 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReVAR: A Data-Driven Algorithm for Generating Aero-Optic Phase Screens
Apr 02, 2026The propagation of light through a turbulent flow field around an aircraft results in optical distortions commonly known as aero-optic effects. The development of methods to mitigate these effects requires large amounts of realistic aero-optic data. However, methods for obtaining this data, including experiment, computational fluid dynamics, and simple phase screen algorithms (e.g., boiling flow), each have significant drawbacks such as high cost, high computation, limited quantity, and/or inaccurate statistics. More recently, data-driven algorithms have been proposed that are computationally efficient and can synthesize aero-optic data to match the statistics of measured data, but these approaches still have drawbacks including limited quality, inaccurate statistics, and the use of complicated algorithms. In this paper, we introduce ReVAR (Re-whitened Vector AutoRegression), a data-driven algorithm for generating synthetic aero-optic data that matches the statistics of measured data. A key contribution in this algorithm is Long-Range AutoRegression, a linear predictive model that combines a standard autoregression with a set of low-pass filters of the data to fit both short-range and long-range temporal statistics. ReVAR uses Long-Range AR together with a spatial re-whitening step to convert measured aero-optic data to temporally and spatially un-correlated white noise. ReVAR can then generate synthetic aero-optic data by reversing this process using white noise input. Using two measured turbulent boundary layer data sets, we demonstrate that ReVAR better matches the measured data's temporal power spectrum and other key metrics than do two conventional phase screen generation methods and an existing single time-lag autoregressive model.
WindDensity-MBIR: Model-Based Iterative Reconstruction for Wind Tunnel 3D Density Estimation
Feb 18, 2026Experimentalists often use wind tunnels to study aerodynamic turbulence, but most wind tunnel imaging techniques are limited in their ability to take non-invasive 3D density measurements of turbulence. Wavefront tomography is a technique that uses multiple wavefront measurements from various viewing angles to non-invasively measure the 3D density field of a turbulent medium. Existing methods make strong assumptions, such as a spline basis representation, to address the ill-conditioned nature of this problem. We formulate this problem as a Bayesian, sparse-view tomographic reconstruction problem and develop a model-based iterative reconstruction algorithm for measuring the volumetric 3D density field inside a wind tunnel. We call this method WindDensity-MBIR and apply it using simulated data to difficult reconstruction scenarios with sparse data, small projection field of view, and limited angular extent. WindDensity-MBIR can recover high-order features in these scenarios within 10% to 25% error even when the tip, tilt, and piston are removed from the wavefront measurements.
Boiling flow parameter estimation from boundary layer data
Feb 11, 2026Atmospheric turbulence and aero-optic effects cause phase aberrations in propagating light waves, thereby reducing effectiveness in transmitting and receiving coherent light from an aircraft. Existing optical sensors can measure the resulting phase aberrations, but the physical experiments required to induce these aberrations are expensive and time-intensive. Simulation methods could provide a less expensive alternative. For example, an existing simulation algorithm called boiling flow, which generalizes the Taylor frozen-flow method, can generate synthetic phase aberration data (i.e., phase screens) induced by atmospheric turbulence. However, boiling flow depends on physical parameters, such as the Fried coherence length r0, which are not well-defined for aero-optic effects. In this paper, we introduce a method to estimate the parameters of boiling flow from measured aero-optic phase aberration data. Our algorithm estimates these parameters to fit the spatial and temporal statistics of the measured data. This method is computationally efficient and our experiments show that the temporal power spectral density of the slopes of the synthetic phase screens reasonably matches that of the measured phase aberrations from two turbulent boundary layer data sets, with errors between 8-9%. However, the Kolmogorov spatial structure function of the phase screens does not match that of the measured phase aberrations, with errors above 28%. This suggests that, while the parameters of boiling flow can reasonably fit the temporal statistics of highly convective data, they cannot fit the complex spatial statistics of aero-optic phase aberrations.
* Published in Proc. SPIE 13619, 136190L (2025). Version of record: https://doi.org/10.1117/12.3063655
Boiling flow estimation for aero-optic phase screen generation
Jan 17, 2026Aero-optic effects due to turbulence can reduce the effectiveness of transmitting light waves to a distant target. Methods to compensate for turbulence typically rely on realistic turbulence data, which can be generated by i) experiment, ii) high-fidelity CFD, iii) low-fidelity CFD, and iv) autoregressive methods. However, each of these methods has significant drawbacks, including monetary and/or computational expense, limited quantity, inaccurate statistics, and overall complexity. In contrast, the boiling flow algorithm is a simple, computationally efficient model that can generate atmospheric phase screen data with only a handful of parameters. However, boiling flow has not been widely used in aero-optic applications, at least in part because some of these parameters, such as r0, are not clearly defined for aero-optic data. In this paper, we demonstrate a method to use the boiling flow algorithm to generate arbitrary length synthetic data to match the statistics of measured aero-optic data. Importantly, we modify the standard boiling flow method to generate anisotropic phase screens. While this model does not fully capture all statistics, it can be used to generate data that matches the temporal power spectrum or the anisotropic 2D structure function, with the ability to trade fidelity to one for fidelity to the other.
