 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Color Image Analysis Tool to Help Users Choose a Makeup Foundation Color
Jul 08, 2024



This paper presents an approach to predict the color of skin-with-foundation based on a no makeup selfie image and a foundation shade image. Our approach first calibrates the image with the help of the color checker target, and then trains a supervised-learning model to predict the skin color. In the calibration stage, We propose to use three different transformation matrices to map the device dependent RGB response to the reference CIE XYZ space. In so doing, color correction error can be minimized. We then compute the average value of the region of interest in the calibrated images, and feed them to the prediction model. We explored both the linear regression and support vector regression models. Cross-validation results show that both models can accurately make the prediction.
Joint Multi-Scale Tone Mapping and Denoising for HDR Image Enhancement
Mar 23, 2023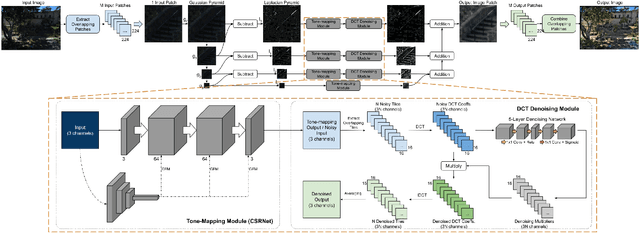
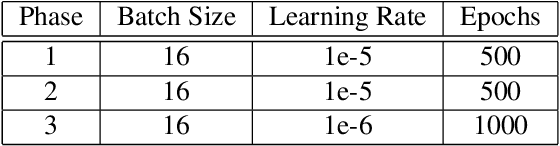

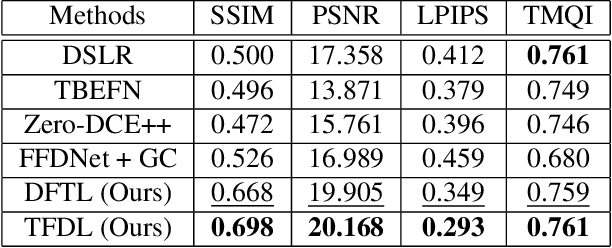
An image processing unit (IPU), or image signal processor (ISP) for high dynamic range (HDR) imaging usually consists of demosaicing, white balancing, lens shading correction, color correction, denoising, and tone-mapping. Besides noise from the imaging sensors, almost every step in the ISP introduces or amplifies noise in different ways, and denoising operators are designed to reduce the noise from these sources. Designed for dynamic range compressing, tone-mapping operators in an ISP can significantly amplify the noise level, especially for images captured in low-light conditions, making denoising very difficult. Therefore, we propose a joint multi-scale denoising and tone-mapping framework that is designed with both operations in mind for HDR images. Our joint network is trained in an end-to-end format that optimizes both operators together, to prevent the tone-mapping operator from overwhelming the denoising operator. Our model outperforms existing HDR denoising and tone-mapping operators both quantitatively and qualitatively on most of our benchmarking datasets.
Training a universal instance segmentation network for live cell images of various cell types and imaging modalities
Jul 28, 2022
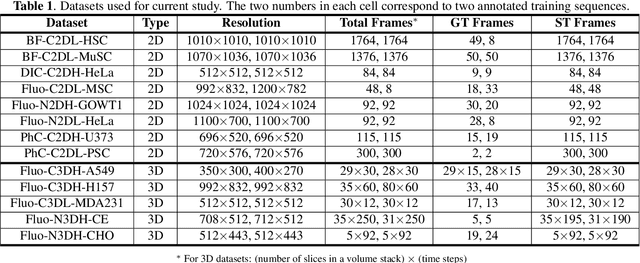

