 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtPro: Self-Supervised Articulated Object Reconstruction with Adaptive Integration of Mobility Proposals
Feb 26, 2026Reconstructing articulated objects into high-fidelity digital twins is crucial for applications such as robotic manipulation and interactive simulation. Recent self-supervised methods using differentiable rendering frameworks like 3D Gaussian Splatting remain highly sensitive to the initial part segmentation. Their reliance on heuristic clustering or pre-trained models often causes optimization to converge to local minima, especially for complex multi-part objects. To address these limitations, we propose ArtPro, a novel self-supervised framework that introduces adaptive integration of mobility proposals. Our approach begins with an over-segmentation initialization guided by geometry features and motion priors, generating part proposals with plausible motion hypotheses. During optimization, we dynamically merge these proposals by analyzing motion consistency among spatial neighbors, while a collision-aware motion pruning mechanism prevents erroneous kinematic estimation. Extensive experiments on both synthetic and real-world objects demonstrate that ArtPro achieves robust reconstruction of complex multi-part objects, significantly outperforming existing methods in accuracy and stability.
A Simple Strategy for Body Estimation from Partial-View Images
Apr 16, 2024
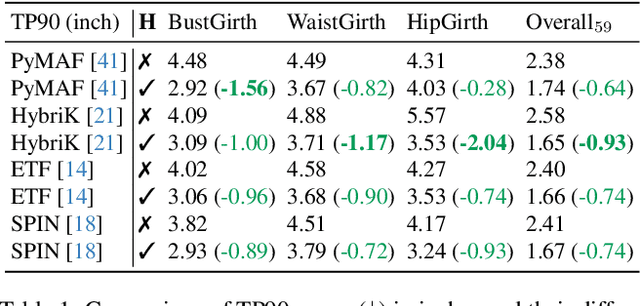
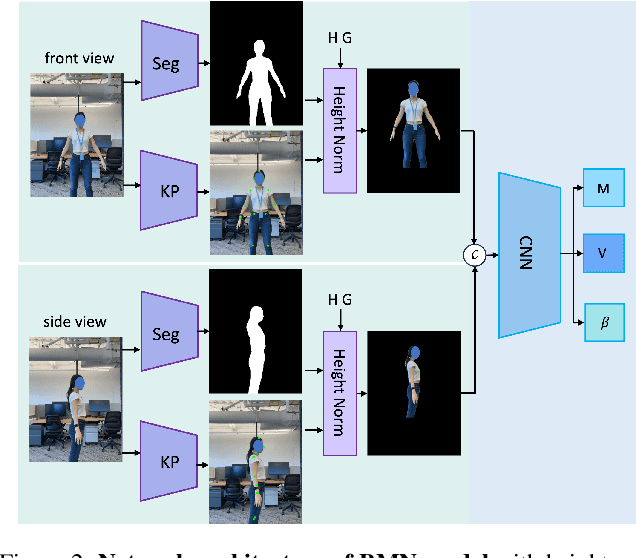
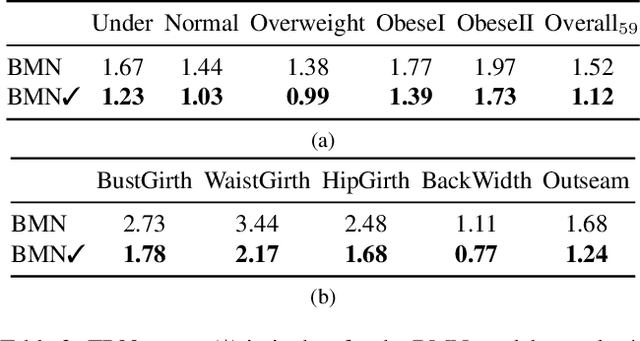
Virtual try-on and product personalization have become increasingly important in modern online shopping, highlighting the need for accurate body measurement estimation. Although previous research has advanced in estimating 3D body shapes from RGB images, the task is inherently ambiguous as the observed scale of human subjects in the images depends on two unknown factors: capture distance and body dimensions. This ambiguity is particularly pronounced in partial-view scenarios. To address this challenge, we propose a modular and simple height normalization solution. This solution relocates the subject skeleton to the desired position, thereby normalizing the scale and disentangling the relationship between the two variables. Our experimental results demonstrate that integrating this technique into state-of-the-art human mesh reconstruction models significantly enhances partial body measurement estimation. Additionally, we illustrate the applicability of this approach to multi-view settings, showcasing its versatility.
