 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-Play with 2.5D Artifact Reduction Prior for Fast and Accurate Industrial Computed Tomography Reconstruction
Jun 17, 2025Cone-beam X-ray computed tomography (XCT) is an essential imaging technique for generating 3D reconstructions of internal structures, with applications ranging from medical to industrial imaging. Producing high-quality reconstructions typically requires many X-ray measurements; this process can be slow and expensive, especially for dense materials. Recent work incorporating artifact reduction priors within a plug-and-play (PnP) reconstruction framework has shown promising results in improving image quality from sparse-view XCT scans while enhancing the generalizability of deep learning-based solutions. However, this method uses a 2D convolutional neural network (CNN) for artifact reduction, which captures only slice-independent information from the 3D reconstruction, limiting performance. In this paper, we propose a PnP reconstruction method that uses a 2.5D artifact reduction CNN as the prior. This approach leverages inter-slice information from adjacent slices, capturing richer spatial context while remaining computationally efficient. We show that this 2.5D prior not only improves the quality of reconstructions but also enables the model to directly suppress commonly occurring XCT artifacts (such as beam hardening), eliminating the need for artifact correction pre-processing. Experiments on both experimental and synthetic cone-beam XCT data demonstrate that the proposed method better preserves fine structural details, such as pore size and shape, leading to more accurate defect detection compared to 2D priors. In particular, we demonstrate strong performance on experimental XCT data using a 2.5D artifact reduction prior trained entirely on simulated scans, highlighting the proposed method's ability to generalize across domains.
Adapting model-based deep learning to multiple acquisition conditions: Ada-MoDL
Apr 21, 2023Purpose: The aim of this work is to introduce a single model-based deep network that can provide high-quality reconstructions from undersampled parallel MRI data acquired with multiple sequences, acquisition settings and field strengths. Methods: A single unrolled architecture, which offers good reconstructions for multiple acquisition settings, is introduced. The proposed scheme adapts the model to each setting by scaling the CNN features and the regularization parameter with appropriate weights. The scaling weights and regularization parameter are derived using a multi-layer perceptron model from conditional vectors, which represents the specific acquisition setting. The perceptron parameters and the CNN weights are jointly trained using data from multiple acquisition settings, including differences in field strengths, acceleration, and contrasts. The conditional network is validated using datasets acquired with different acquisition settings. Results: The