We share our recent findings in an attempt to train a universal segmentation network for various cell types and imaging modalities. Our method was built on the generalized U-Net architecture, which allows the evaluation of each component individually. We modified the traditional binary training targets to include three classes for direct instance segmentation. Detailed experiments were performed regarding training schemes, training settings, network backbones, and individual modules on the segmentation performance. Our proposed training scheme draws minibatches in turn from each dataset, and the gradients are accumulated before an optimization step. We found that the key to training a universal network is all-time supervision on all datasets, and it is necessary to sample each dataset in an unbiased way. Our experiments also suggest that there might exist common features to define cell boundaries across cell types and imaging modalities, which could allow application of trained models to totally unseen datasets. A few training tricks can further boost the segmentation performance, including uneven class weights in the cross-entropy loss function, well-designed learning rate scheduler, larger image crops for contextual information, and additional loss terms for unbalanced classes. We also found that segmentation performance can benefit from group normalization layer and Atrous Spatial Pyramid Pooling module, thanks to their more reliable statistics estimation and improved semantic understanding, respectively. We participated in the 6th Cell Tracking Challenge (CTC) held at IEEE International Symposium on Biomedical Imaging (ISBI) 2021 using one of the developed variants. Our method was evaluated as the best runner up during the initial submission for the primary track, and also secured the 3rd place in an additional round of competition in preparation for the summary publication.
Face Image Lighting Enhancement Using a 3D Model
Jul 02, 2022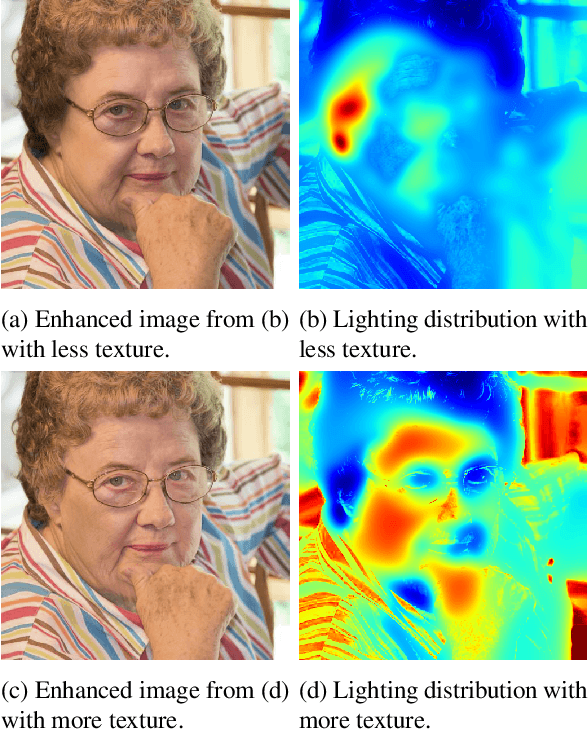
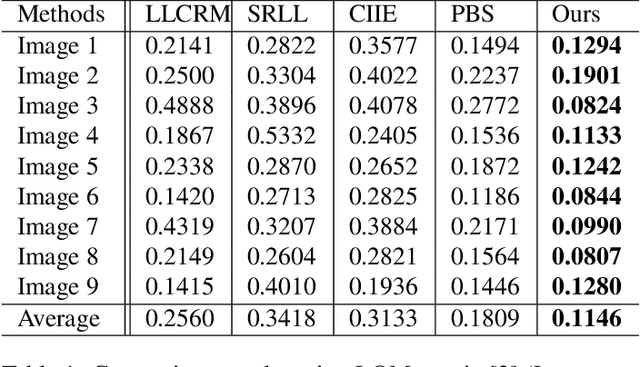
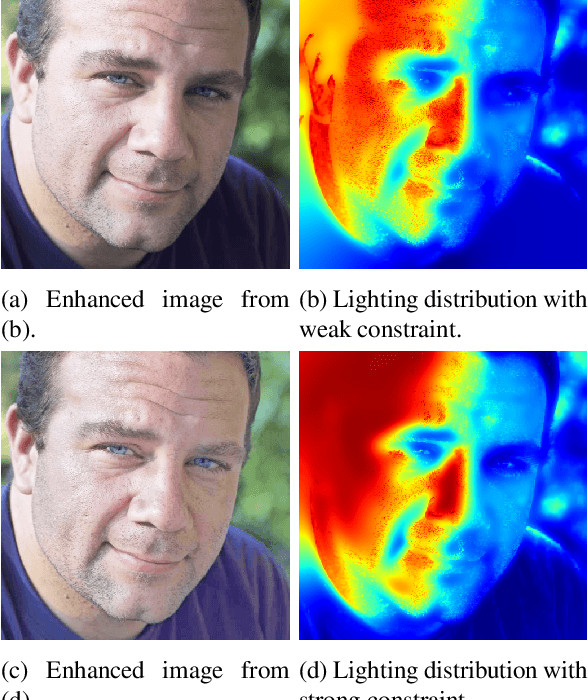
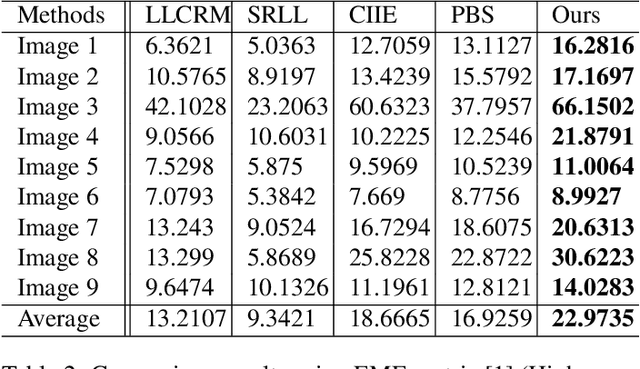
Image enhancement helps to generate balanced lighting distributions over faces. Our goal is to get an illuminance-balanced enhanced face image from a single view. Traditionally, image enhancement methods ignore the 3D geometry of the face or require a complicated multi-view geometry. Other methods cause color tone shifting or over saturation. Inspired by the new research achievements in face alignment and face 3D modeling, we propose an improved face image enhancement method by leveraging 3D face models. Given a face image as input, our method will first estimate its lighting distribution. Then we build an optimization process to refine the distribution. Finally, we generate an illuminance-balanced face image from a single view. Experiments on the FiveK dataset demonstrate that our method performs well and compares favorably with other methods.
Zooming SlowMo: An Efficient One-Stage Framework for Space-Time Video Super-Resolution
Apr 15, 2021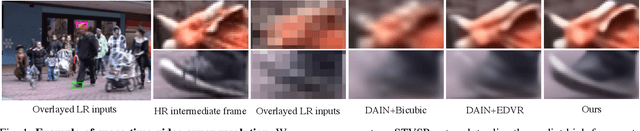