Maturity-Aware Active Learning for Semantic Segmentation with Hierarchically-Adaptive Sample Assessment
Aug 28, 2023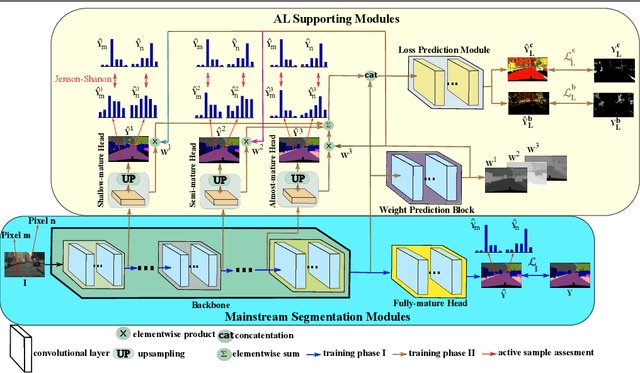
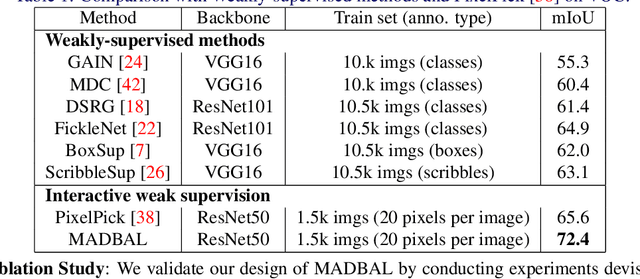
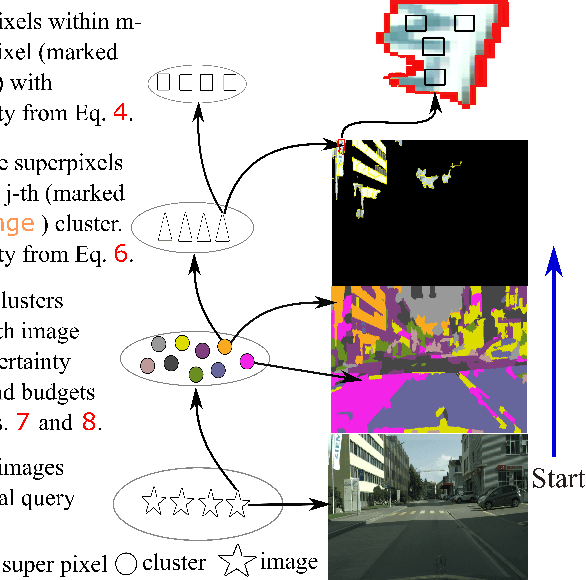
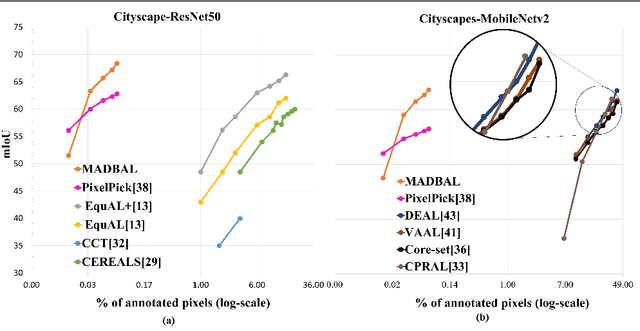
Active Learning (AL) for semantic segmentation is challenging due to heavy class imbalance and different ways of defining "sample" (pixels, areas, etc.), leaving the interpretation of the data distribution ambiguous. We propose "Maturity-Aware Distribution Breakdown-based Active Learning'' (MADBAL), an AL method that benefits from a hierarchical approach to define a multiview data distribution, which takes into account the different "sample" definitions jointly, hence able to select the most impactful segmentation pixels with comprehensive understanding. MADBAL also features a novel uncertainty formulation, where AL supporting modules are included to sense the features' maturity whose weighted influence continuously contributes to the uncertainty detection. In this way, MADBAL makes significant performance leaps even in the early AL stage, hence reducing the training burden significantly. It outperforms state-of-the-art methods on Cityscapes and PASCAL VOC datasets as verified in our extensive experiments.
