 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing INR with diffusion prior self-supervised 3D reconstruction of neutron computed tomography data
Mar 11, 2026Recently, generative diffusion priors have made huge strides as inverse problem solvers, including the ability to be adapted for inference on out-of-distribution data. Concurrently, implicit neural representations (INRs) have emerged as fast and lightweight inverse imaging solvers that are amenable to hybrid approaches that combine learned priors with traditional inverse problem formulations. In this paper, we present a diffusive computed tomography (CT) inversion framework for regularizing INRs called Diffusive INR (DINR), designed to enable high-quality reconstruction from sparse-view neutron CT. Pretrained purely on synthetic data, DINR is evaluated on simulated and experimentally obtained observations of concrete microstructures, where traditional reconstruction methods suffer substantial degradation when the number of views is reduced. Our approach delivers superior performance, reduces reconstruction artifacts, and achieves gains in PSNR and SSIM, enabling accurate micro-structural characterization even under extreme data limitations compared to state-of-the-art sparse-view reconstruction techniques.
Cross-Modal Guidance for Fast Diffusion-Based Computed Tomography
Mar 01, 2026Diffusion models have emerged as powerful priors for solving inverse problems in computed tomography (CT). In certain applications, such as neutron CT, it can be expensive to collect large amounts of measurements even for a single scan, leading to sparse data sets from which it is challenging to obtain high quality reconstructions even with diffusion models. One strategy to mitigate this challenge is to leverage a complementary, easily available imaging modality; however, such approaches typically require retraining the diffusion model with large datasets. In this work, we propose incorporating an additional modality without retraining the diffusion prior, enabling accelerated imaging of costly modalities. We further examine the impact of imperfect side modalities on cross-modal guidance. Our method is evaluated on sparse-view neutron computed tomography, where reconstruction quality is substantially improved by incorporating X-ray computed tomography of the same samples.
The Double-Edged Sword of Data-Driven Super-Resolution: Adversarial Super-Resolution Models
Feb 06, 2026Data-driven super-resolution (SR) methods are often integrated into imaging pipelines as preprocessing steps to improve downstream tasks such as classification and detection. However, these SR models introduce a previously unexplored attack surface into imaging pipelines. In this paper, we present AdvSR, a framework demonstrating that adversarial behavior can be embedded directly into SR model weights during training, requiring no access to inputs at inference time. Unlike prior attacks that perturb inputs or rely on backdoor triggers, AdvSR operates entirely at the model level. By jointly optimizing for reconstruction quality and targeted adversarial outcomes, AdvSR produces models that appear benign under standard image quality metrics while inducing downstream misclassification. We evaluate AdvSR on three SR architectures (SRCNN, EDSR, SwinIR) paired with a YOLOv11 classifier and demonstrate that AdvSR models can achieve high attack success rates with minimal quality degradation. These findings highlight a new model-level threat for imaging pipelines, with implications for how practitioners source and validate models in safety-critical applications.
Plug-and-Play with 2.5D Artifact Reduction Prior for Fast and Accurate Industrial Computed Tomography Reconstruction
Jun 17, 2025Cone-beam X-ray computed tomography (XCT) is an essential imaging technique for generating 3D reconstructions of internal structures, with applications ranging from medical to industrial imaging. Producing high-quality reconstructions typically requires many X-ray measurements; this process can be slow and expensive, especially for dense materials. Recent work incorporating artifact reduction priors within a plug-and-play (PnP) reconstruction framework has shown promising results in improving image quality from sparse-view XCT scans while enhancing the generalizability of deep learning-based solutions. However, this method uses a 2D convolutional neural network (CNN) for artifact reduction, which captures only slice-independent information from the 3D reconstruction, limiting performance. In this paper, we propose a PnP reconstruction method that uses a 2.5D artifact reduction CNN as the prior. This approach leverages inter-slice information from adjacent slices, capturing richer spatial context while remaining computationally efficient. We show that this 2.5D prior not only improves the quality of reconstructions but also enables the model to directly suppress commonly occurring XCT artifacts (such as beam hardening), eliminating the need for artifact correction pre-processing. Experiments on both experimental and synthetic cone-beam XCT data demonstrate that the proposed method better preserves fine structural details, such as pore size and shape, leading to more accurate defect detection compared to 2D priors. In particular, we demonstrate strong performance on experimental XCT data using a 2.5D artifact reduction prior trained entirely on simulated scans, highlighting the proposed method's ability to generalize across domains.
2.5D Super-Resolution Approaches for X-ray Computed Tomography-based Inspection of Additively Manufactured Parts
Dec 05, 2024