In this paper, we address the space-time video super-resolution, which aims at generating a high-resolution (HR) slow-motion video from a low-resolution (LR) and low frame rate (LFR) video sequence. A na\"ive method is to decompose it into two sub-tasks: video frame interpolation (VFI) and video super-resolution (VSR). Nevertheless, temporal interpolation and spatial upscaling are intra-related in this problem. Two-stage approaches cannot fully make use of this natural property. Besides, state-of-the-art VFI or VSR deep networks usually have a large frame reconstruction module in order to obtain high-quality photo-realistic video frames, which makes the two-stage approaches have large models and thus be relatively time-consuming. To overcome the issues, we present a one-stage space-time video super-resolution framework, which can directly reconstruct an HR slow-motion video sequence from an input LR and LFR video. Instead of reconstructing missing LR intermediate frames as VFI models do, we temporally interpolate LR frame features of the missing LR frames capturing local temporal contexts by a feature temporal interpolation module. Extensive experiments on widely used benchmarks demonstrate that the proposed framework not only achieves better qualitative and quantitative performance on both clean and noisy LR frames but also is several times faster than recent state-of-the-art two-stage networks. The source code is released in https://github.com/Mukosame/Zooming-Slow-Mo-CVPR-2020 .
Adversarial Open Domain Adaption for Sketch-to-Photo Synthesis
Apr 12, 2021



In this paper, we explore the open-domain sketch-to-photo translation, which aims to synthesize a realistic photo from a freehand sketch with its class label, even if the sketches of that class are missing in the training data. It is challenging due to the lack of training supervision and the large geometry distortion between the freehand sketch and photo domains. To synthesize the absent freehand sketches from photos, we propose a framework that jointly learns sketch-to-photo and photo-to-sketch generation. However, the generator trained from fake sketches might lead to unsatisfying results when dealing with sketches of missing classes, due to the domain gap between synthesized sketches and real ones. To alleviate this issue, we further propose a simple yet effective open-domain sampling and optimization strategy to "fool" the generator into treating fake sketches as real ones. Our method takes advantage of the learned sketch-to-photo and photo-to-sketch mapping of in-domain data and generalizes them to the open-domain classes. We validate our method on the Scribble and SketchyCOCO datasets. Compared with the recent competing methods, our approach shows impressive results in synthesizing realistic color, texture, and maintaining the geometric composition for various categories of open-domain sketches.
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Oct 18, 2020



