 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep, convergent, unrolled half-quadratic splitting for image deconvolution
Feb 25, 2024



In recent years, algorithm unrolling has emerged as a powerful technique for designing interpretable neural networks based on iterative algorithms. Imaging inverse problems have particularly benefited from unrolling-based deep network design since many traditional model-based approaches rely on iterative optimization. Despite exciting progress, typical unrolling approaches heuristically design layer-specific convolution weights to improve performance. Crucially, convergence properties of the underlying iterative algorithm are lost once layer-specific parameters are learned from training data. We propose an unrolling technique that breaks the trade-off between retaining algorithm properties while simultaneously enhancing performance. We focus on image deblurring and unrolling the widely-applied Half-Quadratic Splitting (HQS) algorithm. We develop a new parametrization scheme which enforces layer-specific parameters to asymptotically approach certain fixed points. Through extensive experimental studies, we verify that our approach achieves competitive performance with state-of-the-art unrolled layer-specific learning and significantly improves over the traditional HQS algorithm. We further establish convergence of the proposed unrolled network as the number of layers approaches infinity, and characterize its convergence rate. Our experimental verification involves simulations that validate the analytical results as well as comparison with state-of-the-art non-blind deblurring techniques on benchmark datasets. The merits of the proposed convergent unrolled network are established over competing alternatives, especially in the regime of limited training.
Maturity-Aware Active Learning for Semantic Segmentation with Hierarchically-Adaptive Sample Assessment
Aug 28, 2023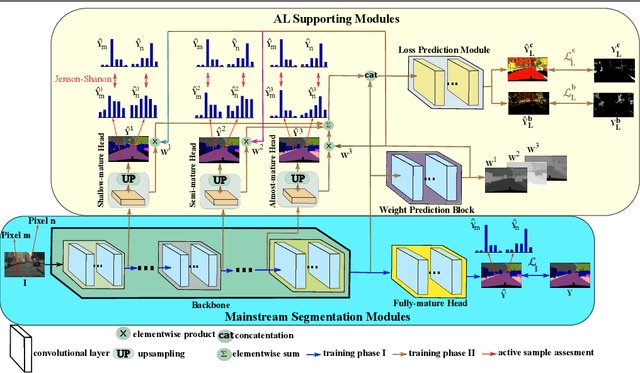
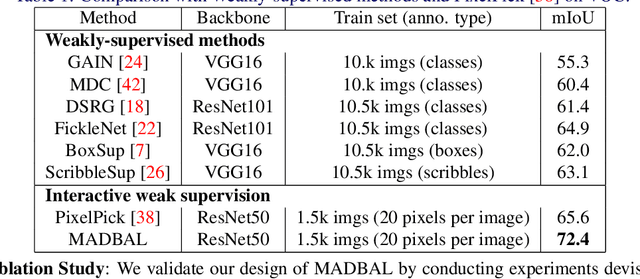
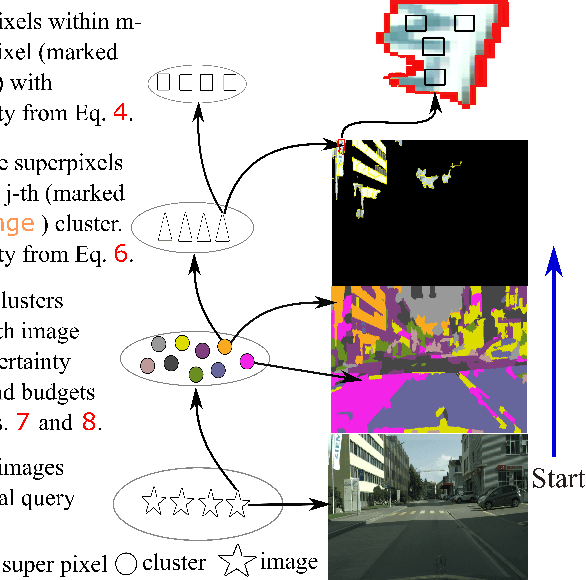
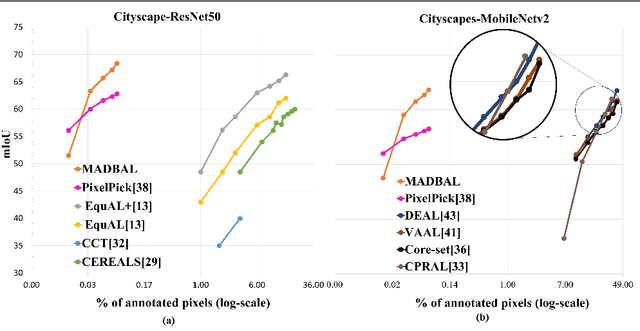
Active Learning (AL) for semantic segmentation is challenging due to heavy class imbalance and different ways of defining "sample" (pixels, areas, etc.), leaving the interpretation of the data distribution ambiguous. We propose "Maturity-Aware Distribution Breakdown-based Active Learning'' (MADBAL), an AL method that benefits from a hierarchical approach to define a multiview data distribution, which takes into account the different "sample" definitions jointly, hence able to select the most impactful segmentation pixels with comprehensive understanding. MADBAL also features a novel uncertainty formulation, where AL supporting modules are included to sense the features' maturity whose weighted influence continuously contributes to the uncertainty detection. In this way, MADBAL makes significant performance leaps even in the early AL stage, hence reducing the training burden significantly. It outperforms state-of-the-art methods on Cityscapes and PASCAL VOC datasets as verified in our extensive experiments.
