 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated parallel MRI using memory efficient and robust monotone operator learning (MOL)
Paper and Code
Apr 03, 2023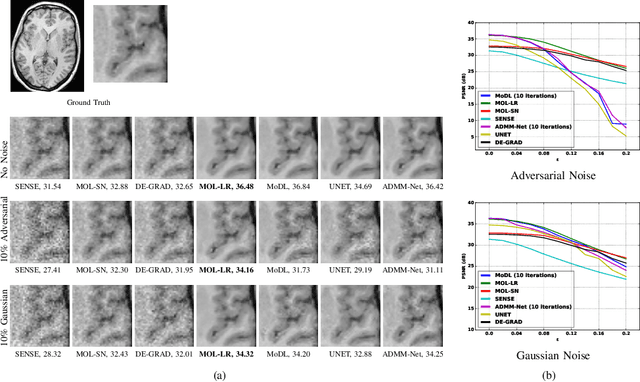
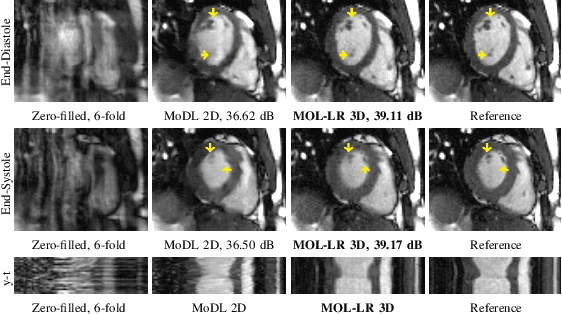
Model-based deep learning methods that combine imaging physics with learned regularization priors have been emerging as powerful tools for parallel MRI acceleration. The main focus of this paper is to determine the utility of the monotone operator learning (MOL) framework in the parallel MRI setting. The MOL algorithm alternates between a gradient descent step using a monotone convolutional neural network (CNN) and a conjugate gradient algorithm to encourage data consistency. The benefits of this approach include similar guarantees as compressive sensing algorithms including uniqueness, convergence, and stability, while being significantly more memory efficient than unrolled methods. We validate the proposed scheme by comparing it with different unrolled algorithms in the context of accelerated parallel MRI for static and dynamic settings.