Due to the limits of bandwidth and storage space, digital images are usually down-scaled and compressed when transmitted over networks, resulting in loss of details and jarring artifacts that can lower the performance of high-level visual tasks. In this paper, we aim to generate an artifact-free high-resolution image from a low-resolution one compressed with an arbitrary quality factor by exploring joint compression artifacts reduction (CAR) and super-resolution (SR) tasks. First, we propose a context-aware joint CAR and SR neural network (CAJNN) that integrates both local and non-local features to solve CAR and SR in one-stage. Finally, a deep reconstruction network is adopted to predict high quality and high-resolution images. Evaluation on CAR and SR benchmark datasets shows that our CAJNN model outperforms previous methods and also takes 26.2% shorter runtime. Based on this model, we explore addressing two critical challenges in high-level computer vision: optical character recognition of low-resolution texts, and extremely tiny face detection. We demonstrate that CAJNN can serve as an effective image preprocessing method and improve the accuracy for real-scene text recognition (from 85.30% to 85.75%) and the average precision for tiny face detection (from 0.317 to 0.611).
Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution
Feb 26, 2020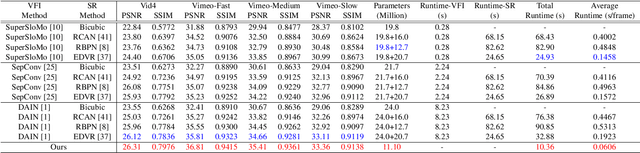
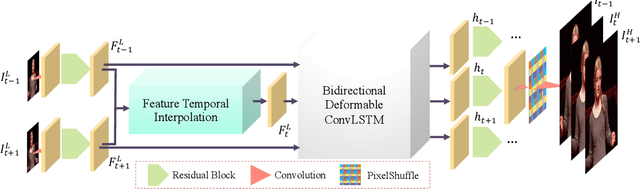

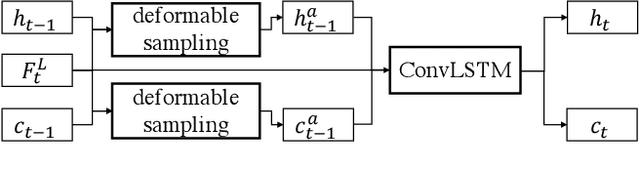
In this paper, we explore the space-time video super-resolution task, which aims to generate a high-resolution (HR) slow-motion video from a low frame rate (LFR), low-resolution (LR) video. A simple solution is to split it into two sub-tasks: video frame interpolation (VFI) and video super-resolution (VSR). However, temporal interpolation and spatial super-resolution are intra-related in this task. Two-stage methods cannot fully take advantage of the natural property. In addition, state-of-the-art VFI or VSR networks require a large frame-synthesis or reconstruction module for predicting high-quality video frames, which makes the two-stage methods have large model sizes and thus be time-consuming. To overcome the problems, we propose a one-stage space-time video super-resolution framework, which directly synthesizes an HR slow-motion video from an LFR, LR video. Rather than synthesizing missing LR video frames as VFI networks do, we firstly temporally interpolate LR frame features in missing LR video frames capturing local temporal contexts by the proposed feature temporal interpolation network. Then, we propose a deformable ConvLSTM to align and aggregate temporal information simultaneously for better leveraging global temporal contexts. Finally, a deep reconstruction network is adopted to predict HR slow-motion video frames. Extensive experiments on benchmark datasets demonstrate that the proposed method not only achieves better quantitative and qualitative performance but also is more than three times faster than recent two-stage state-of-the-art methods, e.g., DAIN+EDVR and DAIN+RBPN.
Multi-View Matching Network for 6D Pose Estimation
Nov 27, 2019
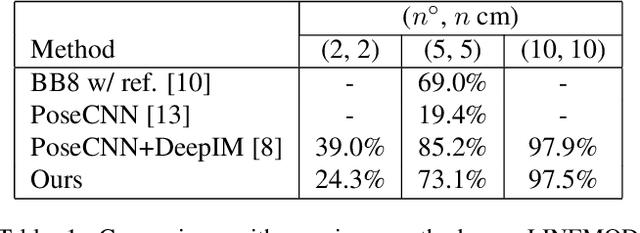
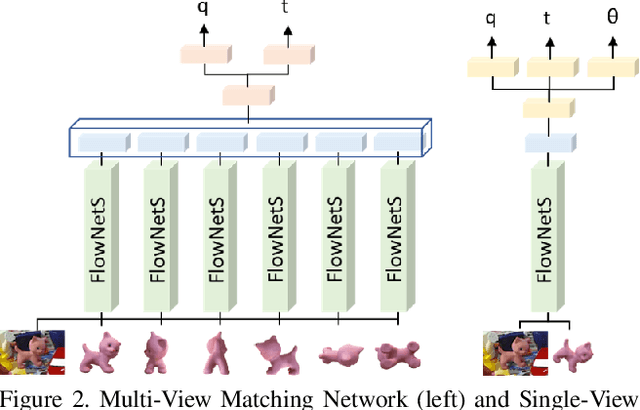