Iterative, Deep Synthetic Aperture Sonar Image Segmentation
Mar 28, 2022
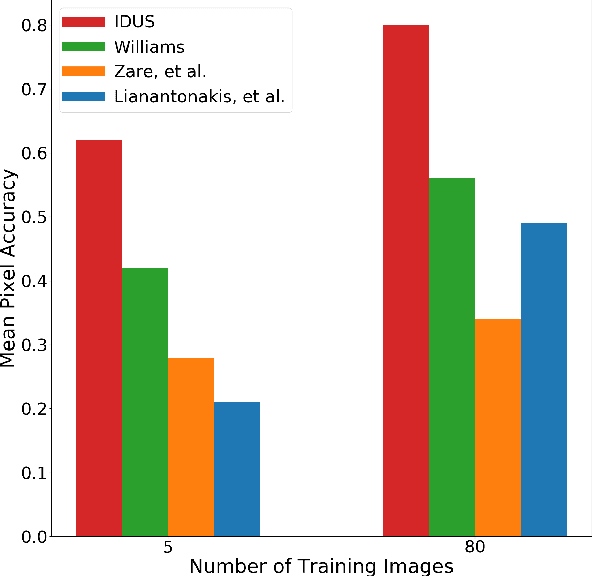
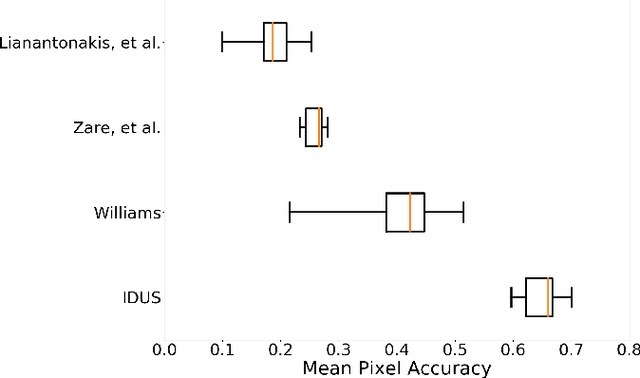
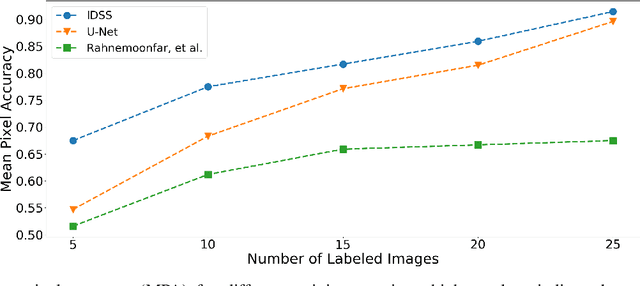
Synthetic aperture sonar (SAS) systems produce high-resolution images of the seabed environment. Moreover, deep learning has demonstrated superior ability in finding robust features for automating imagery analysis. However, the success of deep learning is conditioned on having lots of labeled training data, but obtaining generous pixel-level annotations of SAS imagery is often practically infeasible. This challenge has thus far limited the adoption of deep learning methods for SAS segmentation. Algorithms exist to segment SAS imagery in an unsupervised manner, but they lack the benefit of state-of-the-art learning methods and the results present significant room for improvement. In view of the above, we propose a new iterative algorithm for unsupervised SAS image segmentation combining superpixel formation, deep learning, and traditional clustering methods. We call our method Iterative Deep Unsupervised Segmentation (IDUS). IDUS is an unsupervised learning framework that can be divided into four main steps: 1) A deep network estimates class assignments. 2) Low-level image features from the deep network are clustered into superpixels. 3) Superpixels are clustered into class assignments (which we call pseudo-labels) using $k$-means. 4) Resulting pseudo-labels are used for loss backpropagation of the deep network prediction. These four steps are performed iteratively until convergence. A comparison of IDUS to current state-of-the-art methods on a realistic benchmark dataset for SAS image segmentation demonstrates the benefits of our proposal even as the IDUS incurs a much lower computational burden during inference (actual labeling of a test image). Finally, we also develop a semi-supervised (SS) extension of IDUS called IDSS and demonstrate experimentally that it can further enhance performance while outperforming supervised alternatives that exploit the same labeled training imagery.