comparison of the adaptive framework, which trains a single model using the data from all the settings, shows that it can offer consistently improved performance for each acquisition condition. The comparison of the proposed scheme with networks that are trained independently for each acquisition setting shows that it requires less training data per acquisition setting to offer good performance. Conclusion: The Ada-MoDL framework enables the use of a single model-based unrolled network for multiple acquisition settings. In addition to eliminating the need to train and store multiple networks for different acquisition settings, this approach reduces the training data needed for each acquisition setting.
Accelerated parallel MRI using memory efficient and robust monotone operator learning (MOL)
Apr 03, 2023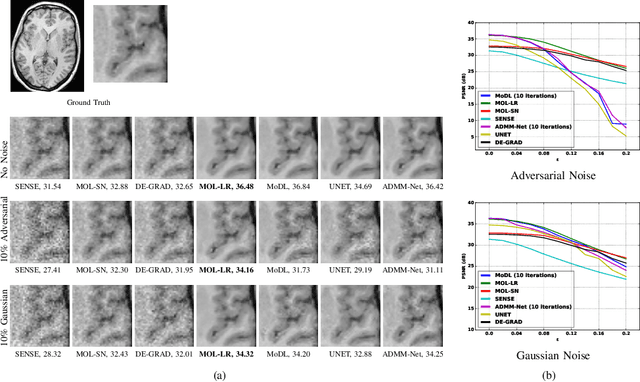
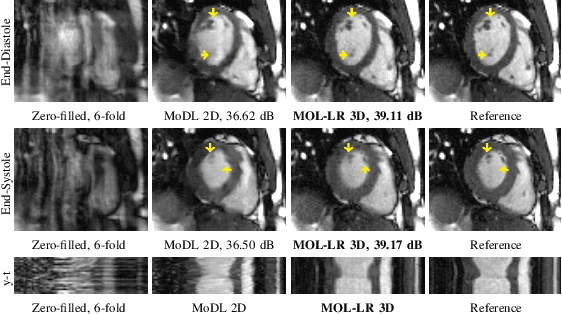
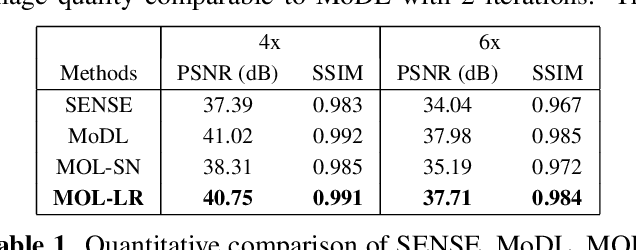
Model-based deep learning methods that combine imaging physics with learned regularization priors have been emerging as powerful tools for parallel MRI acceleration. The main focus of this paper is to determine the utility of the monotone operator learning (MOL) framework in the parallel MRI setting. The MOL algorithm alternates between a gradient descent step using a monotone convolutional neural network (CNN) and a conjugate gradient algorithm to encourage data consistency. The benefits of this approach include similar guarantees as compressive sensing algorithms including uniqueness, convergence, and stability, while being significantly more memory efficient than unrolled methods. We validate the proposed scheme by comparing it with different unrolled algorithms in the context of accelerated parallel MRI for static and dynamic settings.
Improved Model based Deep Learning using Monotone Operator Learning (MOL)
Nov 22, 2021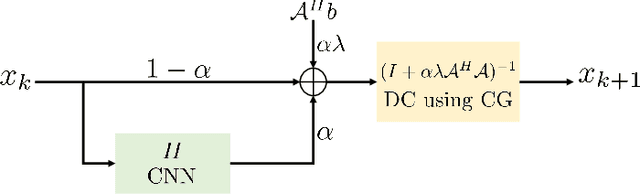
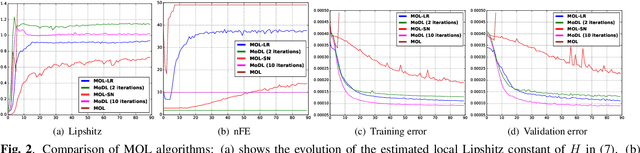
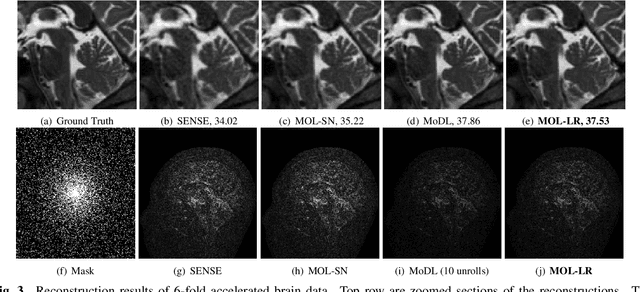
Model-based deep learning (MoDL) algorithms that rely on unrolling are emerging as powerful tools for image recovery. In this work, we introduce a novel monotone operator learning framework to overcome some of the challenges associated with current unrolled frameworks, including high memory cost, lack of guarantees on robustness to perturbations, and low interpretability. Unlike current unrolled architectures that use finite number of iterations, we use the deep equilibrium (DEQ) framework to iterate the algorithm to convergence and to evaluate the gradient of the convolutional neural network blocks using Jacobian iterations. This approach significantly reduces the memory demand, facilitating the extension of MoDL algorithms to high dimensional problems. We constrain the CNN to be a monotone operator, which allows us to introduce algorithms with guaranteed convergence properties and robustness guarantees. We demonstrate the utility of the proposed scheme in the context of parallel MRI.