X-ray computed tomography (XCT) is a key tool in non-destructive evaluation of additively manufactured (AM) parts, allowing for internal inspection and defect detection. Despite its widespread use, obtaining high-resolution CT scans can be extremely time consuming. This issue can be mitigated by performing scans at lower resolutions; however, reducing the resolution compromises spatial detail, limiting the accuracy of defect detection. Super-resolution algorithms offer a promising solution for overcoming resolution limitations in XCT reconstructions of AM parts, enabling more accurate detection of defects. While 2D super-resolution methods have demonstrated state-of-the-art performance on natural images, they tend to under-perform when directly applied to XCT slices. On the other hand, 3D super-resolution methods are computationally expensive, making them infeasible for large-scale applications. To address these challenges, we propose a 2.5D super-resolution approach tailored for XCT of AM parts. Our method enhances the resolution of individual slices by leveraging multi-slice information from neighboring 2D slices without the significant computational overhead of full 3D methods. Specifically, we use neighboring low-resolution slices to super-resolve the center slice, exploiting inter-slice spatial context while maintaining computational efficiency. This approach bridges the gap between 2D and 3D methods, offering a practical solution for high-throughput defect detection in AM parts.
ResSR: A Residual Approach to Super-Resolving Multispectral Images
Aug 23, 2024

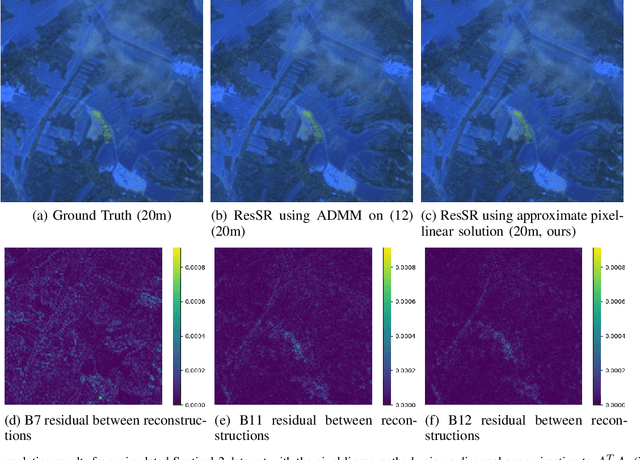

Multispectral imaging sensors typically have wavelength-dependent resolution, which reduces the ability to distinguish small features in some spectral bands. Existing super-resolution methods upsample a multispectral image (MSI) to achieve a common resolution across all bands but are typically sensor-specific, computationally expensive, and may assume invariant image statistics across multiple length scales. In this paper, we introduce ResSR, an efficient and modular residual-based method for super-resolving the lower-resolution bands of a multispectral image. ResSR uses singular value decomposition (SVD) to identify correlations across spectral bands and then applies a residual correction process that corrects only the high-spatial frequency components of the upsampled bands. The SVD formulation improves the conditioning and simplifies the super-resolution problem, and the residual method retains accurate low-spatial frequencies from the measured data while incorporating high-spatial frequency detail from the SVD solution. While ResSR is formulated as the solution to an optimization problem, we derive an approximate closed-form solution that is fast and accurate. We formulate ResSR for any number of distinct resolutions, enabling easy application to any MSI. In a series of experiments on simulated and measured Sentinel-2 MSIs, ResSR is shown to produce image quality comparable to or better than alternative algorithms. However, it is computationally faster and can run on larger images, making it useful for processing large data sets.