Surface Defect Detection and Evaluation for Marine Vessels using Multi-Stage Deep Learning
Mar 17, 2022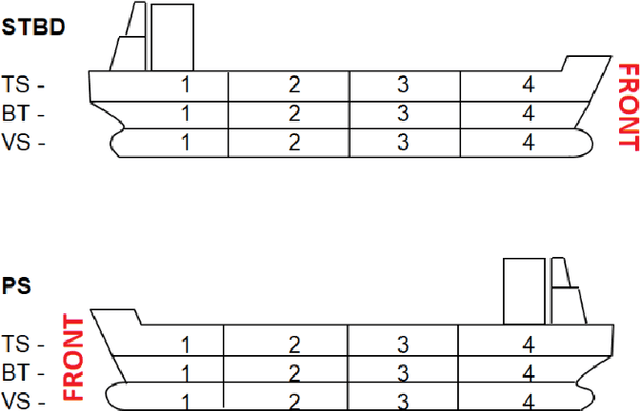



Detecting and evaluating surface coating defects is important for marine vessel maintenance. Currently, the assessment is carried out manually by qualified inspectors using international standards and their own experience. Automating the processes is highly challenging because of the high level of variation in vessel type, paint surface, coatings, lighting condition, weather condition, paint colors, areas of the vessel, and time in service. We present a novel deep learning-based pipeline to detect and evaluate the percentage of corrosion, fouling, and delamination on the vessel surface from normal photographs. We propose a multi-stage image processing framework, including ship section segmentation, defect segmentation, and defect classification, to automatically recognize different types of defects and measure the coverage percentage on the ship surface. Experimental results demonstrate that our proposed pipeline can objectively perform a similar assessment as a qualified inspector.
GlideNet: Global, Local and Intrinsic based Dense Embedding NETwork for Multi-category Attributes Prediction
Mar 14, 2022



Attaching attributes (such as color, shape, state, action) to object categories is an important computer vision problem. Attribute prediction has seen exciting recent progress and is often formulated as a multi-label classification problem. Yet significant challenges remain in: 1) predicting diverse attributes over multiple categories, 2) modeling attributes-category dependency, 3) capturing both global and local scene context, and 4) predicting attributes of objects with low pixel-count. To address these issues, we propose a novel multi-category attribute prediction deep architecture named GlideNet, which contains three distinct feature extractors. A global feature extractor recognizes what objects are present in a scene, whereas a local one focuses on the area surrounding the object of interest. Meanwhile, an intrinsic feature extractor uses an extension of standard convolution dubbed Informed Convolution to retrieve features of objects with low pixel-count. GlideNet uses gating mechanisms with binary masks and its self-learned category embedding to combine the dense embeddings. Collectively, the Global-Local-Intrinsic blocks comprehend the scene's global context while attending to the characteristics of the local object of interest. Finally, using the combined features, an interpreter predicts the attributes, and the length of the output is determined by the category, thereby removing unnecessary attributes. GlideNet can achieve compelling results on two recent and challenging datasets -- VAW and CAR -- for large-scale attribute prediction. For instance, it obtains more than 5\% gain over state of the art in the mean recall (mR) metric. GlideNet's advantages are especially apparent when predicting attributes of objects with low pixel counts as well as attributes that demand global context understanding. Finally, we show that GlideNet excels in training starved real-world scenarios.