MONSTR: Model-Oriented Neutron Strain Tomographic Reconstruction
May 28, 2025Residual strain, a tensor quantity, is a critical material property that impacts the overall performance of metal parts. Neutron Bragg edge strain tomography is a technique for imaging residual strain that works by making conventional hyperspectral computed tomography measurements, extracting the average projected strain at each detector pixel, and processing the resulting strain sinogram using a reconstruction algorithm. However, the reconstruction is severely ill-posed as the underlying inverse problem involves inferring a tensor at each voxel from scalar sinogram data. In this paper, we introduce the model-oriented neutron strain tomographic reconstruction (MONSTR) algorithm that reconstructs the 2D residual strain tensor from the neutron Bragg edge strain measurements. MONSTR is based on using the multi-agent consensus equilibrium framework for the tensor tomographic reconstruction. Specifically, we formulate the reconstruction as a consensus solution of a collection of agents representing detector physics, the tomographic reconstruction process, and physics-based constraints from continuum mechanics. Using simulated data, we demonstrate high-quality reconstruction of the strain tensor even when using very few measurements.
Ptychography using Blind Multi-Mode PMACE
Jan 11, 2025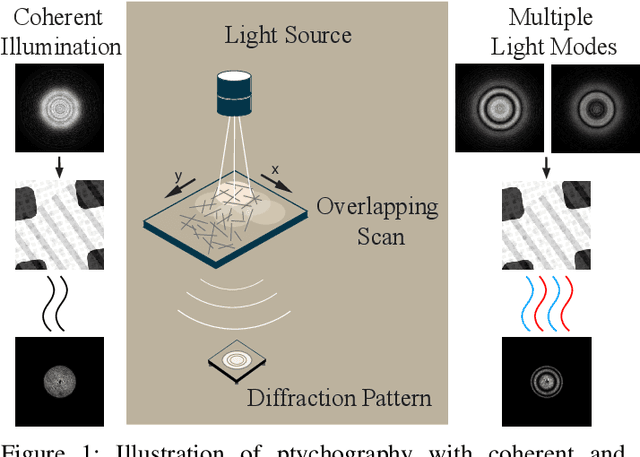
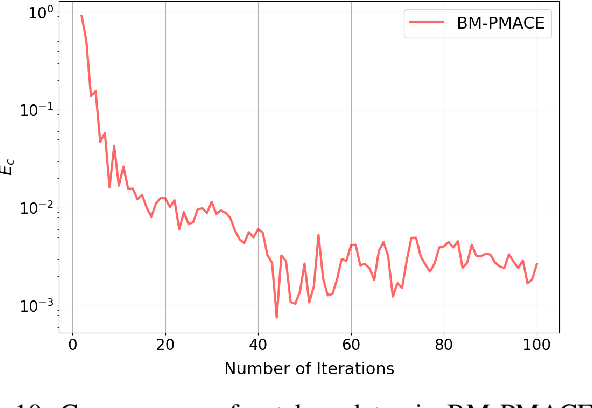
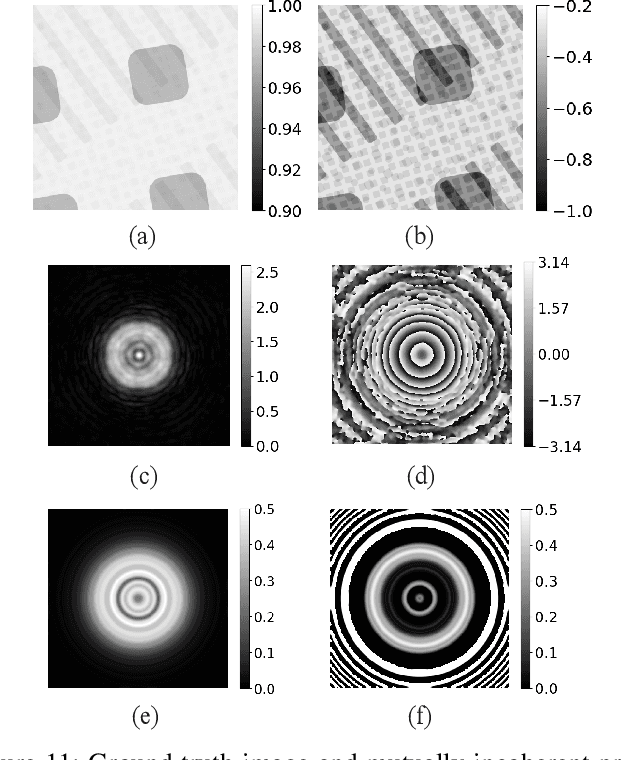

Ptychography is an imaging technique that enables nanometer-scale reconstruction of complex transmittance images by scanning objects with overlapping illumination patterns. However, the illumination function is typically unknown, which presents challenges for reconstruction, especially when using partially coherent light sources. In this paper, we introduce Blind Multi-Mode Projected Multi-Agent Consensus Equilibrium (BM-PMACE) for blind ptychographic reconstruction. We extend the PMACE framework for distributed inverse problems to jointly estimate the complex transmittance image and multiple, unknown, partially coherent probe functions. Importantly, our method maintains local probe estimates to exploit complementary information at multiple probe locations. Our method also incorporates a dynamic strategy for integrating additional probe modes. Through experimental simulations and validations using both synthetic and measured data, we demonstrate that BM-PMACE outperforms existing approaches in reconstruction quality and convergence rate.