Joint Calibrationless Reconstruction and Segmentation of Parallel MRI
May 19, 2021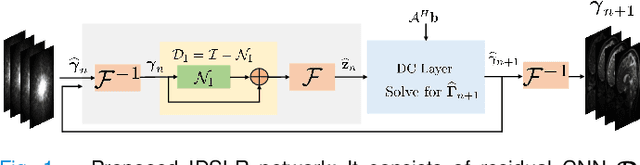
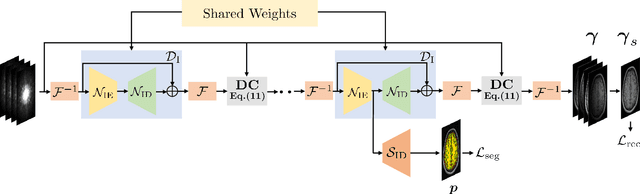
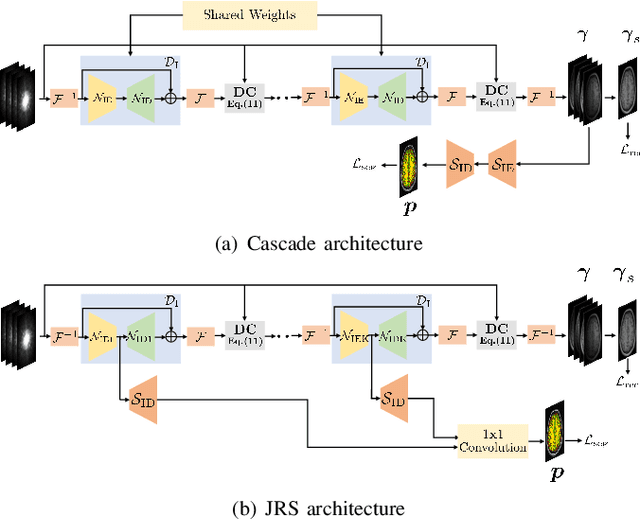
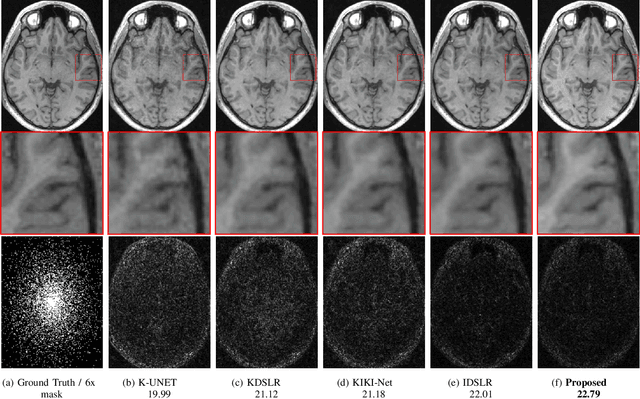
The volume estimation of brain regions from MRI data is a key problem in many clinical applications, where the acquisition of data at high spatial resolution is desirable. While parallel MRI and constrained image reconstruction algorithms can accelerate the scans, image reconstruction artifacts are inevitable, especially at high acceleration factors. We introduce a novel image domain deep-learning framework for calibrationless parallel MRI reconstruction, coupled with a segmentation network to improve image quality and to reduce the vulnerability of current segmentation algorithms to image artifacts resulting from acceleration. The combination of the proposed image domain deep calibrationless approach with the segmentation algorithm offers improved image quality, while increasing the accuracy of the segmentations. The novel architecture with an encoder shared between the reconstruction and segmentation tasks is seen to reduce the need for segmented training datasets. In particular, the proposed few-shot training strategy requires only 10% of segmented datasets to offer good performance.