CAR -- Cityscapes Attributes Recognition A Multi-category Attributes Dataset for Autonomous Vehicles
Nov 16, 2021



Self-driving vehicles are the future of transportation. With current advancements in this field, the world is getting closer to safe roads with almost zero probability of having accidents and eliminating human errors. However, there is still plenty of research and development necessary to reach a level of robustness. One important aspect is to understand a scene fully including all details. As some characteristics (attributes) of objects in a scene (drivers' behavior for instance) could be imperative for correct decision making. However, current algorithms suffer from low-quality datasets with such rich attributes. Therefore, in this paper, we present a new dataset for attributes recognition -- Cityscapes Attributes Recognition (CAR). The new dataset extends the well-known dataset Cityscapes by adding an additional yet important annotation layer of attributes of objects in each image. Currently, we have annotated more than 32k instances of various categories (Vehicles, Pedestrians, etc.). The dataset has a structured and tailored taxonomy where each category has its own set of possible attributes. The tailored taxonomy focuses on attributes that is of most beneficent for developing better self-driving algorithms that depend on accurate computer vision and scene comprehension. We have also created an API for the dataset to ease the usage of CAR. The API can be accessed through https://github.com/kareem-metwaly/CAR-API.
Deep Algorithm Unrolling for Biomedical Imaging
Aug 15, 2021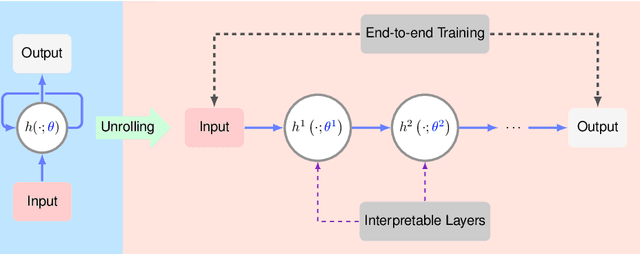
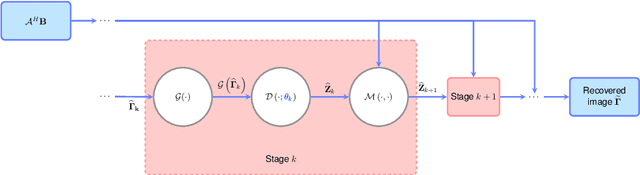
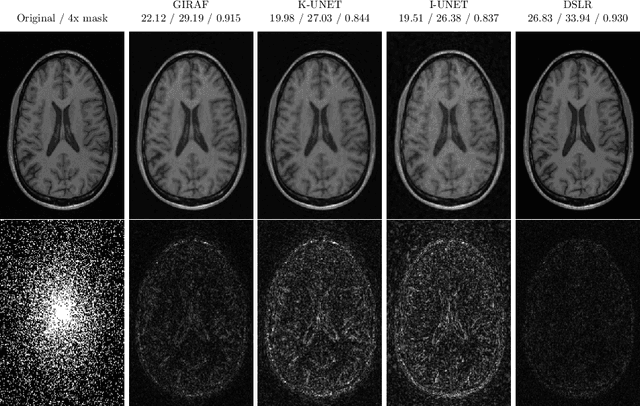
In this chapter, we review biomedical applications and breakthroughs via leveraging algorithm unrolling, an important technique that bridges between traditional iterative algorithms and modern deep learning techniques. To provide context, we start by tracing the origin of algorithm unrolling and providing a comprehensive tutorial on how to unroll iterative algorithms into deep networks. We then extensively cover algorithm unrolling in a wide variety of biomedical imaging modalities and delve into several representative recent works in detail. Indeed, there is a rich history of iterative algorithms for biomedical image synthesis, which makes the field ripe for unrolling techniques. In addition, we put algorithm unrolling into a broad perspective, in order to understand why it is particularly effective and discuss recent trends. Finally, we conclude the chapter by discussing open challenges, and suggesting future research directions.