Applications that interact with the real world such as augmented reality or robot manipulation require a good understanding of the location and pose of the surrounding objects. In this paper, we present a new approach to estimate the 6 Degree of Freedom (DoF) or 6D pose of objects from a single RGB image. Our approach can be paired with an object detection and segmentation method to estimate, refine and track the pose of the objects by matching the input image with rendered images.
Model-based Iterative Restoration for Binary Document Image Compression with Dictionary Learning
Apr 24, 2017

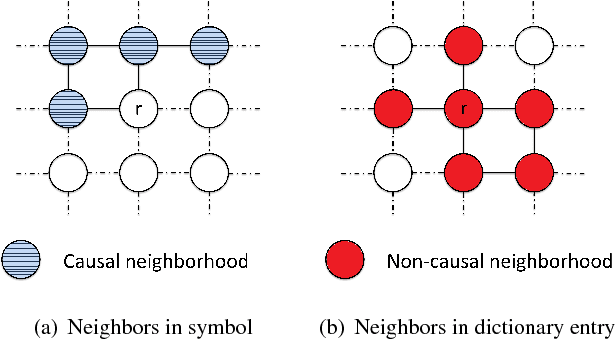
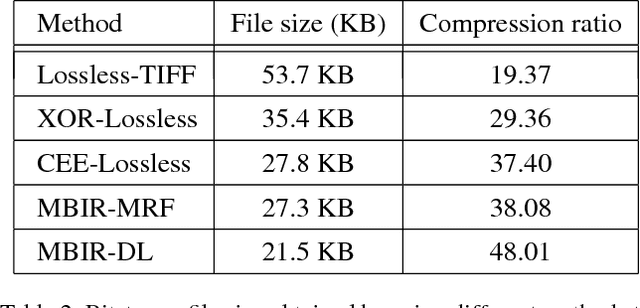
The inherent noise in the observed (e.g., scanned) binary document image degrades the image quality and harms the compression ratio through breaking the pattern repentance and adding entropy to the document images. In this paper, we design a cost function in Bayesian framework with dictionary learning. Minimizing our cost function produces a restored image which has better quality than that of the observed noisy image, and a dictionary for representing and encoding the image. After the restoration, we use this dictionary (from the same cost function) to encode the restored image following the symbol-dictionary framework by JBIG2 standard with the lossless mode. Experimental results with a variety of document images demonstrate that our method improves the image quality compared with the observed image, and simultaneously improves the compression ratio. For the test images with synthetic noise, our method reduces the number of flipped pixels by 48.2% and improves the compression ratio by 36.36% as compared with the best encoding methods. For the test images with real noise, our method visually improves the image quality, and outperforms the cutting-edge method by 28.27% in terms of the compression ratio.