Reconstruction and Segmentation of Parallel MR Data using Image Domain DEEP-SLR
Feb 01, 2021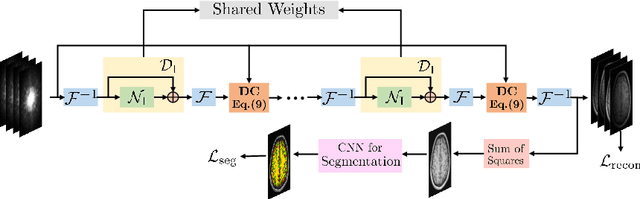
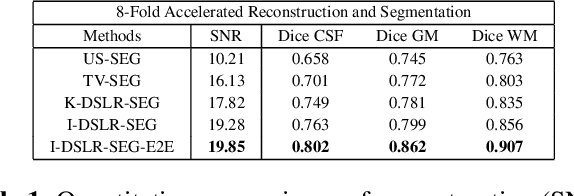
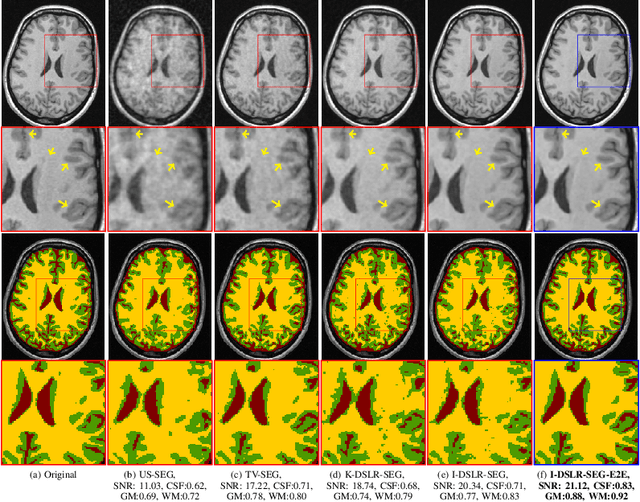
The main focus of this work is a novel framework for the joint reconstruction and segmentation of parallel MRI (PMRI) brain data. We introduce an image domain deep network for calibrationless recovery of undersampled PMRI data. The proposed approach is the deep-learning (DL) based generalization of local low-rank based approaches for uncalibrated PMRI recovery including CLEAR [6]. Since the image domain approach exploits additional annihilation relations compared to k-space based approaches, we expect it to offer improved performance. To minimize segmentation errors resulting from undersampling artifacts, we combined the proposed scheme with a segmentation network and trained it in an end-to-end fashion. In addition to reducing segmentation errors, this approach also offers improved reconstruction performance by reducing overfitting; the reconstructed images exhibit reduced blurring and sharper edges than independently trained reconstruction network.
