https://github.com/AI-sandbox/DataFix.
Manipulation Detection in Satellite Images Using Vision Transformer
May 13, 2021
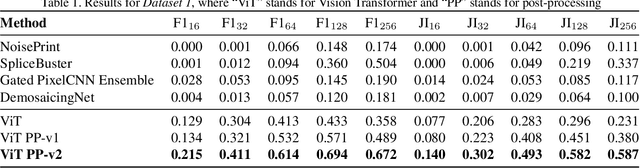
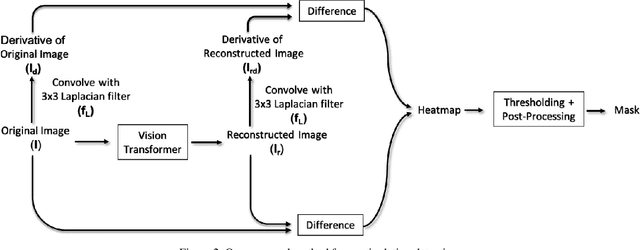

A growing number of commercial satellite companies provide easily accessible satellite imagery. Overhead imagery is used by numerous industries including agriculture, forestry, natural disaster analysis, and meteorology. Satellite images, just as any other images, can be tampered with image manipulation tools. Manipulation detection methods created for images captured by "consumer cameras" tend to fail when used on satellite images due to the differences in image sensors, image acquisition, and processing. In this paper we propose an unsupervised technique that uses a Vision Transformer to detect spliced areas within satellite images. We introduce a new dataset which includes manipulated satellite images that contain spliced objects. We show that our proposed approach performs better than existing unsupervised splicing detection techniques.
Saliency-Aware Class-Agnostic Food Image Segmentation
Feb 13, 2021
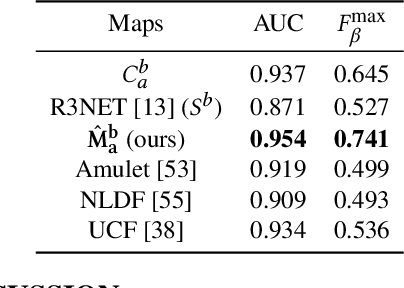
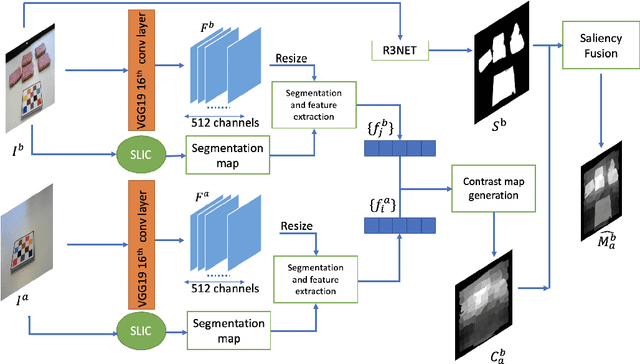
Advances in image-based dietary assessment methods have allowed nutrition professionals and researchers to improve the accuracy of dietary assessment, where images of food consumed are captured using smartphones or wearable devices. These images are then analyzed using computer vision methods to estimate energy and nutrition content of the foods. Food image segmentation, which determines the regions in an image where foods are located, plays an important role in this process. Current methods are data dependent, thus cannot generalize well for different food types. To address this problem, we propose a class-agnostic food image segmentation method. Our method uses a pair of eating scene images, one before start eating and one after eating is completed. Using information from both the before and after eating images, we can segment food images by finding the salient missing objects without any prior information about the food class. We model a paradigm of top down saliency which guides the attention of the human visual system (HVS) based on a task to find the salient missing objects in a pair of images. Our method is validated on food images collected from a dietary study which showed promising results.
Generative Autoregressive Ensembles for Satellite Imagery Manipulation Detection
Oct 08, 2020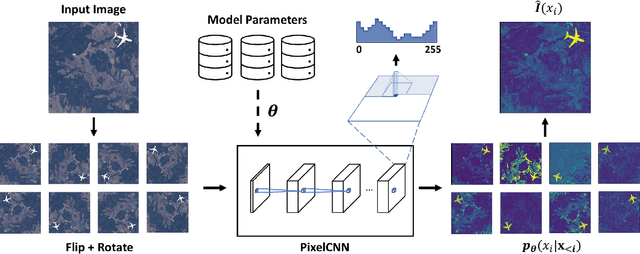

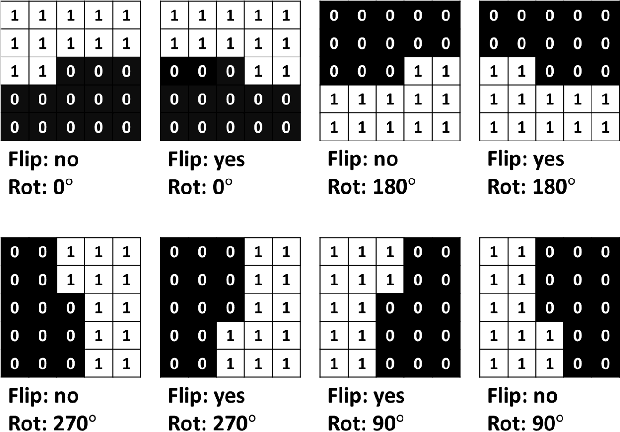
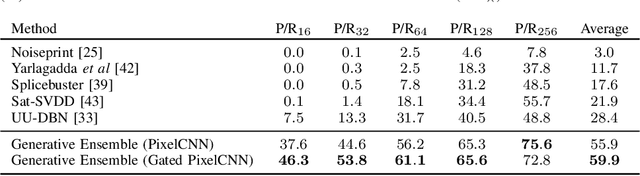
Satellite imagery is becoming increasingly accessible due to the growing number of orbiting commercial satellites. Many applications make use of such images: agricultural management, meteorological prediction, damage assessment from natural disasters, or cartography are some of the examples. Unfortunately, these images can be easily tampered and modified with image manipulation tools damaging downstream applications. Because the nature of the manipulation applied to the image is typically unknown, unsupervised methods that don't require prior knowledge of the tampering techniques used are preferred. In this paper, we use ensembles of generative autoregressive models to model the distribution of the pixels of the image in order to detect potential manipulations. We evaluate the performance of the presented approach obtaining accurate localization results compared to previously presented approaches.
Deepfakes Detection with Automatic Face Weighting
May 04, 2020