Fast Hyperspectral Neutron Tomography
Oct 29, 2024Hyperspectral neutron computed tomography is a tomographic imaging technique in which thousands of wavelength-specific neutron radiographs are typically measured for each tomographic view. In conventional hyperspectral reconstruction, data from each neutron wavelength bin is reconstructed separately, which is extremely time-consuming. These reconstructions often suffer from poor quality due to low signal-to-noise ratio. Consequently, material decomposition based on these reconstructions tends to lead to both inaccurate estimates of the material spectra and inaccurate volumetric material separation. In this paper, we present two novel algorithms for processing hyperspectral neutron data: fast hyperspectral reconstruction and fast material decomposition. Both algorithms rely on a subspace decomposition procedure that transforms hyperspectral views into low-dimensional projection views within an intermediate subspace, where tomographic reconstruction is performed. The use of subspace decomposition dramatically reduces reconstruction time while reducing both noise and reconstruction artifacts. We apply our algorithms to both simulated and measured neutron data and demonstrate that they reduce computation and improve the quality of the results relative to conventional methods.
ResSR: A Residual Approach to Super-Resolving Multispectral Images
Aug 23, 2024

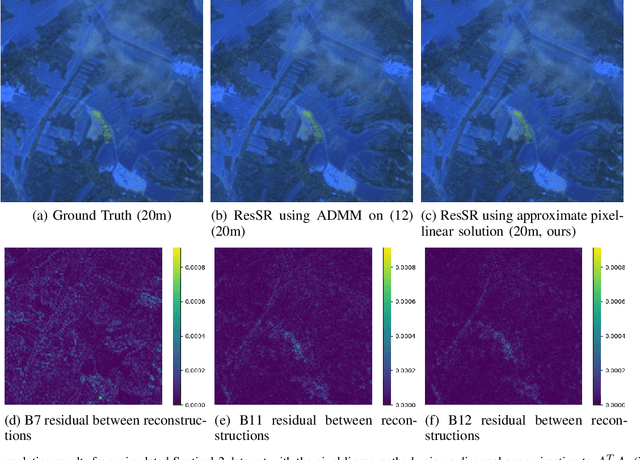

Multispectral imaging sensors typically have wavelength-dependent resolution, which reduces the ability to distinguish small features in some spectral bands. Existing super-resolution methods upsample a multispectral image (MSI) to achieve a common resolution across all bands but are typically sensor-specific, computationally expensive, and may assume invariant image statistics across multiple length scales. In this paper, we introduce ResSR, an efficient and modular residual-based method for super-resolving the lower-resolution bands of a multispectral image. ResSR uses singular value decomposition (SVD) to identify correlations across spectral bands and then applies a residual correction process that corrects only the high-spatial frequency components of the upsampled bands. The SVD formulation improves the conditioning and simplifies the super-resolution problem, and the residual method retains accurate low-spatial frequencies from the measured data while incorporating high-spatial frequency detail from the SVD solution. While ResSR is formulated as the solution to an optimization problem, we derive an approximate closed-form solution that is fast and accurate. We formulate ResSR for any number of distinct resolutions, enabling easy application to any MSI. In a series of experiments on simulated and measured Sentinel-2 MSIs, ResSR is shown to produce image quality comparable to or better than alternative algorithms. However, it is computationally faster and can run on larger images, making it useful for processing large data sets.