Calibrationless Parallel MRI using Model based Deep Learning (C-MODL)
Jan 21, 2020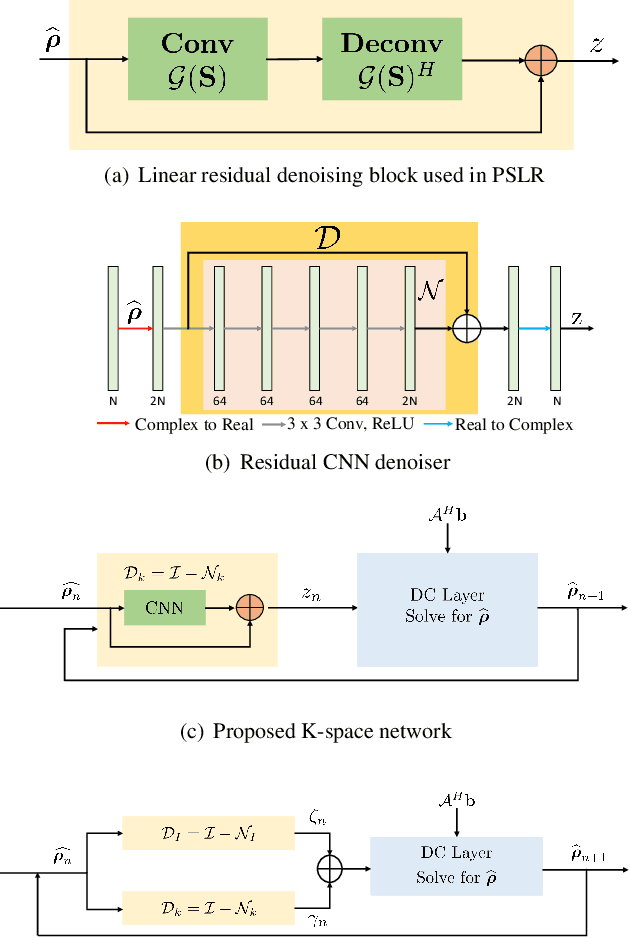
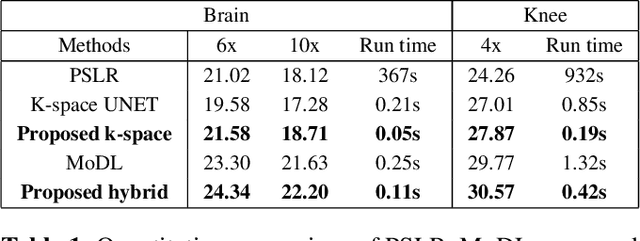
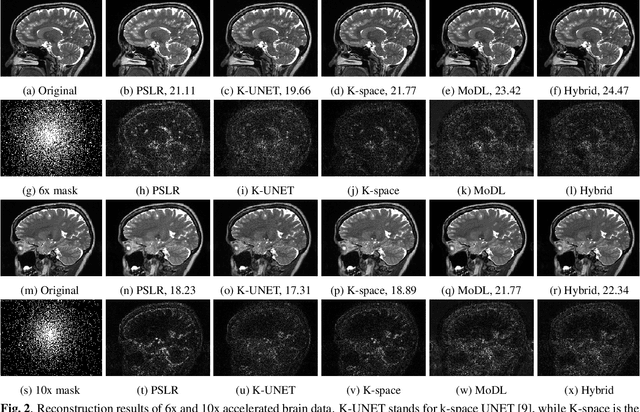
We introduce a fast model based deep learning approach for calibrationless parallel MRI reconstruction. The proposed scheme is a non-linear generalization of structured low rank (SLR) methods that self learn linear annihilation filters from the same subject. It pre-learns non-linear annihilation relations in the Fourier domain from exemplar data. The pre-learning strategy significantly reduces the computational complexity, making the proposed scheme three orders of magnitude faster than SLR schemes. The proposed framework also allows the use of a complementary spatial domain prior; the hybrid regularization scheme offers improved performance over calibrated image domain MoDL approach. The calibrationless strategy minimizes potential mismatches between calibration data and the main scan, while eliminating the need for a fully sampled calibration region.
Deep Generalization of Structured Low Rank Algorithms (Deep-SLR)
Dec 07, 2019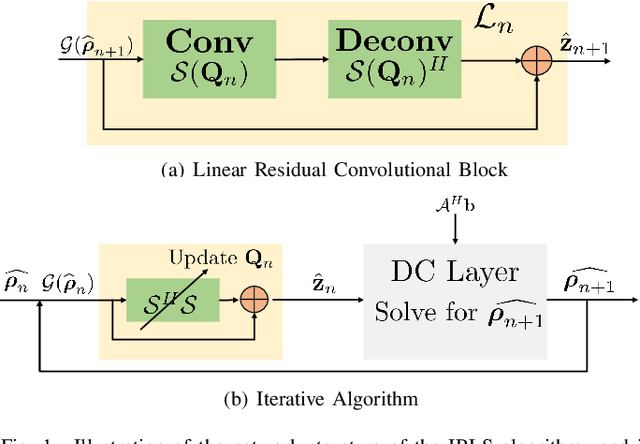