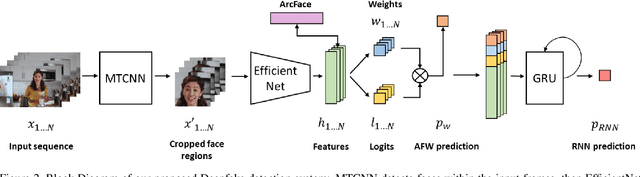

Altered and manipulated multimedia is increasingly present and widely distributed via social media platforms. Advanced video manipulation tools enable the generation of highly realistic-looking altered multimedia. While many methods have been presented to detect manipulations, most of them fail when evaluated with data outside of the datasets used in research environments. In order to address this problem, the Deepfake Detection Challenge (DFDC) provides a large dataset of videos containing realistic manipulations and an evaluation system that ensures that methods work quickly and accurately, even when faced with challenging data. In this paper, we introduce a method based on convolutional neural networks (CNNs) and recurrent neural networks (RNNs) that extracts visual and temporal features from faces present in videos to accurately detect manipulations. The method is evaluated with the DFDC dataset, providing competitive results compared to other techniques.
Multi-View Matching Network for 6D Pose Estimation
Nov 27, 2019
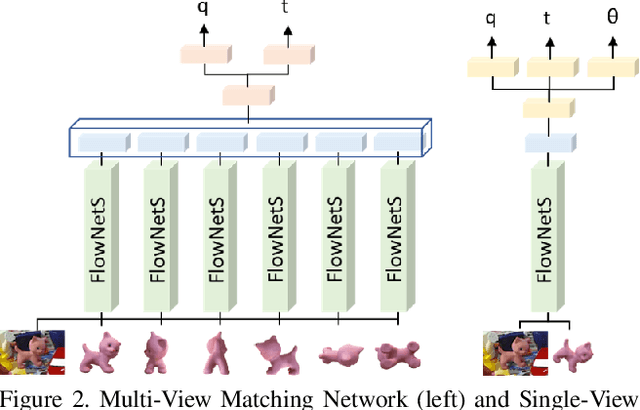

Applications that interact with the real world such as augmented reality or robot manipulation require a good understanding of the location and pose of the surrounding objects. In this paper, we present a new approach to estimate the 6 Degree of Freedom (DoF) or 6D pose of objects from a single RGB image. Our approach can be paired with an object detection and segmentation method to estimate, refine and track the pose of the objects by matching the input image with rendered images.
Class-Conditional VAE-GAN for Local-Ancestry Simulation
Nov 27, 2019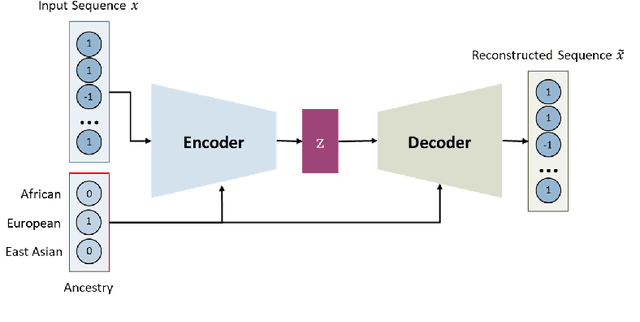

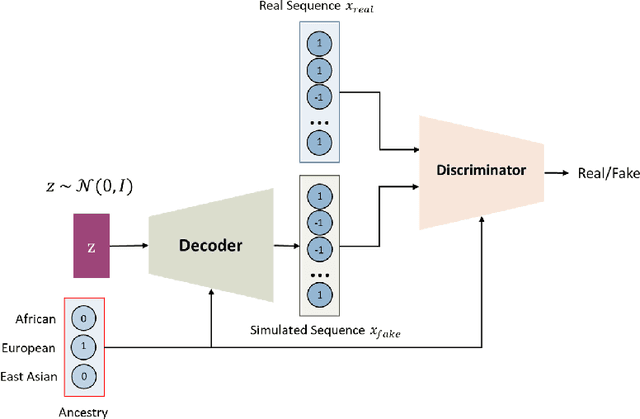
Local ancestry inference (LAI) allows identification of the ancestry of all chromosomal segments in admixed individuals, and it is a critical step in the analysis of human genomes with applications from pharmacogenomics and precision medicine to genome-wide association studies. In recent years, many LAI techniques have been developed in both industry and academic research. However, these methods require large training data sets of human genomic sequences from the ancestries of interest. Such reference data sets are usually limited, proprietary, protected by privacy restrictions, or otherwise not accessible to the public. Techniques to generate training samples that resemble real haploid sequences from ancestries of interest can be useful tools in such scenarios, since a generalized model can often be shared, but the unique human sample sequences cannot. In this work we present a class-conditional VAE-GAN to generate new human genomic sequences that can be used to train local ancestry inference (LAI) algorithms. We evaluate the quality of our generated data by comparing the performance of a state-of-the-art LAI method when trained with generated versus real data.