Pixel-weighted Multi-pose Fusion for Metal Artifact Reduction in X-ray Computed Tomography
Jun 25, 2024X-ray computed tomography (CT) reconstructs the internal morphology of a three dimensional object from a collection of projection images, most commonly using a single rotation axis. However, for objects containing dense materials like metal, the use of a single rotation axis may leave some regions of the object obscured by the metal, even though projections from other rotation axes (or poses) might contain complementary information that would better resolve these obscured regions. In this paper, we propose pixel-weighted Multi-pose Fusion to reduce metal artifacts by fusing the information from complementary measurement poses into a single reconstruction. Our method uses Multi-Agent Consensus Equilibrium (MACE), an extension of Plug-and-Play, as a framework for integrating projection data from different poses. A primary novelty of the proposed method is that the output of different MACE agents are fused in a pixel-weighted manner to minimize the effects of metal throughout the reconstruction. Using real CT data on an object with and without metal inserts, we demonstrate that the proposed pixel-weighted Multi-pose Fusion method significantly reduces metal artifacts relative to single-pose reconstructions.
CLAMP: Majorized Plug-and-Play for Coherent 3D LIDAR Imaging
Jun 19, 2024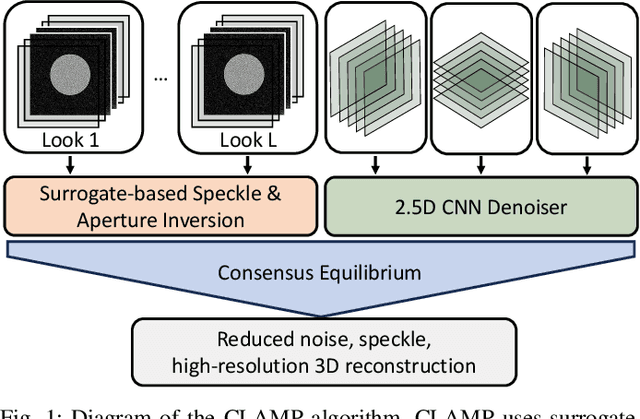
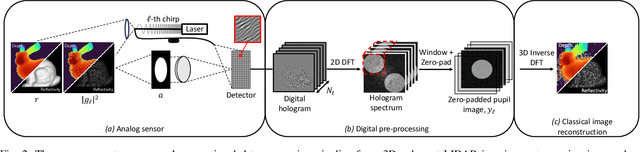

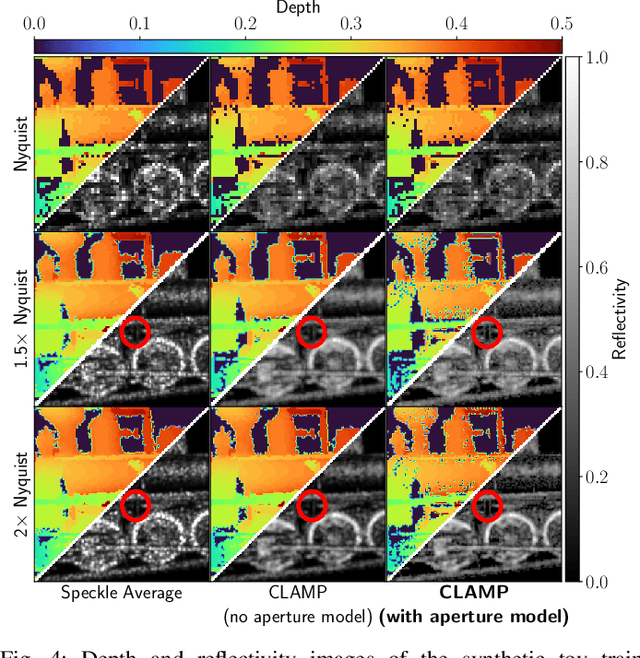
Coherent LIDAR uses a chirped laser pulse for 3D imaging of distant targets. However, existing coherent LIDAR image reconstruction methods do not account for the system's aperture, resulting in sub-optimal resolution. Moreover, these methods use majorization-minimization for computational efficiency, but do so without a theoretical treatment of convergence. In this paper, we present Coherent LIDAR Aperture Modeled Plug-and-Play (CLAMP) for multi-look coherent LIDAR image reconstruction. CLAMP uses multi-agent consensus equilibrium (a form of PnP) to combine a neural network denoiser with an accurate physics-based forward model. CLAMP introduces an FFT-based method to account for the effects of the aperture and uses majorization of the forward model for computational efficiency. We also formalize the use of majorization-minimization in consensus optimization problems and prove convergence to the exact consensus equilibrium solution. Finally, we apply CLAMP to synthetic and measured data to demonstrate its effectiveness in producing high-resolution, speckle-free, 3D imagery.