Iterative, Deep, and Unsupervised Synthetic Aperture Sonar Image Segmentation
Jul 30, 2021
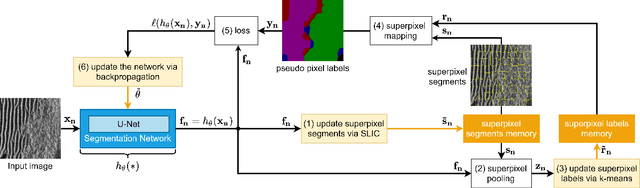

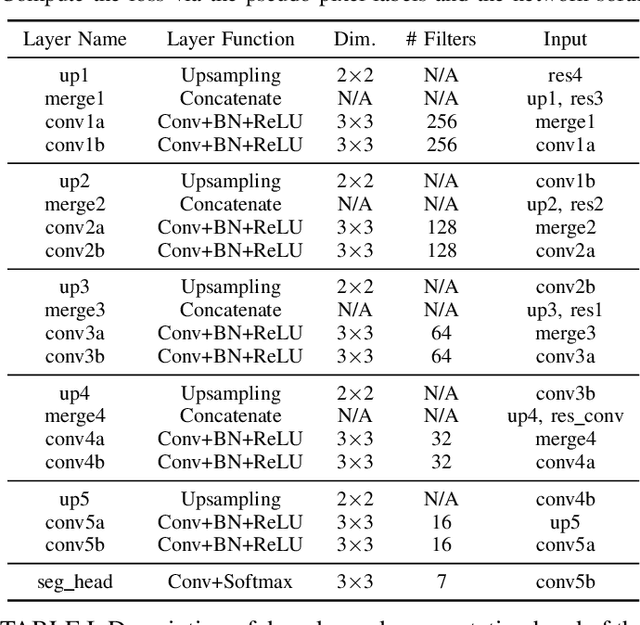
Deep learning has not been routinely employed for semantic segmentation of seabed environment for synthetic aperture sonar (SAS) imagery due to the implicit need of abundant training data such methods necessitate. Abundant training data, specifically pixel-level labels for all images, is usually not available for SAS imagery due to the complex logistics (e.g., diver survey, chase boat, precision position information) needed for obtaining accurate ground-truth. Many hand-crafted feature based algorithms have been proposed to segment SAS in an unsupervised fashion. However, there is still room for improvement as the feature extraction step of these methods is fixed. In this work, we present a new iterative unsupervised algorithm for learning deep features for SAS image segmentation. Our proposed algorithm alternates between clustering superpixels and updating the parameters of a convolutional neural network (CNN) so that the feature extraction for image segmentation can be optimized. We demonstrate the efficacy of our method on a realistic benchmark dataset. Our results show that the performance of our proposed method is considerably better than current state-of-the-art methods in SAS image segmentation.
Physically Inspired Dense Fusion Networks for Relighting
May 05, 2021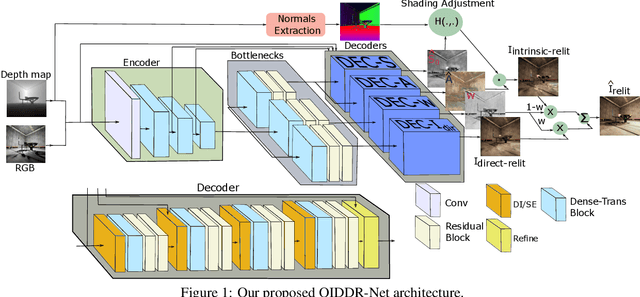

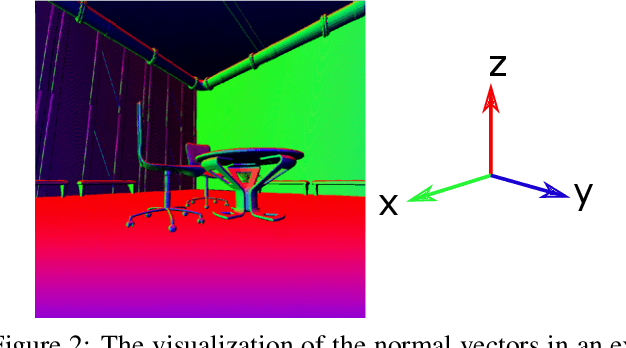

Image relighting has emerged as a problem of significant research interest inspired by augmented reality applications. Physics-based traditional methods, as well as black box deep learning models, have been developed. The existing deep networks have exploited training to achieve a new state of the art; however, they may perform poorly when training is limited or does not represent problem phenomenology, such as the addition or removal of dense shadows. We propose a model which enriches neural networks with physical insight. More precisely, our method generates the relighted image with new illumination settings via two different strategies and subsequently fuses them using a weight map (w). In the first strategy, our model predicts the material reflectance parameters (albedo) and illumination/geometry parameters of the scene (shading) for the relit image (we refer to this strategy as intrinsic image decomposition (IID)). The second strategy is solely based on the black box approach, where the model optimizes its weights based on the ground-truth images and the loss terms in the training stage and generates the relit output directly (we refer to this strategy as direct). While our proposed method applies to both one-to-one and any-to-any relighting problems, for each case we introduce problem-specific components that enrich the model performance: 1) For one-to-one relighting we incorporate normal vectors of the surfaces in the scene to adjust gloss and shadows accordingly in the image. 2) For any-to-any relighting, we propose an additional multiscale block to the architecture to enhance feature extraction. Experimental results on the VIDIT 2020 and the VIDIT 2021 dataset (used in the NTIRE 2021 relighting challenge) reveals that our proposal can outperform many state-of-the-art methods in terms of well-known fidelity metrics and perceptual loss.