NTIRE 2020 Challenge on NonHomogeneous Dehazing
May 07, 2020
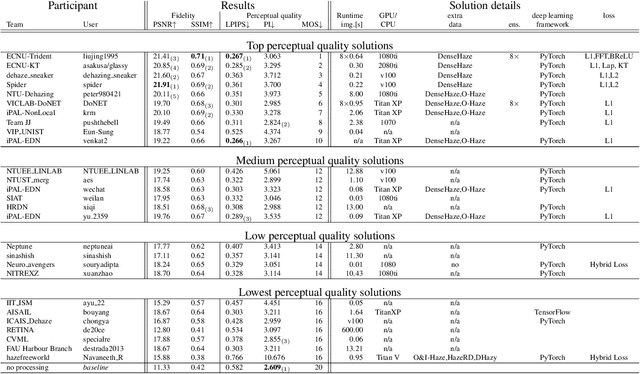
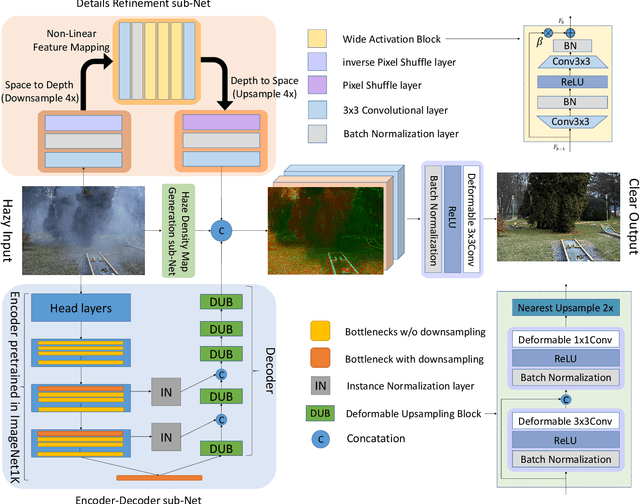
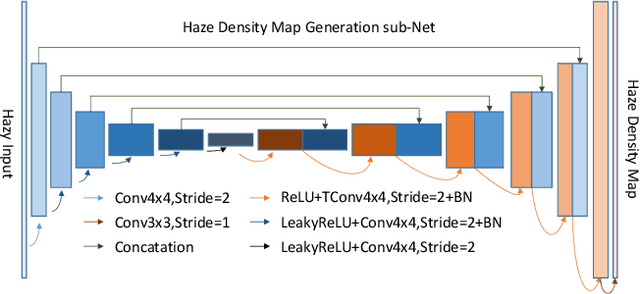
This paper reviews the NTIRE 2020 Challenge on NonHomogeneous Dehazing of images (restoration of rich details in hazy image). We focus on the proposed solutions and their results evaluated on NH-Haze, a novel dataset consisting of 55 pairs of real haze free and nonhomogeneous hazy images recorded outdoor. NH-Haze is the first realistic nonhomogeneous haze dataset that provides ground truth images. The nonhomogeneous haze has been produced using a professional haze generator that imitates the real conditions of haze scenes. 168 participants registered in the challenge and 27 teams competed in the final testing phase. The proposed solutions gauge the state-of-the-art in image dehazing.
Group Based Deep Shared Feature Learning for Fine-grained Image Classification
Apr 04, 2020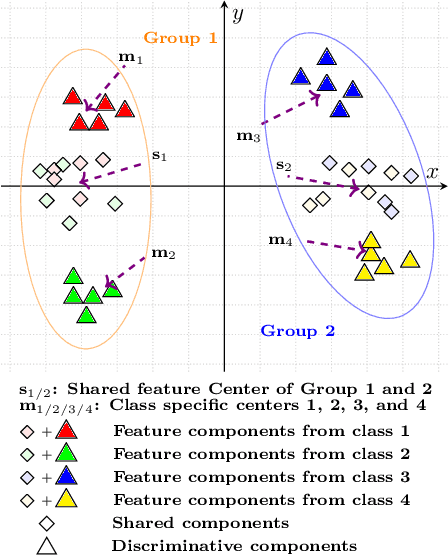
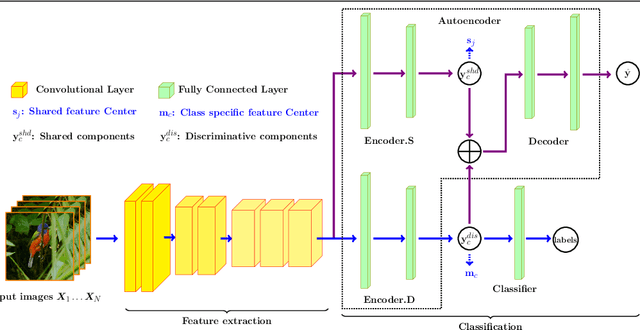


Fine-grained image classification has emerged as a significant challenge because objects in such images have small inter-class visual differences but with large variations in pose, lighting, and viewpoints, etc. Most existing work focuses on highly customized feature extraction via deep network architectures which have been shown to deliver state of the art performance. Given that images from distinct classes in fine-grained classification share significant features of interest, we present a new deep network architecture that explicitly models shared features and removes their effect to achieve enhanced classification results. Our modeling of shared features is based on a new group based learning wherein existing classes are divided into groups and multiple shared feature patterns are discovered (learned). We call this framework Group based deep Shared Feature Learning (GSFL) and the resulting learned network as GSFL-Net. Specifically, the proposed GSFL-Net develops a specially designed autoencoder which is constrained by a newly proposed Feature Expression Loss to decompose a set of features into their constituent shared and discriminative components. During inference, only the discriminative feature component is used to accomplish the classification task. A key benefit of our specialized autoencoder is that it is versatile and can be combined with state-of-the-art fine-grained feature extraction models and trained together with them to improve their performance directly. Experiments on benchmark datasets show that GSFL-Net can enhance classification accuracy over the state of the art with a more interpretable architecture.