 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Color Image Analysis Tool to Help Users Choose a Makeup Foundation Color
Jul 08, 2024



This paper presents an approach to predict the color of skin-with-foundation based on a no makeup selfie image and a foundation shade image. Our approach first calibrates the image with the help of the color checker target, and then trains a supervised-learning model to predict the skin color. In the calibration stage, We propose to use three different transformation matrices to map the device dependent RGB response to the reference CIE XYZ space. In so doing, color correction error can be minimized. We then compute the average value of the region of interest in the calibrated images, and feed them to the prediction model. We explored both the linear regression and support vector regression models. Cross-validation results show that both models can accurately make the prediction.
A Simple Strategy for Body Estimation from Partial-View Images
Apr 16, 2024
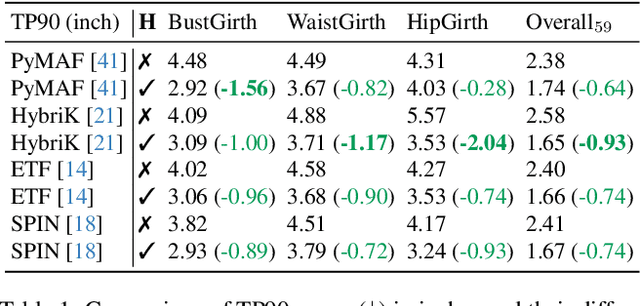
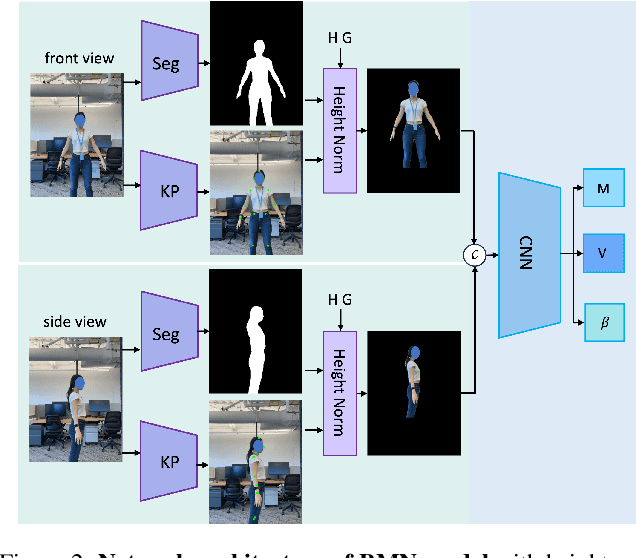
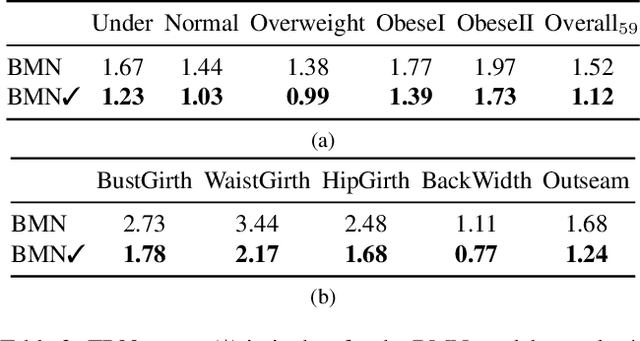
Virtual try-on and product personalization have become increasingly important in modern online shopping, highlighting the need for accurate body measurement estimation. Although previous research has advanced in estimating 3D body shapes from RGB images, the task is inherently ambiguous as the observed scale of human subjects in the images depends on two unknown factors: capture distance and body dimensions. This ambiguity is particularly pronounced in partial-view scenarios. To address this challenge, we propose a modular and simple height normalization solution. This solution relocates the subject skeleton to the desired position, thereby normalizing the scale and disentangling the relationship between the two variables. Our experimental results demonstrate that integrating this technique into state-of-the-art human mesh reconstruction models significantly enhances partial body measurement estimation. Additionally, we illustrate the applicability of this approach to multi-view settings, showcasing its versatility.
MRC-Net: 6-DoF Pose Estimation with MultiScale Residual Correlation
Mar 20, 2024We propose a single-shot approach to determining 6-DoF pose of an object with available 3D computer-aided design (CAD) model from a single RGB image. Our method, dubbed MRC-Net, comprises two stages. The first performs pose classification and renders the 3D object in the classified pose. The second stage performs regression to predict fine-grained residual pose within class. Connecting the two stages is a novel multi-scale residual correlation (MRC) layer that captures high-and-low level correspondences between the input image and rendering from first stage. MRC-Net employs a Siamese network with shared weights between both stages to learn embeddings for input and rendered images. To mitigate ambiguity when predicting discrete pose class labels on symmetric objects, we use soft probabilistic labels to define pose class in the first stage. We demonstrate state-of-the-art accuracy, outperforming all competing RGB-based methods on four challenging BOP benchmark datasets: T-LESS, LM-O, YCB-V, and ITODD. Our method is non-iterative and requires no complex post-processing.