Simultaneous Denoising and Localization Network for Photoacoustic Target Localization
Apr 30, 2021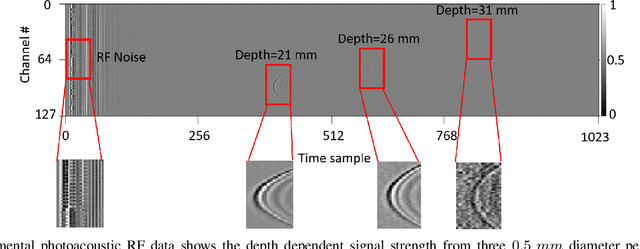
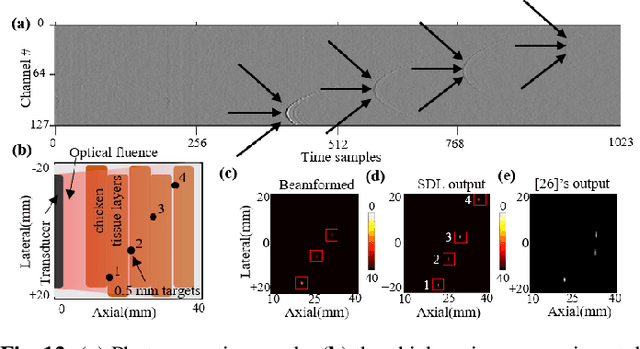
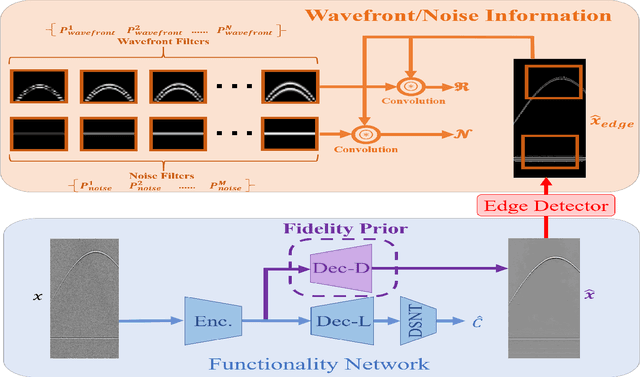
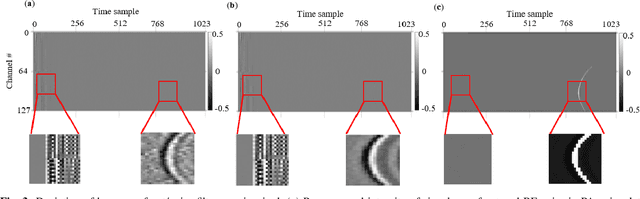
A significant research problem of recent interest is the localization of targets like vessels, surgical needles, and tumors in photoacoustic (PA) images. To achieve accurate localization, a high photoacoustic signal-to-noise ratio (SNR) is required. However, this is not guaranteed for deep targets, as optical scattering causes an exponential decay in optical fluence with respect to tissue depth. To address this, we develop a novel deep learning method designed to explicitly exhibit robustness to noise present in photoacoustic radio-frequency (RF) data. More precisely, we describe and evaluate a deep neural network architecture consisting of a shared encoder and two parallel decoders. One decoder extracts the target coordinates from the input RF data while the other boosts the SNR and estimates clean RF data. The joint optimization of the shared encoder and dual decoders lends significant noise robustness to the features extracted by the encoder, which in turn enables the network to contain detailed information about deep targets that may be obscured by noise. Additional custom layers and newly proposed regularizers in the training loss function (designed based on observed RF data signal and noise behavior) serve to increase the SNR in the cleaned RF output and improve model performance. To account for depth-dependent strong optical scattering, our network was trained with simulated photoacoustic datasets of targets embedded at different depths inside tissue media of different scattering levels. The network trained on this novel dataset accurately locates targets in experimental PA data that is clinically relevant with respect to the localization of vessels, needles, or brachytherapy seeds. We verify the merits of the proposed architecture by outperforming the state of the art on both simulated and experimental datasets.