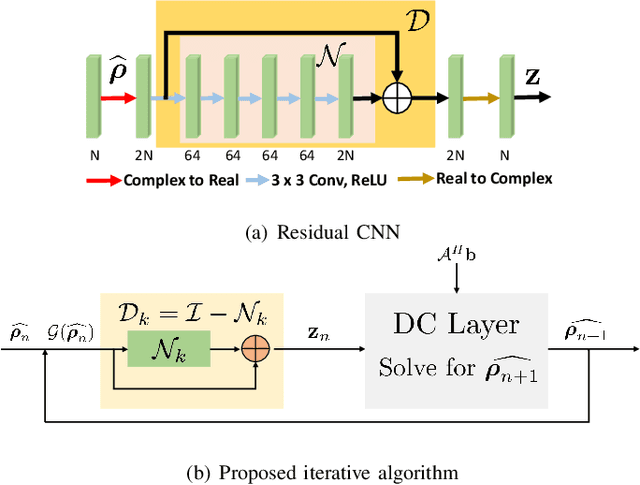
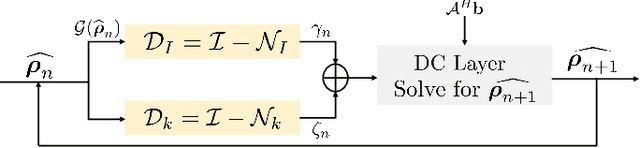
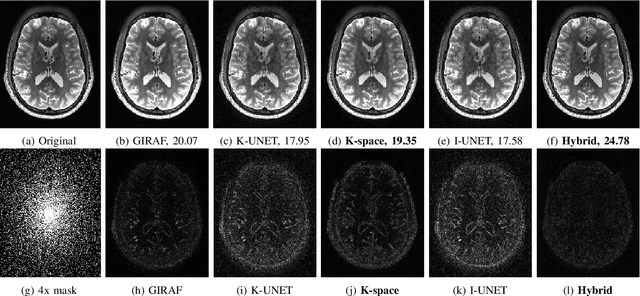
Structured low-rank (SLR) algorithms are emerging as powerful image reconstruction approaches because they can capitalize on several signal properties, which conventional image-based approaches have difficulty in exploiting. The main challenge with this scheme that self learns an annihilation convolutional filterbank from the undersampled data is its high computational complexity. We introduce a deep-learning approach to quite significantly reduce the computational complexity of SLR schemes. Specifically, we pre-learn a CNN-based annihilation filterbank from exemplar data, which is used as a prior in a model-based reconstruction scheme. The CNN parameters are learned in an end-to-end fashion by un-rolling the iterative algorithm. The main difference of the proposed scheme with current model-based deep learning strategies is the learning of non-linear annihilation relations in Fourier space using a modelbased framework. The experimental comparisons show that the proposed scheme can offer similar performance as SLR schemes in the calibrationless parallel MRI setting, while reducing the run-time by around three orders of magnitude. We also combine the proposed scheme with image domain priors, which are complementary, thus further improving the performance over SLR schemes.
Off-the-grid model based deep learning
Dec 27, 2018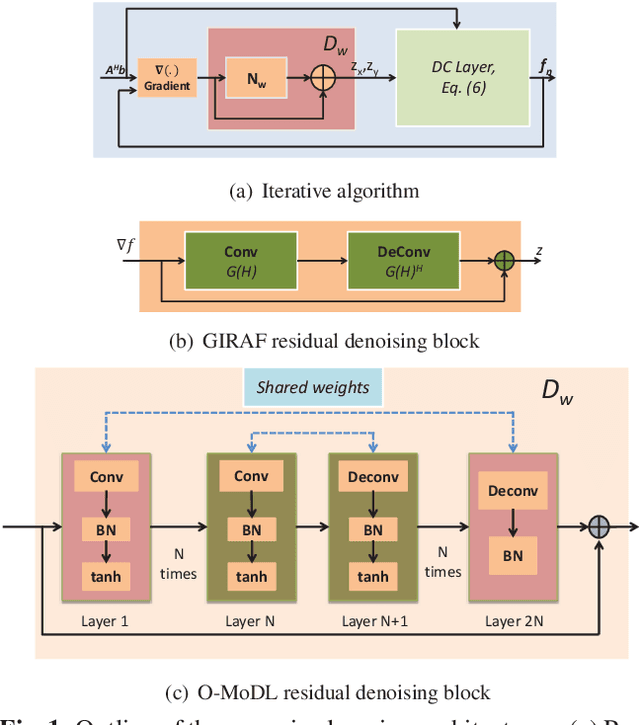
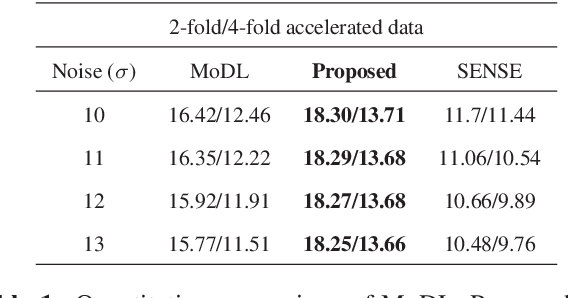
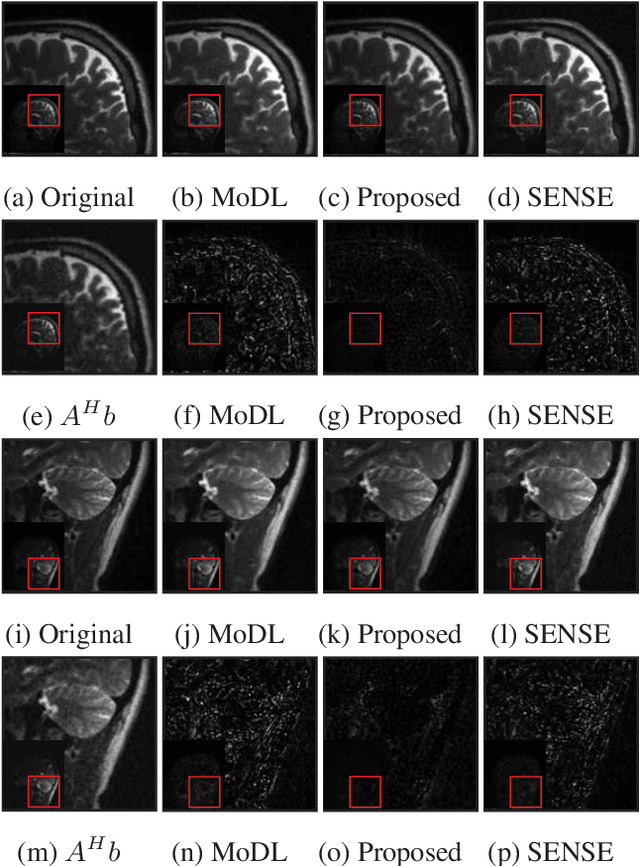
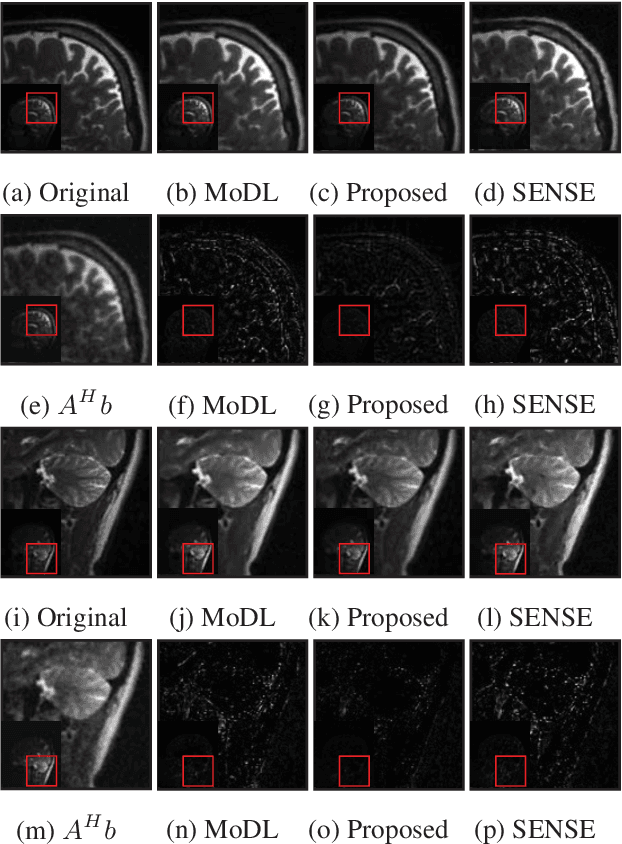
We introduce a model based off-the-grid image reconstruction algorithm using deep learned priors. The main difference of the proposed scheme with current deep learning strategies is the learning of non-linear annihilation relations in Fourier space. We rely on a model based framework, which allows us to use a significantly smaller deep network, compared to direct approaches that also learn how to invert the forward model. Preliminary comparisons against image domain MoDL approach demonstrates the potential of the off-the-grid formulation. The main benefit of the proposed scheme compared to structured low-rank methods is the quite significant reduction in computational complexity.